Etcd集群的搭建以及分析
什么是etcd?
etcd 是一个高可用强一致性的服务发现存储仓库
在云计算时代,如何让服务快速透明地接入到计算集群中,如何让共享配置信息快速被集群中的所有机器发现,更为重要的是,如何构建这样一套高可用、安全、易于部署以及响应快速的服务集群,已经成为了迫切需要解决的问题。etcd 为解决这类问题带来了福音
etcd的架构
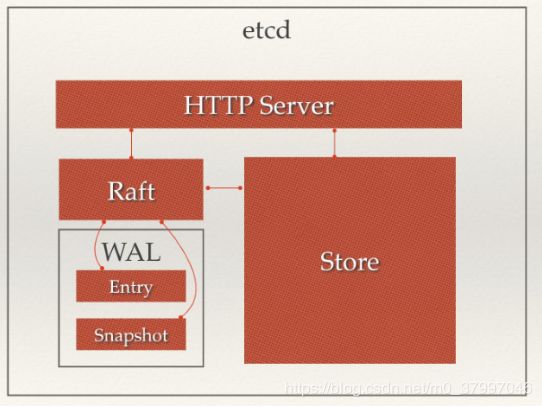
从 etcd 的架构图中我们可以看到,etcd 主要分为四个部分。
- HTTP Server: 用于处理用户发送的 API 请求以及其它 etcd 节点的同步与心跳信息请求。
- Store:用于处理 etcd 支持的各类功能的事务,包括数据索引、节点状态变更、监控与反馈、事件处理与执行等等,是 etcd 对用户提供的大多数 API 功能的具体实现。
- Raft:Raft 强一致性算法的具体实现,是 etcd 的核心。
- WAL:Write Ahead Log(预写式日志),是 etcd 的数据存储方式。除了在内存中存有所有数据的状态以及节点的索引以外,etcd 就通过 WAL 进行持久化存储。WAL 中,所有的数据提交前都会事先记录日志。Snapshot 是为了防止数据过多而进行的状态快照;Entry 表示存储的具体日志内容。
流程分析
一个用户的请求发送过来,会经由 HTTP Server 转发给 Store 进行具体的事务处理,如果涉及到节点的修改,则交给 Raft 模块进行状态的变更、日志的记录,然后再同步给别的 etcd 节点以确认数据提交,最后进行数据的提交,再次同步。
如何搭建etcd集群
etcd集群的搭建方式有三种,这里就第一种进行举例,详细的参看下面网址
网址链接:https://mritd.me/2016/09/01/Etcd-集群搭建/
静态发现: 预先已知 Etcd 集群中有哪些节点,在启动时直接指定好 Etcd 的各个 node 节点地址
Etcd 动态发现: 通过已有的 Etcd 集群作为数据交互点,然后在扩展新的集群时实现通过已有集群进行服务发现的机制
DNS 动态发现: 通过 DNS 查询方式获取其他节点地址信息
1 环境准备
节点 IP
etcd0 192.168.194.148
etcd1 192.168.194.144
2 修改主机名(以etcd0为例,etcd2同理)
hostnamectl set-hostname etcd0
3 vi /etc/hosts
192.168.194.148 etcd0
192.168.194.144 etcd1
4 关闭防火墙
systemctl stop firewalld
setenforce 0
5 修改etcd配置文件
vi /etc/etcd/etcd.conf
#[Member]
#ETCD_CORS=""
ETCD_DATA_DIR="/var/lib/etcd/etcd0"
#ETCD_WAL_DIR=""
ETCD_LISTEN_PEER_URLS=“http://0.0.0.0:2380”
ETCD_LISTEN_CLIENT_URLS=“http://0.0.0.0:2379,http://0.0.0.0:4001”
#ETCD_MAX_SNAPSHOTS=“5”
#ETCD_MAX_WALS=“5”
ETCD_NAME=“etcd0”
#ETCD_SNAPSHOT_COUNT=“100000”
#ETCD_HEARTBEAT_INTERVAL=“100”
#ETCD_ELECTION_TIMEOUT=“1000”
#ETCD_QUOTA_BACKEND_BYTES=“0”
#ETCD_MAX_REQUEST_BYTES=“1572864”
#ETCD_GRPC_KEEPALIVE_MIN_TIME=“5s”
#ETCD_GRPC_KEEPALIVE_INTERVAL=“2h0m0s”
#ETCD_GRPC_KEEPALIVE_TIMEOUT=“20s”
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS=“192.168.194.148:2380”
ETCD_ADVERTISE_CLIENT_URLS=“http://192.168.194.148:2379,http://192.168.194.148:4001”
#ETCD_DISCOVERY=""
#ETCD_DISCOVERY_FALLBACK=“proxy”
#ETCD_DISCOVERY_PROXY=""
#ETCD_DISCOVERY_SRV=""
===ETCD_INITIAL_CLUSTER=“etcd0=http://192.168.194.148:2380,etcd1=http://192.168.194.144:2380” ===
ETCD_INITIAL_CLUSTER_TOKEN=“mritd-etcd-cluster”
ETCD_INITIAL_CLUSTER_STATE=“new”
#ETCD_STRICT_RECONFIG_CHECK=“true”
#ETCD_ENABLE_V2=“true”
6 开启服务
systemctl start etcd
7 查看集群节点
[root@etcd0 ~]# etcdctl member list
862fcca67d8a6028: name=etcd1 peerURLs=http://192.168.194.144:2380 clientURLs=http://192.168.194.144:2379,http://192.168.194.144:4001 isLeader=false
afe6bafc65165762: name=etcd0 peerURLs=http://192.168.194.148:2380 clientURLs=http://192.168.194.148:2379,http://192.168.194.148:4001 isLeader=true
8 查看集群状况
[root@etcd0 ~]# etcdctl cluster-health
member 862fcca67d8a6028 is healthy: got healthy result from http://192.168.194.144:2379
member afe6bafc65165762 is healthy: got healthy result from http://192.168.194.148:2379
cluster is healthy
采用命令方式创建
etcd -name infra0
-initial-advertise-peer-urls http://10.0.1.10:2380
-listen-peer-urls http://10.0.1.10:2380
-initial-cluster-token etcd-cluster-1
-initial-cluster infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380
-initial-cluster-state new
参数分析
-name 节点名称
-initial-advertise-peer-urls 通知其他 Etcd 实例地址
-listen-peer-urls 监听其他 Etcd 实例的地址
-initial-cluster-token 初始化集群 token
-initial-cluster 初始化集群内节点地址
-initial-cluster-state 初始化集群状态,new 表示新建
etcd的应用
服务发现
服务发现要解决的也是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务,要如何才能找到对方并建立连接。本质上来说,服务发现就是想要了解集群中是否有进程在监听 udp 或 tcp 端口,并且通过名字就可以查找和连接。要解决服务发现的问题,需要有下面三大支柱
- 一个强一致性、高可用的服务存储目录。基于 Raft 算法的 etcd 天生就是这样一个强一致性高可用的服务存储目录。
- 一种注册服务和监控服务健康状态的机制。用户可以在 etcd 中注册服务,并且对注册的服务设置key TTL,定时保持服务的心跳以达到监控健康状态的效果。
- 一种查找和连接服务的机制。通过在 etcd 指定的主题下注册的服务也能在对应的主题下查找到。为了确保连接,我们可以在每个服务机器上都部署一个 Proxy 模式的 etcd,这样就可以确保能访问 etcd 集群的服务都能互相连接。
具体分析
随着 Docker 容器的流行,多种微服务共同协作,构成一个相对功能强大的架构的案例越来越多。透明化的动态添加这些服务的需求也日益强烈。通过服务发现机制,在 etcd 中注册某个服务名字的目录,在该目录下存储可用的服务节点的 IP。在使用服务的过程中,只要从服务目录下查找可用的服务节点去使用即可。

PaaS 平台中的应用一般都有多个实例,通过域名,不仅可以透明的对这多个实例进行访问,而且还可以做到负载均衡。但是应用的某个实例随时都有可能故障重启,这时就需要动态的配置域名解析(路由)中的信息。通过 etcd 的服务发现功能就可以轻松解决这个动态配置的问题。
运行时节点变更
etcd 集群启动完毕后,可以在运行的过程中对集群进行重构,包括核心节点的增加、删除、迁移、替换
注意:
只有当集群中多数节点正常的情况下,你才可以进行运行时的配置管理。因为配置更改的信息也会被 etcd 当成一个信息存储和同步,如果集群多数节点损坏,集群就失去了写入数据的能力。所以在配置 etcd 集群数量时,强烈推荐至少配置 3 个核心节点。
一 节点的迁移,替换
当你节点所在的机器出现硬件故障,或者节点出现如数据目录损坏等问题,导致节点永久性的不可恢复时,就需要对节点进行迁移或者替换。当一个节点失效以后,必须尽快修复,因为 etcd 集群正常运行的必要条件是集群中多数节点都正常工作。
迁移一个节点需要进行四步操作:
暂停正在运行着的节点程序进程
把数据目录从现有机器拷贝到新机器
使用 api 更新 etcd 中对应节点指向机器的 url 记录更新为新机器的 ip
使用同样的配置项和数据目录,在新的机器上启动 etcd。
二 节点的增加
增加节点可以让 etcd 的高可用性更强。举例来说,如果你有 3 个节点,那么最多允许 1 个节点失效;当你有 5 个节点时,就可以允许有 2 个节点失效。同时,增加节点还可以让 etcd 集群具有更好的读性能。因为 etcd 的节点都是实时同步的,每个节点上都存储了所有的信息,所以增加节点可以从整体上提升读的吞吐量。
增加一个节点需要进行两步操作:
在集群中添加这个节点的 url 记录,同时获得集群的信息。
使用获得的集群信息启动新 etcd 节点。
三 节点的移除
有时你不得不在提高 etcd 的写性能和增加集群高可用性上进行权衡。Leader 节点在提交一个写记录时,会把这个消息同步到每个节点上,当得到多数节点的同意反馈后,才会真正写入数据。所以节点越多,写入性能越差。在节点过多时,你可能需要移除一个或多个。
移除节点非常简单,只需要一步操作,就是把集群中这个节点的记录删除。然后对应机器上的该节点就会自动停止。
四 强制性重启集群
当集群超过半数的节点都失效时,就需要通过手动的方式,强制性让某个节点以自己为 Leader,利用原有数据启动一个新集群。
此时你需要进行两步操作。
备份原有数据到新机器。
使用-force-new-cluster加备份的数据重新启动节点
注意:强制性重启是一个迫不得已的选择,它会破坏一致性协议保证的安全性(如果操作时集群中尚有其它节点在正常工作,就会出错),所以在操作前请务必要保存好数据。
Proxy模式
Proxy 模式也是新版 etcd 的一个重要变更,etcd 作为一个反向代理把客户的请求转发给可用的 etcd 集群。这样,你就可以在每一台机器都部署一个 Proxy 模式的 etcd 作为本地服务,如果这些 etcd Proxy 都能正常运行,那么你的服务发现必然是稳定可靠的。

那么,为什么要有 Proxy 模式而不是直接增加 etcd 核心节点呢?实际上 etcd 每增加一个核心节点(peer),都会增加 Leader 节点一定程度的包括网络、CPU 和磁盘的负担,因为每次信息的变化都需要进行同步备份。增加 etcd 的核心节点可以让整个集群具有更高的可靠性,但是当数量达到一定程度以后,增加可靠性带来的好处就变得不那么明显,反倒是降低了集群写入同步的性能。因此,增加一个轻量级的 Proxy 模式 etcd 节点是对直接增加 etcd 核心节点的一个有效代替。
Proxy 模式的本质就是起一个 HTTP 代理服务器,把客户发到这个服务器的请求转发给别的 etcd 节点。
简单命令
查看store的状态
curl http://127.0.0.1:2379/v2/stats/store
查看自己的状态
curl http://127.0.0.1:2379/v2/stats/self
查看leader状态
curl http://127.0.0.1:2379/v2/stats/leader
指定某个键的值
etcdctl set /testdir/testkey “Hello world”
获取指定键的值(当建不存在事会报错)
etcdctl get /testdir/testkey
当键存在时,更新值内容
etcdctl update /testdir/testkey “Hello”
移除某个键值
etcdctl rm /testdir/testkey
mk
如果给定的键不存在,则创建一个新的键值
etcdctl mk /testdir/testkey “Hello world”
当键存在的时候,执行该命令会报错
etcdctl mk /testdir/testkey “Hello world”
mkdir
如果给定的键目录不存在,则创建一个新的键目录,当键目录存在的时候,执行该命令会报错
etcdctl mkdir testdir2
setdir
创建一个键目录,无论存在与否。
etcdctl setdir testdir2
updatedir
更新一个已经存在的目录
etcdctl updatedir testdir2
rmdir
删除一个空目录,或者键值对。
etcdctl rmdir dir1
ls
etcdctl ls dir
etcdctl ls