一、hadoop2.x版本的集群安装
个人安装的是centos6.5,hadoop2.9.0。
准备两台虚拟机,一台作为主节点master,一台作为从节点slave1。
1、关闭防火墙,禁用selinux
# service iptables status # 查看防火墙状态
# service iptables stope # 若开启,则关闭
# vim /etc/sysconfig/selinux # 修改SELINUX=disabled
2、网络配置
1)确保VMnet8网卡已开启
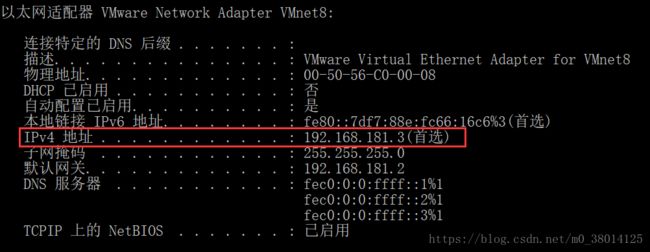
首先确保虚拟网卡(VMware Network Adapter VMnet8)是开启的,然后在windows的命令行里输入“ipconfig /all”,找到VMware Network Adapter VMnet8的ipv4地址(例如:192.168.10.1),如下图:
2)查看网关:
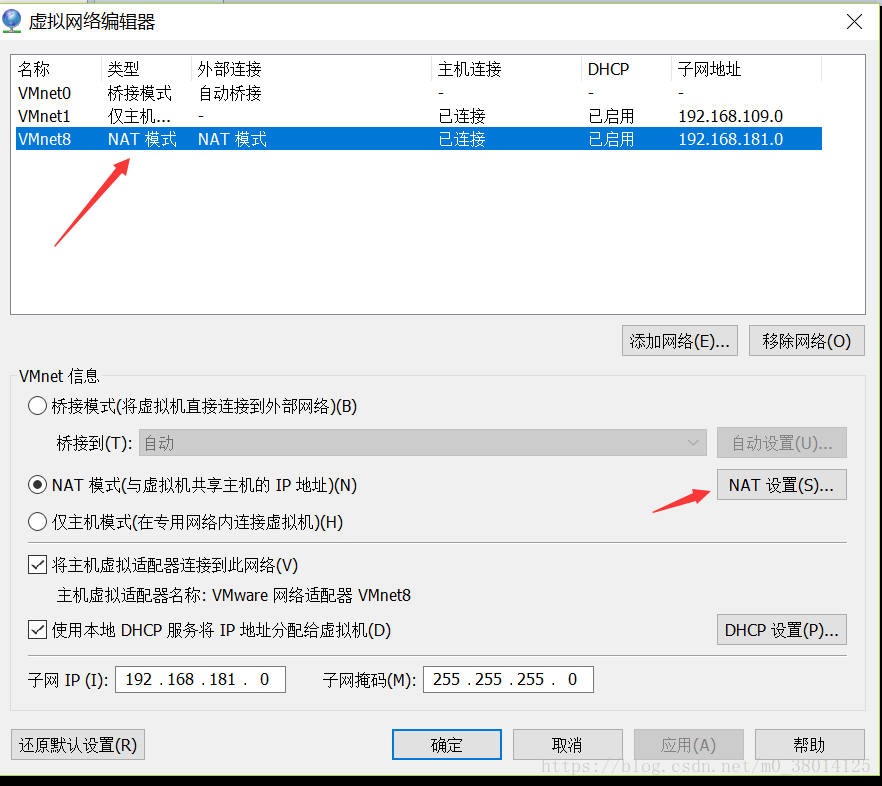
打开vmware,编辑——虚拟网络


3)查看网卡名称:
vim /etc/udev/rules.d/70-persistent-net.rules

我的网卡名称为eth1。
4)设置网络
vim /etc/sysconfig/network-scripts/ifcfg-eth0

5)生效设置,重启网卡,service network restart或者/etc/init.d/network restart
3、创建用户hadoop 并设置密码
# useradd -m hadoop -s /bin/bash #创建新用户hadoop
# passwd hadoop
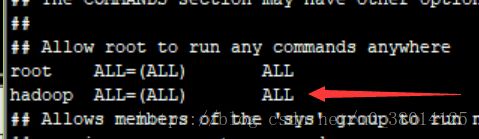
# visudo #为用户增加管理员权限【:91】(91行左右)
4、修改主机名称
# vim /etc/sysconfig/network

重启生效,# reboot
5、ip和hostname绑定

这里我只配置了一个从节点。
$ ping 主机名 # 验证是否相通
从节点的网络环境同理配置好。
6、ssh免密登录从节点(所有守护进程通过ssh协议通信)
1)$ ssh localhost # 执行该命令,会在~/生成.ssh目录(如果没有的情况下)
$ cd ~/.ssh
$ rm ./id_rsa* # 如果有,删除之前的公钥
$ ssh-keygen -t rsa # 一直回车
$ cat ./id_rsa.pub >> ./authorized_keys # 加入授权
$ chmod 600 ./authorized_keys # 修改文件权限
$ ssh localhost # 测试,可无密码登录了
$ exit # 退出刚刚登录的客户端
$ scp ~/.ssh/id_rsa.pub hadoop@slave1:/home/hadoop # 传输master的公钥到各个从节点
2)从节点slave1上,将ssh公钥加入授权
$ mkdir ~/.ssh # 如果不存在文件夹需先创建,若已存在则忽略
$ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
$ rm ~/id_rsa.pub # 用完就可以删了
3)在主节点上执行,$ ssh slave1

$ exit # 退出登录
7、安装jdk
1)卸载自带openjdk
# rpm -qa | grep java # 查询操作系统自身安装的java
# rpm -e --nodeps 文件名 # 若有,即分别卸载它们
2)下载解压jdk
$ sudo yum install java-1.7.0-openjdk java-1.7.0-openjdk-devel # 安装过程中输入y
默认安装路径/usr/lib/jvm/java-1.7.0-openjdk,可通过$ rpm -ql java-1.7.0-openjdk-devel | grep '/bin/javac' 查看(出去路径末尾的‘/bin/javac’)
3)配置jdk环境变量,我配置的是当前用户有效的,在~/.bashrc中, 添加 export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.171-2.6.13.0.el7_4.x86_64,即
$ vim ~/.bashrc
添加 export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.171-2.6.13.0.el7_4.x86_64 并保存生效,
$ source ~/.bashrc
4)检验jdk配置
$ echo $JAVA_HOME # 检验变量值
$ java -version
$ $JAVA_HOME/bin/java -version # 与直接执行java -version一样,配置正确
8、hadoop-2.9.0安装
1)下载hadoop-2.9.0.tar.gz上传到~/Downloads/
$ sudo tar -zxf ~/Downloads/hadoop-2.9.0.tar.gz -C /usr/local # 解压到/uar/local中
$ cd /usr/local/
2)使用hadoop用户在hadoop-2.9.0目录下创建tmp、name和data目录,保证目录所有者为hadoop
$ mkdir tmp
$ mkdir name
$ mkdir data
$ sudo chown -R hadoop:hadoop ./hadoop-2.9.0 # 修改文件权限,确保目录所有者为hadoop

9、配置环境变量/etc/profile并设置生效
# vim /etc/profile
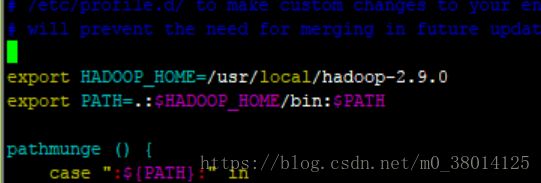
添加如下路径:
export HADOOP_HOME=/usr/local/hadoop-2.9.0
export PATH=.:$HADOOP_HOME/bin:$PATH
保存生效,# source /etc/profile
10、进入hadoop安装目录下etc/hadoop下,修改配置文件
$ cd etc/hadoop
1)$ vim hadoop-env.sh,在最后添加
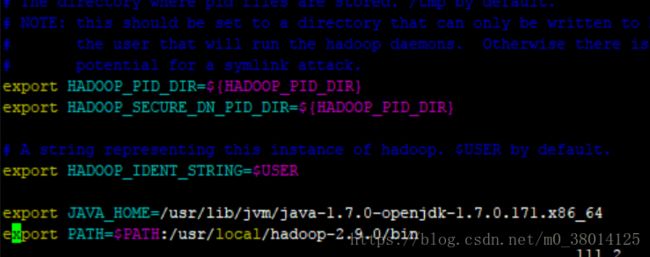
编译确认生效,
$ source hadoop-env.sh
$ hadoop version # 显示版本信息
2) $ vim yarn-env.sh,添加JAVA_HOME
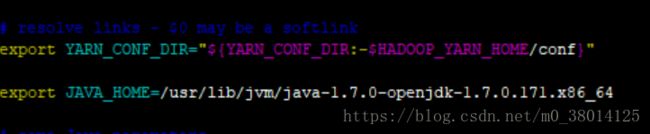
编译确认生效,
$ source yarn-env.sh
3)$ vim core-site.xml,添加配置
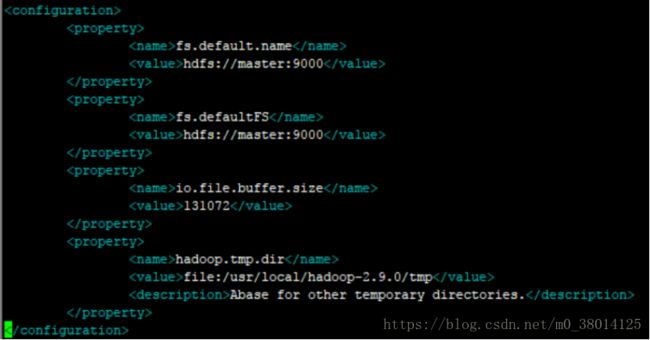
4)$ vim hdfs-site.xml,dfs.replication一般设为3(副本数),这里我只配一个节点,设为1;
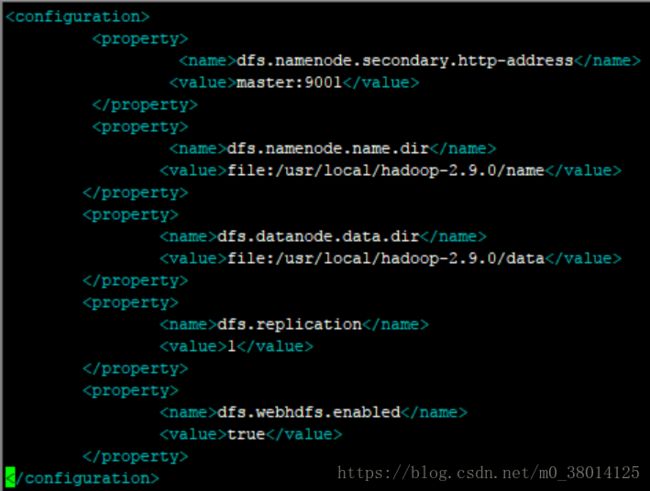
5)$ vim mapred-site.xml(默认文件名为mapred-site.xml.template,可先重命名);

6)$ vim yarn-site.xml,

7)$ vim slaves # 配置从节点
11、向各节点分发hadoop程序
1)在从节点创建/usr/local/hadoop-2.9.0并执行$ chown -R hadoop hadoop-2.9.0
2)在主节点hadoop目录,/usr/local/hadoop-2.9.0下,执行:
$ scp -r * hadoop@slave1:/usr/local/hadoop-2.9.0
3)在从节点hadoop目录下查看是否复制成功, $ ls
4)在主节点hadoop目录下,格式化namenode:
$ ./bin/hdfs namenode -format
5)启动hdfs:
$ cd sbin
$ ./start-dfs.sh # 这里我启动报错了,在后面贴出来
验证当前进行jps:
master上运行的进程有namenode,secondarynamenode
slave1上运行进程有datanode
6)启动yarn:
./start-yarn.sh
验证当前进行:
master上有:namenode,secondarynamenode,resourcemanager
slave1上有datanode,nodemanager
12、报错Error:cannot find configuration directory:/etc/hadoop
我在第11步中第5)步启动hdfs报错了:
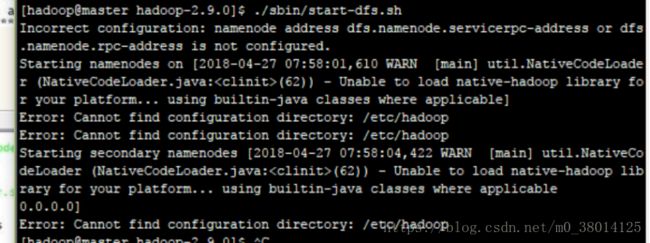
解决:
修改hadoop-env.sh中的 HADOOP_CONF_DIR路径,
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
改为绝对路径
export HADOOP_CONF_DIR=/usr/local/hadoop-2.9.0/etc/hadoop
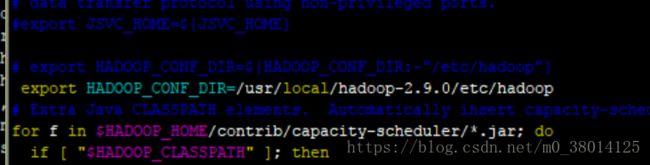
保存退出,记得$ source hadoop-env.sh,确认生效。
拷贝到从节点,$ scp hadoop-env.sh hadoop@slave1:/usr/local/hadoop-2.9.0/etc/hadoop。
主节点重新执行11步中4)之后的步骤,启动成功。
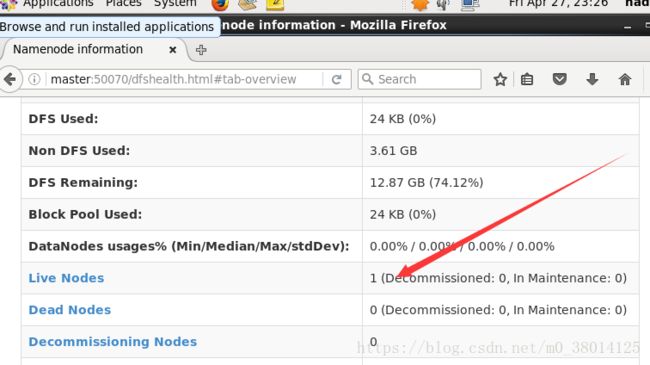
13、浏览器访问
http://master:50070
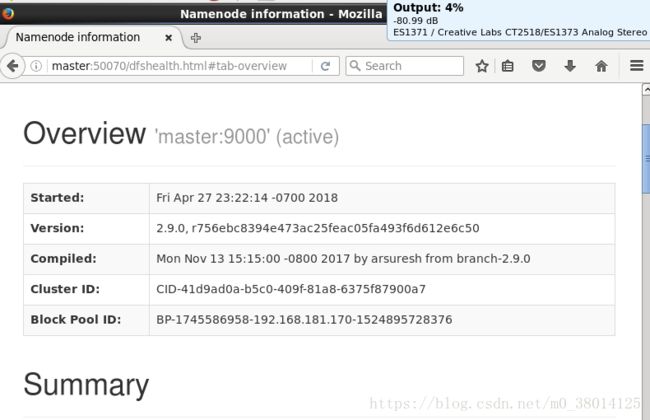
http://master:8088

注:
可以将hadoop命令的相关目录加入到PATH环境变量中,这样就可以直接通过start-dfs.sh开启hadoop,也可以直接通过hdfs访问hdfs的内容方便平时的操作。
选择在~/.bashrc中进行设置,在文件中加入
export PATH=$PATH:/usr/local/hadoop-2.9.0/sbin:/usr/local/hadoop-2.9.0/bin
保存执行:source ~/.bashrc,使设置生效,生效后在任意目录中,都可以直接使用hdfs等命令。