ElasticSearch的基本使用
Elasticsearch简介
百度百科
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。ElasticSearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
关键字:全文搜索引擎,Restful风格,Java语言开发,基于Lucence。
首先我们先不用了解它的底层到底是怎样的,我们现在只需要知道它是一个巨大的索引库,可以存储大量的数据,然后进行各种类型的查询。然后我们就开始使用,只有先会使用,再搞明白它的道理,这样才更清晰。
使用
安装
前面我们已经带大家搭建了ELK(Elastic search,Logstash,Kibana)集群和单体架构,注意版本是6.5.2。
操作工具
我们首先启动elk,然后在kibana中有一个很好用的终端可以进行代码提示。因为elasticsearch是基于json格式的数据库,我们也可以用postman等测试工具,但是我个人建议用kibana。
ik分词器的使用
我们先下载一个插件(自行选择自己使用的版本)
https://github.com/medcl/elasticsearch-analysis-ik/releases
然后尽量下载那种zip格式的,因为这是编译好的,可以直接解压缩放到elasticsearch/plugins/ik/文件夹中,ik文件夹是自己创建的。
然后测试一下ik分词器
GET _analyze
{
"analyzer": "ik_max_word",
"text": ["中华人民共和国"]
}
结果:
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中华人民",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中华",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "华人",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "人民共和国",
"start_offset" : 2,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "人民",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "共和国",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "共和",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "国",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 8
}
]
}
es结构
Elasticsearch也是基于Lucene的全文检索库,本质也是存储数据,很多概念与MySQL类似的。
对比关系:
索引(indices)--------------------------------Databases 数据库
类型(type)-----------------------------Table 数据表
文档(Document)----------------Row 行
字段(Field)-------------------Columns 列
索引
创建索引
car是索引名字,number_of_replicas:备份数,number_of_shards:分片数

查看car索引信息,以下可以看到各种信息,创建时间,分片数,备份数,版本号等。

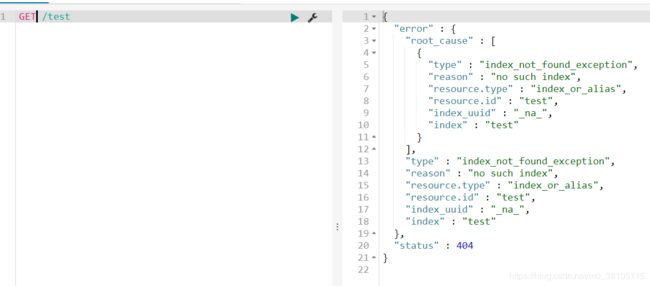
删除索引
刚才我创建了一个test索引,然后现在删除一下
可以看到删除成功!

再次查看
映射关系创建
创建索引映射信息
PUT /索引库名/_mapping/类型名称
{
"properties": {
"字段名": {
"type": "类型",
"index": true,
"store": true,
"analyzer": "分词器"
}
}
}
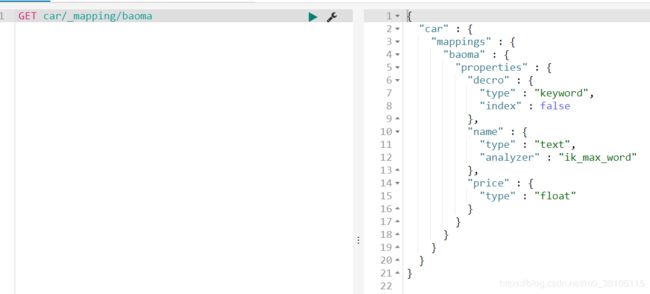
baoma就是相当于数据库表,name,decro,price就相当于属性。

我们也可以查看映射信息
字段类型
数据
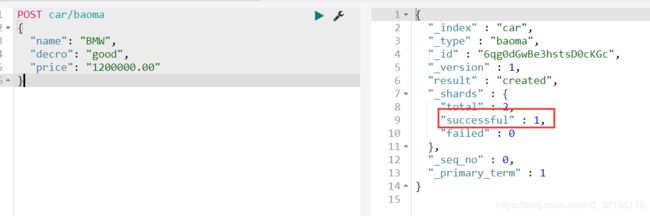
插入数据
以下结果可以看到返回成功信息。
查询数据信息
所有数据
GET _search
{
"query":{
"match_all" : {}
}
}
自定义id
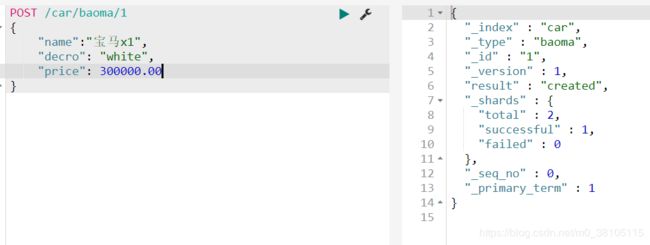
获取信息
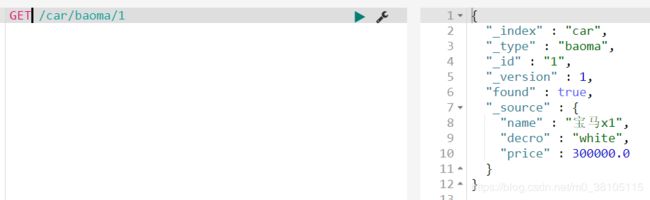
智能判断
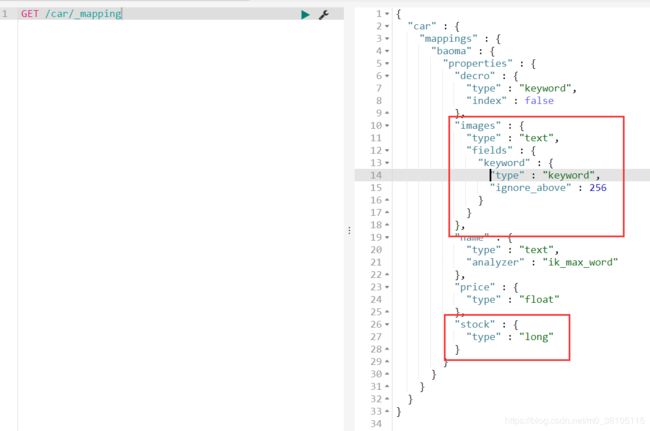
我们可以看到下面的images和stock字段我们之前并没有进行定义,为什么插入数据还是可以成功呢
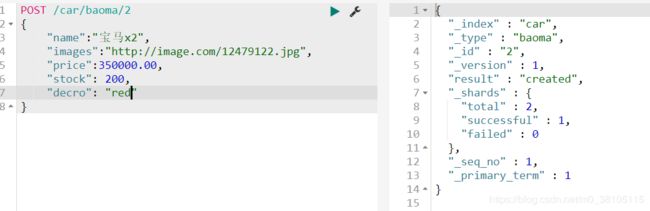
查看一下数据表关系,可以看到这两个字段被自动映射成功了。
删除数据
查询
- 基本查询
- 结果过滤
- 高级查询
- 排序
基本查询
基本语法
GET /索引库名/_search
{
"query":{
"查询类型":{
"查询条件":"查询条件值"
}
}
}
查询类型
例如:match_all, match,term , range 等等
查询所有信息
GET /car/_search
{
"query":{
"match_all": {}
}
}
- took:查询花费时间,单位是毫秒
- time_out:是否超时
- _shards:分片信息
- hits:搜索结果总览对象
- total:搜索到的总条数
- max_score:所有结果中文档得分的最高分
- hits:搜索结果的文档对象数组,每个元素是一条搜索到的文档信息
- _index:索引库
- _type:文档类型
- _id:文档id
- _score:文档得分
- _source:文档的源数据
匹配查询(match)
首先多添加几条数据
or关系:
match类型查询,会把查询条件进行分词,然后进行查询,多个词条之间是or的关系
就是会把宝马和汽车的信息都会查询出来。
GET /car/_search
{
"query":{
"match":{
"title":"宝马汽车"
}
}
}
and关系
某些情况下,我们需要更精确查找,我们希望这个关系变成and,可以这样做:
GET /heima/_search
{
"query":{
"match": {
"title": {
"query": "宝马汽车",
"operator": "and"
}
}
}
}
多字段查询
multi_match与match`类似,不同的是它可以在多个字段中查询
GET /car/_search
{
"query":{
"multi_match": {
"query": "宝马汽车",
"fields": [ "title", "subTitle" ]
}
}
}
词条匹配
term 查询被用于精确值 匹配,这些精确值可能是数字、时间、布尔或者那些未分词的字符串
GET /car/_search
{
"query":{
"term":{
"price":300000.00
}
}
}
结果过滤
默认情况下,elasticsearch在搜索的结果中,会把文档中保存在_source的所有字段都返回。
如果我们只想获取其中的部分字段,我们可以添加_source的过滤
GET /car/_search
{
"_source": ["name","price"],
"query": {
"term": {
"price": 300000
}
}
}
高级查询
bool把各种其它查询通过must(与)、must_not(非)、should(或)的方式进行组合
GET /heima/_search
{
"query":{
"bool":{
"must": { "match": { "name": "宝马" }},
"must_not": { "match": { "title": "电视" }},
"should": { "match": { "title": "汽车" }}
}
}
}
过滤
所有的查询都会影响到文档的评分及排名。如果我们需要在查询结果中进行过滤,并且不希望过滤条件影响评分,那么就不要把过滤条件作为查询条件来用。而是使用filter方式:
GET /car/_search
{
"query":{
"bool":{
"must":{ "match": { "name": "宝马汽车" }},
"filter":{
"range":{"price":{"gt":200000.00,"lt":380000.00}}
}
}
}
}
总结
我们可以通过以上的练习进行elasticsearch的查询,希望大家可以多动手多思考,祝各位生活愉快!