Java字符串池(String Pool)深度解析
在工作中,String类是我们使用频率非常高的一种对象类型。JVM为了提升性能和减少内存开销,避免字符串的重复创建,其维护了一块特殊的内存空间,这就是我们今天要讨论的核心,即字符串池(String Pool)。字符串池由String类私有的维护。
我们知道,在Java中有两种创建字符串对象的方式:1)采用字面值的方式赋值 2)采用new关键字新建一个字符串对象。这两种方式在性能和内存占用方面存在着差别。
方式一:采用字面值的方式赋值,例如:

采用字面值的方式创建一个字符串时,JVM首先会去字符串池中查找是否存在"aaa"这个对象,如果不存在,则在字符串池中创建"aaa"这个对象,然后将池中"aaa"这个对象的引用地址返回给字符串常量str,这样str会指向池中"aaa"这个字符串对象;如果存在,则不创建任何对象,直接将池中"aaa"这个对象的地址返回,赋给字符串常量。
在本例中,执行:str == str2 ,会得到以下结果:
![]()
这是因为,创建字符串对象str2时,字符串池中已经存在"aaa"这个对象,直接把对象"aaa"的引用地址返回给str2,这样str2指向了池中"aaa"这个对象,也就是说str和str2指向了同一个对象,因此语句System.out.println(str == str2)输出:true。
方式二:采用new关键字新建一个字符串对象,例如:

采用new关键字新建一个字符串对象时,JVM首先在字符串池中查找有没有"aaa"这个字符串对象,如果有,则不在池中再去创建"aaa"这个对象了,直接在堆中创建一个"aaa"字符串对象,然后将堆中的这个"aaa"对象的地址返回赋给引用str3,这样,str3就指向了堆中创建的这个"aaa"字符串对象;如果没有,则首先在字符串池中创建一个"aaa"字符串对象,然后再在堆中创建一个"aaa"字符串对象,然后将堆中这个"aaa"字符串对象的地址返回赋给str3引用,这样,str3指向了堆中创建的这个"aaa"字符串对象。
在这个例子中,执行:str3 == str4,得到以下结果:
![]()
因为,采用new关键字创建对象时,每次new出来的都是一个新的对象,也即是说引用str3和str4指向的是两个不同的对象,因此语句System.out.println(str3 == str4)输出:false。
字符串池的实现有一个前提条件:String对象是不可变的。因为这样可以保证多个引用可以同事指向字符串池中的同一个对象。如果字符串是可变的,那么一个引用操作改变了对象的值,对其他引用会有影响,这样显然是不合理的。
字符串池的优缺点:字符串池的优点就是避免了相同内容的字符串的创建,节省了内存,省去了创建相同字符串的时间,同时提升了性能;另一方面,字符串池的缺点就是牺牲了JVM在常量池中遍历对象所需要的时间,不过其时间成本相比而言比较低。
intern方法使用:一个初始为空的字符串池,它由类String独自维护。当调用 intern方法时,如果池已经包含一个等于此String对象的字符串(用equals(oject)方法确定),则返回池中的字符串。否则,将此String对象添加到池中,并返回此String对象的引用。 对于任意两个字符串s和t,当且仅当s.equals(t)为true时,s.instan() == t.instan才为true。所有字面值字符串和字符串赋值常量表达式都使用 intern方法进行操作。
GC回收:字符串池中维护了共享的字符串对象,这些字符串不会被垃圾收集器回收。
Java语言规范(Java Language Specification)中对字符串做出了如下说明:每一个字符串常量都是指向一个字符串类实例的引用。字符串对象有一个固定值。字符串常量,或者一般的说,常量表达式中的字符串都被使用方法 String.intern进行保留来共享唯一的实例。以上是Java语言规范中的原文,比较官方,用更通俗易懂的语言翻译过来主要说明了三点:1)每一个字符串常量都指向字符串池中或者堆内存中的一个字符串实例;2)字符串对象值是固定的,一旦创建就不能再修改;3)字符串常量或者常量表达式中的字符串都被使用方法String.intern()在字符串池中保留了唯一的实例。并且给出了测试程序如下:

编译单元:
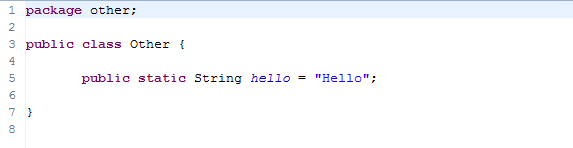
输出:
![]()
这个例子说明了6点:
- 同一个包下同一个类中的字符串常量的引用指向同一个字符串对象;
- 同一个包下不同的类中的字符串常量的引用指向同一个字符串对象;
- 不同的包下不同的类中的字符串常量的引用仍然指向同一个字符串对象;
- 由常量表达式计算出的字符串是在编译时进行计算,然后被当作常量;
- 在运行时通过连接计算出的字符串是新创建的,因此是不同的;
- 通过计算生成的字符串显示调用intern方法后产生的结果与原来存在的同样内容的字符串常量是一样的。
从上面的例子可以看出,字符串常量在编译时计算和在运行时计算,其执行过程是不同的,得到的结果也是不同的。我们来看看下面这段代码:
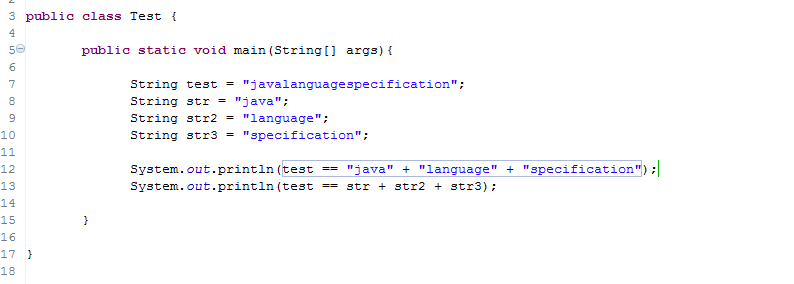
代码输出如下:

为什么出现上面的结果呢?这是因为,字符串字面量拼接操作是在Java编译器编译期间就执行了,也就是说编译器编译时,直接把"java"、"language"和"specification"这三个字面量进行"+"操作得到一个"javalanguagespecification" 常量,并且直接将这个常量放入字符串池中,这样做实际上是一种优化,将3个字面量合成一个,避免了创建多余的字符串对象。而字符串引用的"+"运算是在Java运行期间执行的,即str + str2 + str3在程序执行期间才会进行计算,它会在堆内存中重新创建一个拼接后的字符串对象。总结来说就是:字面量"+"拼接是在编译期间进行的,拼接后的字符串存放在字符串池中;而字符串引用的"+"拼接运算实在运行时进行的,新创建的字符串存放在堆中。
总结:字符串是常量,字符串池中的每个字符串对象只有唯一的一份,可以被多个引用所指向,避免了重复创建内容相同的字符串;通过字面值赋值创建的字符串对象存放在字符串池中,通过关键字new出来的字符串对象存放在堆中。
原文http://www.cnblogs.com/fangfuhai/p/5500065.html