Deep Bilateral Learning for Real-Time Image Enhanceme/hdrnet 笔记
本文参考论文Deep Bilateral Learning for Real-Time Image Enhanceme,按照原文中的第三章,通过阐述重点思想并结合代码来介绍hdrnet的网络结构。
论文project地址:https://groups.csail.mit.edu/graphics/hdrnet/
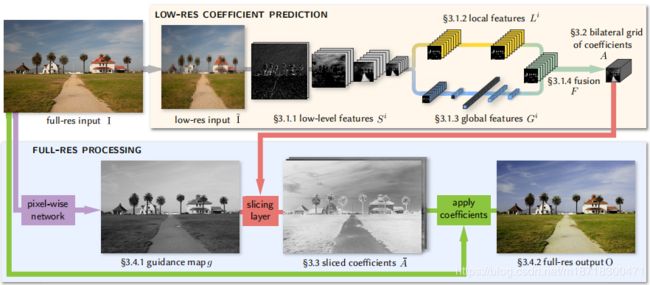
3 OUR ARCHITECTURE
大部分的运算发生在低分辨率的图像上,即上图的黄色背景部分,其最终预测出一个视为双向网格(bilateral grid)的局部仿射变换A。根据经验,图像增强不仅依赖于局部图像特征,还依赖于全局图像特征如直方图、平均强度甚至场景类别等。于是低分辨率处理流被分割成了提取局部(3.1.2) 和 全局(3.1.3) 特征的两条路径,最后将这两条路径 汇聚(3.1.4) 起来得到最终的预测。
上图下半部分的高分辨率处理流运算量小,但在捕捉高频效果(capturing high-frequency effects )和保留边缘信息(preserving edges)上发挥重要作用。为此引入了由双向网格处理激发的切割节点(slicing node),即上图标红部分。这个节点基于学习到的引导图g(3.4.1),在A上进行了数据相关的查找,由此得到切割后的系数A~(3.3)。最后对每个像素应用局部颜色变换(local color transform),上图绿色部分,即可获得最终输出O。
3.1 Low-resolution prediction of bilateral coefficients
低分辨率图像尺寸固定为256X256。其首先经过一系列卷积层来提取低等级特征并下采样(3.1.1),然后分为两条不对称路径:局部路径全由卷积层组成,用于学习局部特征和在保留空间信息的前提下向前传播图像数据;全局路径有卷积层和FC层,用覆盖了整个低分辨率图像的感受野来学习一个固定尺寸的全局特征向量。随后这两条路径被汇聚成(fused into)特征F,其经过一逐点线性层后输出A。
3.1.1 Low-level features
这些层使得数据的空间维度下降了2nS,其中nS为层数,文中nS=4.
nS的作用为:
- 决定了低分辨率图像到最终仿射系数A的空间下采样,nS越大,最终网格A粒度越大
- 控制着预测的复杂度。层数越多,其空间支持将会指数性增大,非线性复杂度也会增大。因此可以从输入中提取更复杂的模式
# -----------------------------------------------------------------------
# low-level features Si
with tf.variable_scope('splat'):
n_ds_layers = int(np.log2(params['net_input_size']/spatial_bin))
current_layer = input_tensor
for i in range(n_ds_layers): # 4个卷积层
if i > 0: # don't normalize first layer
use_bn = params['batch_norm']
else:
use_bn = False
current_layer = conv(current_layer, cm*(2**i)*gd, 3, stride=2, # 可推算出cm*gd=8
batch_norm=use_bn, is_training=is_training,
scope='conv{}'.format(i+1))
splat_features = current_layer
# -----------------------------------------------------------------------
3.1.2 Local features path
# -----------------------------------------------------------------------
# 3.1.2 local features Li 经过两层卷积层后得到局部特征
with tf.variable_scope('local'):
current_layer = splat_features
#两层卷积层
current_layer = conv(current_layer, 8*cm*gd, 3,
batch_norm=params['batch_norm'],
is_training=is_training,
scope='conv1')
# don't normalize before fusion
current_layer = conv(current_layer, 8*cm*gd, 3, activation_fn=None,
use_bias=False, scope='conv2')
grid_features = current_layer
# -----------------------------------------------------------------------
3.1.3 Global features path
# -----------------------------------------------------------------------
# 3.1.3 global features Gi 经过两层卷积层和三层全连接层得到全局特征
with tf.variable_scope('global'):
n_global_layers = int(np.log2(spatial_bin/4)) # 4x4 at the coarsest lvl
current_layer = splat_features
for i in range(2): # 两层卷积
current_layer = conv(current_layer, 8*cm*gd, 3, stride=2,
batch_norm=params['batch_norm'], is_training=is_training,
scope="conv{}".format(i+1))
_, lh, lw, lc = current_layer.get_shape().as_list()
current_layer = tf.reshape(current_layer, [bs, lh*lw*lc])
# 三层全连接层
current_layer = fc(current_layer, 32*cm*gd,
batch_norm=params['batch_norm'], is_training=is_training,
scope="fc1")
current_layer = fc(current_layer, 16*cm*gd,
batch_norm=params['batch_norm'], is_training=is_training,
scope="fc2")
# don't normalize before fusion
current_layer = fc(current_layer, 8*cm*gd, activation_fn=None, scope="fc3")
global_features = current_layer # (1, 64)
# -----------------------------------------------------------------------
3.1.4 Fusion and linear prediction & 3.2 Image features as a bilateral grid
# -----------------------------------------------------------------------
# 3.1.4 将局部特征与全局特征进行fusion
# “fuse the contributions of the local and global paths with a pointwise affine mixing followed by a ReLU activation”
with tf.name_scope('fusion'):
fusion_grid = grid_features # (1, 16, 16, 64)
fusion_global = tf.reshape(global_features, [bs, 1, 1, 8*cm*gd]) # (1, 1, 1, 64)
fusion = tf.nn.relu(fusion_grid+fusion_global) # (1, 16, 16, 64) 公式(2),此处获得Fusion F
# fusion is a 16*16*64 array of features
# -----------------------------------------------------------------------
# -----------------------------------------------------------------------
# 3.1.4 linear prediction, from fusion we make our final 1*1 linear prediction to produce a 16*16 map with 96 channels
with tf.variable_scope('prediction'):
current_layer = fusion # (1,16,16,96)
current_layer = conv(current_layer, gd*cls.n_out()*cls.n_in(), 1,
activation_fn=None, scope='conv1') # 公式(3), 此处获得feature map A
# 3.2 Image features as a bilateral grid
with tf.name_scope('unroll_grid'): # 公式(4)
current_layer = tf.stack(
tf.split(current_layer, cls.n_out()*cls.n_in(), axis=3), axis=4) # (1,16,16,8,12)
current_layer = tf.stack(
tf.split(current_layer, cls.n_in(), axis=4), axis=5) # (1,16,16,8,3,4)
tf.add_to_collection('packed_coefficients', current_layer)
# -----------------------------------------------------------------------
3.3 Upsampling with a trainable slicing layer
@classmethod
# 3.3 UpSamling with a trainable slicing layer
# 输入引导图g与以双向网格存储的特征图A,经过slicing后得到full res的特征图A_
def _output(cls, im, guide, coeffs):
with tf.device('/gpu:0'):
out = bilateral_slice_apply(coeffs, guide, im, has_offset=True, name='slice')
return out
def bilateral_slice_apply(grid, guide, input_image, has_offset=True, name=None):
"""Slices into a bilateral grid using the guide map.
Args:
grid: (Tensor) [batch_size, grid_h, grid_w, depth, n_outputs]
grid to slice from.
guide: (Tensor) [batch_size, h, w ] guide map to slice along.
input_image: (Tensor) [batch_size, h, w, n_input] input data onto which to
apply the affine transform.
name: (string) name for the operation.
Returns:
sliced: (Tensor) [batch_size, h, w, n_outputs] sliced output.
"""
with tf.name_scope(name):
gridshape = grid.get_shape().as_list()
if len(gridshape) == 6:
gs = tf.shape(grid)
_, _, _, _, n_out, n_in = gridshape
grid = tf.reshape(grid, tf.stack([ gs[0], gs[1], gs[2], gs[3], gs[4]*gs[5] ])) # 将grid的形状reshape为(1,16,16,8,12)
# grid = tf.concat(tf.unstack(grid, None, axis=5), 4)
sliced = hdrnet_ops.bilateral_slice_apply(grid, guide, input_image, has_offset=has_offset)
return sliced
@ops.RegisterShape('BilateralSliceApply')
def _bilateral_slice_shape(op):
grid_tensor = op.inputs[0] # reshape 之后的grid
guide_tensor = op.inputs[1] # 引导图
input_tensor = op.inputs[2] # full-res 图像
has_offset = op.get_attr('has_offset')
chan_in = input_tensor.get_shape()[-1]
chan_grid = grid_tensor.get_shape()[-1]
if has_offset:
chan_out = chan_grid // (chan_in+1)
else:
chan_out = chan_grid // chan_in
return [guide_tensor.get_shape().concatenate(chan_out)]
3.4 Assembling the full-resolution output
3.4.1 Guidance map auxiliary network
def _guide(cls, input_tensor, params, is_training):
# 3.4.1 输入全分辨率图像来获得引导图g; input_tensor为(1, ?, ?, 3)的full_res input,
npts = 16 # number of control points for the curve
nchans = input_tensor.get_shape().as_list()[-1]
guidemap = input_tensor
# Color space change
idtity = np.identity(nchans, dtype=np.float32) + np.random.randn(1).astype(np.float32)*1e-4 # 三阶单位矩阵加上随机数, "M is initialized to the identity"
ccm = tf.get_variable('ccm', dtype=tf.float32, initializer=idtity) # 用以上矩阵来初始化一个变量ccm,故其为(3,3),ccm是需要通过学习来优化的
with tf.name_scope('ccm'):
ccm_bias = tf.get_variable('ccm_bias', shape=[nchans,], dtype=tf.float32, initializer=tf.constant_initializer(0.0)) # 初始化要学习的偏置ccm_bias
# 下两行为执行文中的公式(6)中的括号部分
guidemap = tf.matmul(tf.reshape(input_tensor, [-1, nchans]), ccm) # 原始图像reshape后与参数矩阵相乘
guidemap = tf.nn.bias_add(guidemap, ccm_bias, name='ccm_bias_add') # 加上偏置
guidemap = tf.reshape(guidemap, tf.shape(input_tensor)) # reshape回原来的形状(1,?,?,3)
# Per-channel curve, 以下block为执行公式(7)
with tf.name_scope('curve'):
shifts_ = np.linspace(0, 1, npts, endpoint=False, dtype=np.float32) # 在指定的间隔内返回均匀间隔的数字,此处以0.0625为间隔构造16个元素的数组【0, 0.0625, 0.125, ……, 0.9375】
shifts_ = shifts_[np.newaxis, np.newaxis, np.newaxis, :]
shifts_ = np.tile(shifts_, (1, 1, nchans, 1))
guidemap = tf.expand_dims(guidemap, 4) # 在guidemap的第四维插入一个维度,此时guidmap形状为(1,?,?,3,1)
shifts = tf.get_variable('shifts', dtype=tf.float32, initializer=shifts_) # shitfs_形状为(1,1,3,16), 内容为三个上述间隔数组
slopes_ = np.zeros([1, 1, 1, nchans, npts], dtype=np.float32)
slopes_[:, :, :, :, 0] = 1.0
slopes = tf.get_variable('slopes', dtype=tf.float32, initializer=slopes_) # (1,1,1,3,16)
guidemap = tf.reduce_sum(slopes*tf.nn.relu(guidemap-shifts), reduction_indices=[4]) # 公式(7)
guidemap = tf.contrib.layers.convolution2d( # p_c再经过一个卷积核大小为1的卷积层,相当于公式(6)
inputs=guidemap,
num_outputs=1, kernel_size=1,
weights_initializer=tf.constant_initializer(1.0/nchans),
biases_initializer=tf.constant_initializer(0),
activation_fn=None,
variables_collections={'weights':[tf.GraphKeys.WEIGHTS], 'biases':[tf.GraphKeys.BIASES]},
outputs_collections=[tf.GraphKeys.ACTIVATIONS],
scope='channel_mixing')
guidemap = tf.clip_by_value(guidemap, 0, 1)
guidemap = tf.squeeze(guidemap, squeeze_dims=[3,])
return guidemap
3.4.2 Assembling the final output
模型运行结果
使用pretrained_models目录下的download.py下载预训练模型后,在图像上使用预训练模型experts/experts_cm1/expertA与experts/experts_cm1/expertB获得的结果如下:

Tensorboard
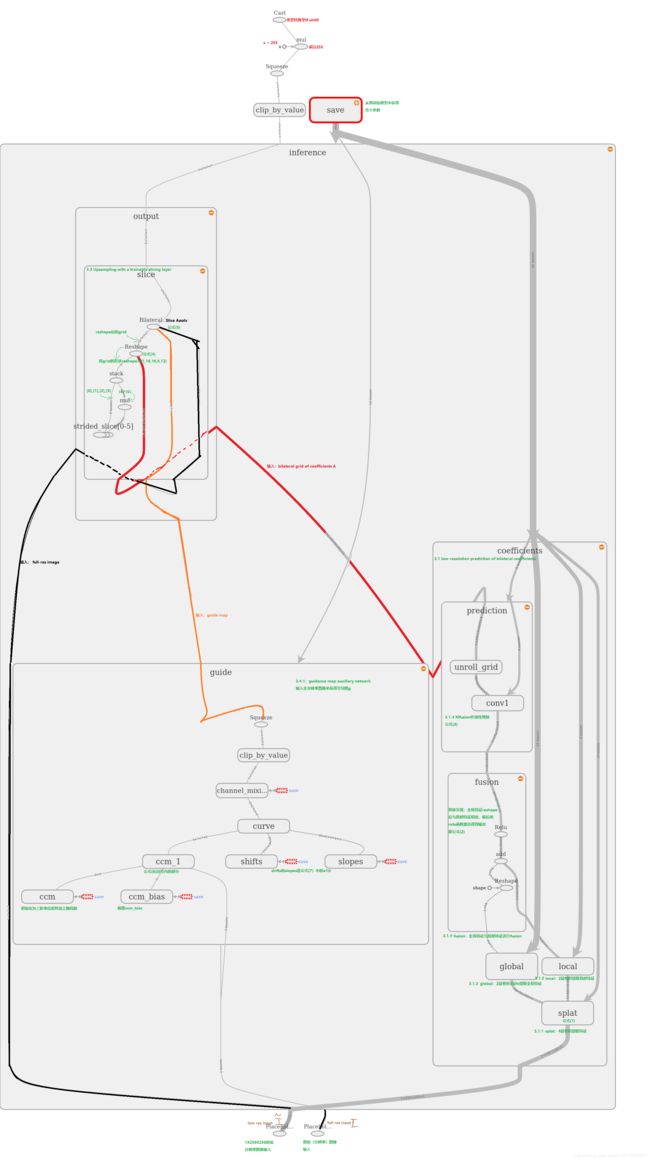
为了获取对网络结构和模型运算处理过程更直观的认识,用tensorboard生成了graph并根据文中章节和公示等一一标注,如下:
【参考文献】:
Gharbi M, Chen J, Barron J T, et al. Deep bilateral learning for real-time image enhancement[J]. ACM Transactions on Graphics (TOG), 2017, 36(4): 118.