hadoop3.0.3搭建与入门(添加删除;调度-节点)
hadoop版本:apache cloudera(CDH版) Hortonworks(HDP版)
国内对CDH用的多
一般用3.0
单机版
scp hadoop-3.0.3.tar.gz jdk-8u181-linux-x64.tar.gz server1:/root/
src是源码包
4 useradd hadoop
5 cd /home/hadoop/
6 mv /root/hadoop-3.0.3.tar.gz /root/jdk-8u181-linux-x64.tar.gz /home/hadoop/
passwd hadoop
su hadoop
7 ls
8 tar zxf hadoop-3.0.3.tar.gz
9 tar zxf jdk-8u181-linux-x64.tar.gz
10 ls
11 ln -s hadoop-3.0.3 hadoop
12 ln -s jdk1.8.0_181/ java
[root@server1 hadoop]# pwd
/home/hadoop/hadoop
[root@server1 hadoop]# vim etc/hadoop/hadoop-env.sh
export JAVA_HOME=/home/hadoop/java
[root@server1 hadoop]# vim etc/hadoop/hadoop-env.sh
[root@server1 hadoop]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar grep input output 'dfs[a-z.]+'
[root@server1 hadoop]# cd output/
[root@server1 output]# cat *
1 dfsadmin
伪分布式
su - hadoop
29 vim core-site.xml
fs.defaultFS
hdfs://localhost:9000
30 vim hdfs-site.xml
31 ssh-keygen
32 ssh-copy-id localhost
bin/hdfs namenode -format
./sbin/start-dfs.sh
su hadoop
vim ~/.bash_profile
/home/hadoop/java/bin
:$HOME/java/bin
source ~/.bash_profile
这里误将2设为了master 但我写的时候部分master操作写成了server1注意
bin/hdfs dfs -mkdir -p /user/hadoop
bin/hdfs dfs -put etc/hadoop input
bin/hdfs dfs -ls /
[hadoop@server2 hadoop]$ bin/hdfs dfs -ls /
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2019-04-06 10:27 /user
bin/hdfs dfs -put input
bin/hdfs dfs -ls
[hadoop@server2 hadoop]$ bin/hdfs dfs -ls
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2019-04-06 10:28 input
172.25.11.1:9870

分布式架构
server1 如上操作
server2 3 4 1
useradd -u 1000 hadoop
yum install nfs-utils -y
systemctl start rpcbind
vim /etc/exports
/home/hadoop *(rw,anonuid=1000,anongid=1000)
exportfs -rv
systemctl start nfs
showmount -e
server1 sbin/stop-dfs.sh
server2 3 4
mount 172.25.11.2:/home/hadoop /home/hadoop
server1
vim etc/hadoop/core-site.xml
vim etc/hadoop/hdfs-site.xml
添加两个副本 改为3
vim etc/hadoop/workers
172.25.11.2
172.25.11.3 4
rm -fr /tmp/*
bin/hdfs namenode -format
ssh 不需要免密 因为挂载了/home/hadoop
sbin/start-dfs.sh
jps
[hadoop@server2 hadoop]$ jps
13649 SecondaryNameNode
13431 NameNode
14108 Jps
bin/hdfs dfs -mkdir -p /user/hadoop
bin/hdfs dfs -mkdir -p input
bin/hdfs dfs -put etc/hadoop/*.xml input
bin/hdfs dfs -ls input
测试分布式运作
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar grep input output 'dfs[a-z.]+'
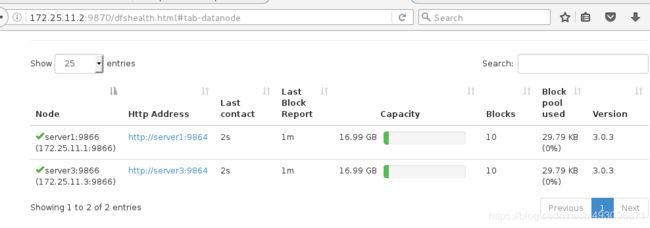
再加一台server4操作同上slaves
再server4里面操作
sbin/hadoop-daemon.sh start datanode
bin/hdfs dfsadmin -refreshNodes
bin/hdfs dfsadmin -report
[hadoop@server2 hadoop]$ bin/hdfs dfsadmin -report
Safe mode is ON
Configured Capacity: 54716792832 (50.96 GB)
Present Capacity: 51347333120 (47.82 GB)
DFS Remaining: 51347320832 (47.82 GB)
DFS Used: 12288 (12 KB)
DFS Used%: 0.00%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 10
Missing blocks (with replication factor 1): 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (3):
server1去掉server3节点
vim dfs.hosts.exclude
172.25.11.3
vim hdfs-site.xml
bin/hdfs dfsadmin -refreshNodes 主要是为了迁移数据
bin/hdfs dfsadmin -report
调度管理
vim etc/hadoop/mapred-site.xml
vim etc/hadoop/yarn-site.xml
sbin/start-yarn.sh
[hadoop@server2 hadoop]$ jps
20834 ResourceManager
21135 Jps