高性能MySQL】第7章MySQL高级特性 下
7.10全文索引
通过关键字匹配进行查询过滤,基于相似度的查询
有自己独特的语法,没有索引可以工作,有了索引效率更高,全局搜索的索引有独特的结构;全文索引支持各种字符内容的搜索,也支持自然语言搜索和布尔搜索
主讲MyISAM的全文索引:
作用对象时全文集合,具体的:对表某一条记录,mysql会将需要索引的列全部拼接成一个字符串,进行索引
myisam是一类特殊的b-tree索引:第一层all关键字,对应于每个关键字的第二层(一组相关的文档指针)
不会索引文档对象中的all词语,据如下规则过滤一些词语:
- 停用词列表中的词不会被索引,默认停用词据通用英语的使用来设置,可使用参数ft_stopword_file指定外部文件来使用自定义的停用词
- 对应长度大于ft_min_word_len的词语和长度小于ft_max_word_len的词语,不会被索引?反了吧
7.10.1自然语言的全文索引
计算每个文档对象和查询的相关度(基于匹配的关键词个数、次数 反比)
自动按照相似度进行排序,无法使用索引排序,不想使用文件排序的话,不要在查询中使用order by子句
match指定的列必须和全文索引中指定的列一样,否则无法使用全文索引:不会记录关键字来自哪一列,无法使用全文索引查询某个关键词是否在某列中存在
7.10.2布尔全文索引
布尔搜索中,用户可在查询中自定义某个被搜索的词语的相关性
通过停用词列表过滤掉“噪声”词,还要求搜索关键词长度>ft_min_word_len, 新增插件式解析、性能提升:定制增强搜索功能 只有一种判断相关性的方法:词频 全文索引只有全部在内存中,性能才非常好 可实现简单边框搜索:范围值 缓存全文索引返回的主键值:分页显示常用 日常维护:optimize table减少碎片,IO密集型、定期全文索引重建 保证索引缓存足够大、all全文索引都 缓存在内存中,可设置单独的键缓存 提供一个好的停用词表很重要,默认的对英语不错,其他语言不合适 忽略一些太短的单词,最小长度可通过ft_min_word_len配置、optimize table重建索引使其生效 向有全文索引表中导入大量数据时,先通过disable keys禁用全文索引,导入将结束用enable keys建立全文索引 分布式事务让存储引擎级别的ACID扩展到数据库层面,甚至多个库间,MySQL5.0及后支持XA事务 需要事务协调器保证all事务参与者都完成了准备工作、都准备好、all事务可以提交,mysql此过程中是一个参与者 两种xa事务: MySQL可参与到外部的分布式事务中,还可以同xa协调存储引擎和二进制日志 mysql本身的插件式架构导致在其内部需要使用xa事务,各存储引擎完全独立,跨引擎需要xa协助 影响因素多、尽量不用 xa事务是多个服务器间同步数据的方法,如果不能使用mysql本身复制或性能不是瓶颈时,可以尝试使用xa mysql查询缓存保存查询返回的完整结果,当查询命中缓存,立刻返回结果 应该默认关闭查询缓存,如果查询缓存很有用,可配置小的查询缓存空间 缓存存在一个引用表中,通过哈希值引用 这个哈希值包含:查询本身、当前要查询是数据库、客户端协议的版本等一些其他可能影响返回结果的信息 判断时直接使用mysql语句和客户端发送过来的原始信息,如何不同都导致不命中 使用统一编码规则 查询语句中一些不确定数据时,不会被缓存,如包含now、current_date的查询 如果查询语句中包含如何不确定函数,那么查询缓存中是不可能找到缓存结果的,mysql只要发现不能被缓存的部分就会禁用这个查询缓存 用于查询缓存的内存被分成一个个数据块,数据块是变长的,每块存储了自己的类型、大小和存储数据本身,指向前后数据块的指针 数据库类型:存储查询结果、存储查询和数据表的映射、存储查询文本等 服务器启动时先初始化查询缓存需要的内存:完整空闲块,当需要缓存时,先从大的空间块申请一块用于存储结果(>query_cache_min_res_unit配置) 先锁住空间块在找到合适的块,慢、尽量避免:先选尽可能小的、如果用完仍有数据需要存储,会申请新的数据块,查询完成、申请的空间有剩余、将其释放,mysql自己管理一大块内存,碎片 消耗大量资源的查询:汇总计算查询、count 复杂的select语句都可以使用查询缓存(设计表上的增删改操作要比查少才行) 查询缓存命中率:qcache_hits/(qcache_hits+com_select)多少合适、欠缺 直观反映:命中写入比率:qcache_hits和qcache_inserts比值>3:1 缓存有效,最好能达到10:1 观察查询缓存的内存实际使用情况、确实是否需要缩小或扩大查询缓存 query_cache_type: 是否打开查询缓存,off on demand:在查询语句中 明确写明sql_cache的语句才放入查询缓存(会话和全局) query_cache_size: 总内存空间,单位字节,1024整数倍 query_cache_min_unit: 查询缓存中分配内存块时最小单位 query_cache_limit: 能够缓存的最大的查询结果,查询结果大于此值不会被缓存 query_cache_wlock_invalidate: 某个数据表被其他连接锁住,是否仍然从查询缓存中返回结果,默认off 内存实际消耗query_cache_size-qcache_free_memory除以qcache_queries_in_cache计算单个查询的平均缓存大小 通过qcache_free_blocks观察碎片:反映查询缓存中空闲块的大小 flush query cache完成碎片整理:all查询缓存重排序,all空闲空间聚集到查询缓存的一块区域上,期间all连接无法访问查询缓存 qcache_lowmem_prunes增加很多: 还有很多空闲块,碎片 分配的查询缓存空间不够大,检查qcache_free_memory查看多少未使用内存 innodb自己的mvcc,和查询缓存交互更复杂,4.0事务处理中查询缓存被禁,4.1及后会控制在事务中是否可使用查询缓存 是否可以访问取决于当前事务ID及对应表上是否有锁:当前事务ID小于该事务ID,则无法访问查询缓存,锁、不能 如希望部分查询走缓存,设置query_cache_type为demand,在希望缓存的查询中加上SQL_cache mysql查询缓存工作的原则: 执行查询最快的方式就是不去执行(这个厉害了)但是查询仍需要发送到服务器端,服务器也需要做点工作 分区表: 粗粒度、简易索引策略,适用于大数据量的过滤场景:在没有合适索引,对其中几个分区进行全表扫描;只有一个分区和索引是热点,且分区和索引都在内存中;单表分区数不要超过150个,且注意某些导致无法做分区过滤的细节 视图: 好几个表的复制查询;使用临时表时无法将where条件下推到个各表,不能使用索引 外键: 外键限制将约束放到mysql中,被看作是确保系统完整性的额外的特性,对应必须维护外键的场景,性能更高 额外复杂性和索引消耗,增加表间交互,导致系统更多的锁和竞争 存储过程: 本身实现了存储过程、触发器、存储函数和事件,通常这些课省网络开销,提示系统性能,但没有其他数据库系统成熟和全面 绑定变量: 只需解析一次,大量重复类型的查询,性能提升;执行计划的缓存和传输使用的二进制协议,使用绑定变量更快; 插件: c/c++编写的插件最大程度扩展mysql功能 字符集: 字节到字符间的映射,校对规则是指一个字符集的排序方法,很多人使用Latin1或utf-8 如果使用utf-8,在临时表和缓存区要注意:会按每个字符三字节的最大占用空间分配存储空间,可能消耗更多的内存或磁盘空间 让字符集合mysql字符集配置相符 全文索引: 通过帮客户构建和使用sphinx来解决全文索引问题 xa事务: 除非你明白innodb_support_xa的意义,不要改 innodb和二进制日志也是需要使用xa事务来做协调的、保证协调崩溃、数据能一致地恢复 查询缓存: 高并发环境下查询缓存导致系统性能下降;不要设置太大内存且只有在明确收益时才使用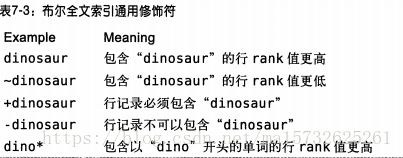 使用()分组、构造复制搜索查询
使用()分组、构造复制搜索查询7.10.3mysql5.1中全文索引变化
7.10.4全文索引的限制和替代方案
7.10.5全文索引配置和优化
7.11分布式XA事务
7.11.1内部XA事务
7.11.2外部XA事务
7.12查询缓存
7.12.1mysql如何判断缓存命中
7.12.2查询缓存如何使用内存
7.12.3什么情况下查询缓存能发挥作用
7.12.4如何配置和维护查询缓存
减少碎片
提高查询缓存的使用率
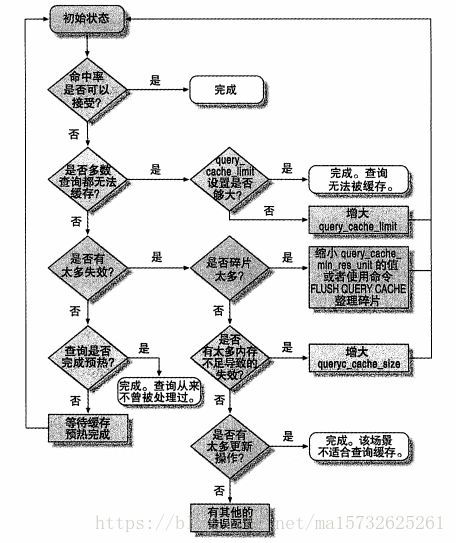
7.12.5innodb和查询缓存
7.12.6通用查询缓存优化
7.12.7查询缓存的替代方案
7.13总结