Elasticsearch 主要监控指标
Elasticsearch具有通用性、可扩展性和实用性的特点,集群的基础架构必须满足如上特性。合理的集群架构能支撑其数据存储及并发响应需求。相反,不合理的集群基础架构和错误配置可能导致集群性能下降、集群无法响应甚至集群崩溃。监控系统的节点运行情况、集群健康、JVM性能状况、索引性能、检索性能等,实时发现问题,防患于未然。
监控工具
实际业务场景中,如果公司条件允许,X-pack是首选,具备数据安全和监控告警等功能,用的放心。
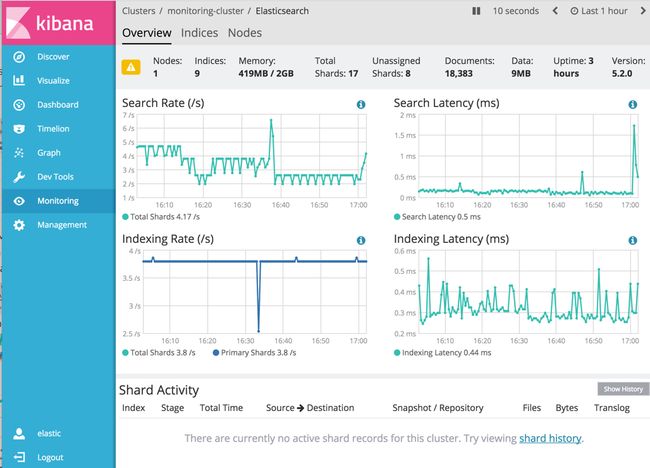
免费工具推荐使用:Elastic-HQ, cerebro监控。
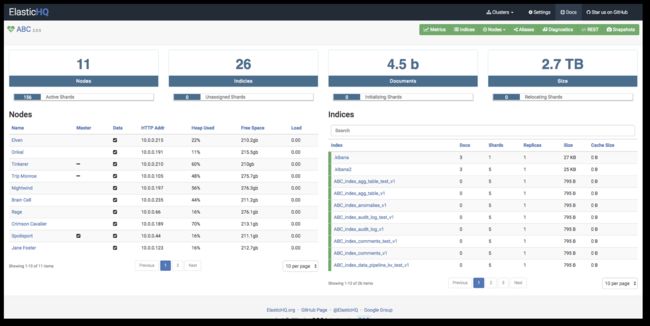
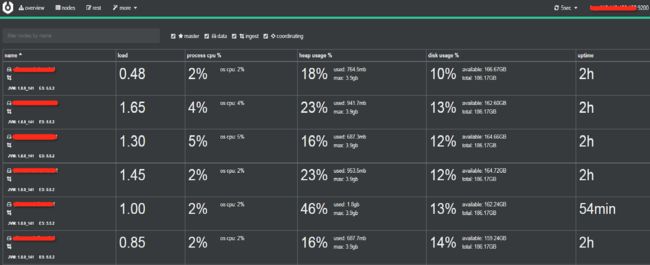
1、节点运行状况维度:内存,磁盘和CPU指标
每个节点都运行物理硬件上,需要访问系统内存,磁盘存储和CPU周期,以便管理其控制下的数据并响应对集群的请求。
Elasticsearch是一个严重依赖内存 以实现性能的系统,因此密切关注内存使用情况与每个节点的运行状况和性能相关。改进指标的相关配置更改也可能会对内存分配和使用产生负面影响,因此记住从整体上查看系统运行状况非常重要。
监视节点的CPU使用情况并查找峰值有助于识别节点中的低效进程或潜在问题。CPU性能与Java虚拟机(JVM)的垃圾收集过程密切相关。
磁盘高读写可能导致系统性能问题。由于访问磁盘在时间上是一个“昂贵”的过程,因此应尽可能减少磁盘I/O。
通过如下命令行可以实现节点级别度量指标,并反映运行它的实例或计算机的性能。
GET _cat/nodes?v&h=id,disk.total,disk.used,disk.avail,disk.used_percent,ram.current,ram.percent,ram.max,cpu&format=json&pretty
[
{
"id" : "yrVc",
"disk.avail" : "17.7gb",
"ram.current" : "2.6gb",
"ram.percent" : "56",
"ram.max" : "4.6gb",
"cpu" : "0"
}
]
注意:本文验证时采用的版本为ES 5.4.0,有些指标与原文不同,根据不同版本返回结果会有变化。
节点运行的重要指标:
- disk.total :总磁盘容量。节点主机上的总磁盘容量。
- disk.used:总磁盘使用量。节点主机上的磁盘使用总量。
- avail disk:可用磁盘空间总量。
- disk.avail disk.used_percent:使用的磁盘百分比。已使用的磁盘百分比。
- ram:当前的RAM使用情况。当前内存使用量(测量单位)。
- percent ram:RAM百分比。正在使用的内存百分比。
- max : 最大RAM。 节点主机上的内存总量
- cpu:中央处理器。正在使用的CPU百分比。
2、JVM运行状况维度:堆,GC和池大小
作为基于Java的应用程序,Elasticsearch在Java虚拟机(JVM)中运行。JVM在其“堆”分配中管理其内存,并通过garbage collection进行垃圾回收处理。
如果应用程序的需求超过堆的容量,则应用程序开始强制使用连接的存储介质上的交换空间。虽然这可以防止系统崩溃,但它可能会对集群的性能造成严重破坏。监视可用堆空间以确保系统具有足够的容量对于集群的健康至关重要。
JVM内存分配给不同的内存池。您需要密切注意这些池中的每个池,以确保它们得到充分利用并且没有被超限利用的风险。
垃圾收集器(GC)很像物理垃圾收集服务。我们希望让它定期运行,并确保系统不会让它过载。理想情况下,GC性能视图应类似均衡波浪线大小的常规执行。尖峰和异常可以成为更深层次问题的指标。
可以通过GET /_nodes/stats 命令检索JVM度量标准。
GET /_nodes/stats
"jvm" : {
"timestamp" : 1557588707194,
"uptime_in_millis" : 22970151,
"mem" : {
"heap_used_in_bytes" : 843509048,
"heap_used_percent" : 40,
"heap_committed_in_bytes" : 2077753344,
"heap_max_in_bytes" : 2077753344,
"non_heap_used_in_bytes" : 156752056,
"non_heap_committed_in_bytes" : 167890944,
"pools" : {
"young" : {
"used_in_bytes" : 415298464,
"max_in_bytes" : 558432256,
"peak_used_in_bytes" : 558432256,
"peak_max_in_bytes" : 558432256
},
"survivor" : {
"used_in_bytes" : 12178632,
"max_in_bytes" : 69730304,
"peak_used_in_bytes" : 69730304,
"peak_max_in_bytes" : 69730304
},
"old" : {
"used_in_bytes" : 416031952,
"max_in_bytes" : 1449590784,
"peak_used_in_bytes" : 416031952,
"peak_max_in_bytes" : 1449590784
}
}
},
"threads" : {
"count" : 116,
"peak_count" : 119
},
"gc" : {
"collectors" : {
"young" : {
"collection_count" : 260,
"collection_time_in_millis" : 3463
},
"old" : {
"collection_count" : 2,
"collection_time_in_millis" : 125
}
}
},
JVM运行的重要指标如下:
- mem:内存使用情况。堆和非堆进程和池的使用情况统计信息。
- threads:当前使用的线程和最大数量。
- gc:垃圾收集。算和垃圾收集所花费的总时间。
3、集群健康维度:分片和节点
分片数的多少对集群性能的影响至关重要。分片数量设置过多或过低都会引发一些问题。
分片数量过多,则批量写入/查询请求被分割为过多的子写入/查询,导致该索引的写入、查询拒绝率上升;
对于数据量较大的索引,当分片数量过小时,无法充分利用节点资源,造成机器资源利用率不高或不均衡,影响写入/查询的效率。
通过GET _cluster/health监视群集时,可以查询集群的状态、节点数和活动分片计数的信息。还可以查看重新定位分片,初始化分片和未分配分片的计数。
GET _cluster/health
{
"cluster_name" : "elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 127,
"active_shards" : 127,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 120,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 51.417004048582996
}
集群运行的重要指标:
- Status:状态群集的状态。红色:部分主分片未分配。黄色:部分副本分片未分配。绿色:所有分片分配ok。
- Nodes:节点。包括群集中的节点总数,并包括成功和失败节点的计数。 Count of Active
- Shards:活动分片计数。集群中活动分片的数量。 Relocating - Shards:重定位分片。由于节点丢失而移动的分片计数。
- Initializing Shards:初始化分片。由于添加索引而初始化的分片计数。 - Unassigned Shards。未分配的分片。尚未创建或分配副本的分片计数。
4、搜索性能维度:请求率和延迟
我们可以通过测量系统处理请求的速率和每个请求的使用时间来衡量集群的有效性。
当集群收到请求时,可能需要跨多个节点访问多个分片中的数据。系统处理和返回请求的速率、当前正在进行的请求数以及请求的持续时间等核心指标是衡量集群健康重要因素。
请求过程本身分为两个阶段:
- 第一是查询阶段(query phase),集群将请求分发到索引中的每个分片(主分片或副本分片)。
- 第二个是获取阶段(fetch phrase),查询结果被收集,处理并返回给用户。
通过GET {index}/_stats查看对应目标索引状态。
GET {index}/_stats
"search" : {
"open_contexts" : 0,
"query_total" : 10,
"query_time_in_millis" : 0,
"query_current" : 0,
"fetch_total" : 1,
"fetch_time_in_millis" : 0,
"fetch_current" : 0,
"scroll_total" : 5,
"scroll_time_in_millis" : 15850,
"scroll_current" : 0,
"suggest_total" : 0,
"suggest_time_in_millis" : 0,
"suggest_current" : 0
},
请求检索性能相关的重要指标如下:
- query_current:当前正在进行的查询数。集群当前正在处理的查询计数。
- fetch_current:当前正在进行的fetch次数。集群中正在进行的fetch计数。
- query_total:查询总数。集群处理的所有查询的聚合数。
- query_time_in_millis:查询总耗时。所有查询消耗的总时间(以毫秒为单位)。
f- etch_total:提取总数。集群处理的所有fetch的聚合数。
f- etch_time_in_millis:fetch所花费的总时间。所有fetch消耗的总时间(以毫秒为单位)。
5、索引性能维度:刷新(refresh)和合并(Merge)时间
文档的增、删、改操作,集群需要不断更新其索引,然后在所有节点上刷新它们。所有这些都由集群负责,作为用户,除了配置 refresh interval 之外,我们对此过程的控制有限。
增、删、改批处理操作,会形成新段(segment)并刷新到磁盘,并且由于每个段消耗资源,因此将较小的段合并为更大的段对于性能非常重要。同上类似,这由集群本身管理。
监视文档的索引速率( indexing rate )和合并时间(merge time)有助于在开始影响集群性能之前提前识别异常和相关问题。将这些指标与每个节点的运行状况并行考虑,这些指标为系统内的潜问题提供重要线索,为性能优化提供重要参考。
可以通过GET /_nodes/stats 获取索引性能指标,并可以在节点,索引或分片级别进行汇总。
GET /_nodes/stats
"merges" : {
"current" : 0,
"current_docs" : 0,
"current_size_in_bytes" : 0,
"total" : 245,
"total_time_in_millis" : 58332,
"total_docs" : 1351279,
"total_size_in_bytes" : 640703378,
"total_stopped_time_in_millis" : 0,
"total_throttled_time_in_millis" : 0,
"total_auto_throttle_in_bytes" : 2663383040
},
"refresh" : {
"total" : 2955,
"total_time_in_millis" : 244217,
"listeners" : 0
},
"flush" : {
"total" : 127,
"periodic" : 0,
"total_time_in_millis" : 13137
},
索引性能维度相关重要指标:
- refresh.total:总刷新计数。刷新总数的计数。
- refresh.total_time_in_millis:刷新总时间。汇总所有花在刷新的时间(以毫秒为单位进行测量)。
- merges.current_docs:目前的合并。合并目前正在处理中。
- merges.total_docs:合并总数。合并总数的计数。
- merges.total_stopped_time_in_millis。合并花费的总时间。合并段的所有时间的聚合。
主要指标梳理
- Cluster Health – Nodes and Shards
- Search Performance – Request Latency and
- Search Performance – Request Rate
- Indexing Performance – Refresh Times
- Indexing Performance – Merge Times
- Node Health – Memory Usage
- Node Health – Disk I/O
- Node Health – CPU
- JVM Health – Heap Usage and Garbage Collection
- JVM health – JVM Pool Size