hadoop_day2-本地hadoop_mapreduce开发wordcount实例,及完全分布式集群搭建
一、MapReduce的wordcount实例开发
1、在开发MapReduce的时候,使用的是myeclipse 2014,以及hadoop2.7.3的版本
2、为了方便我们对HDFS的文件的查询,我们先用myeclipse连接上文件系统,这里需要一个插件,hadoop-eclipse-plugin-2.6.0,可能对其他版本不兼容,插件链接如下
链接:https://pan.baidu.com/s/1mHJZp7dOEKxtuNX9v5U3gA 密码:gbvw
3、将此插件放入,MyEclipse安装位置下的plugins文件夹下
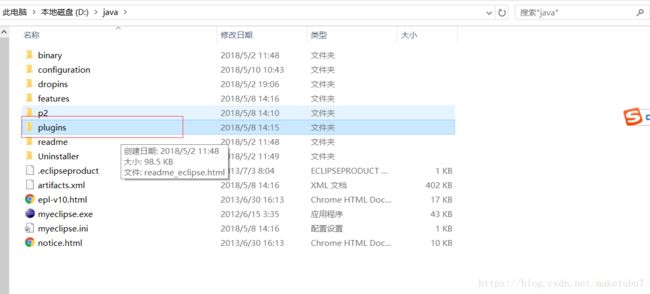
3.1然后重启MyEclipse,如果一切正常应该会在window-open perpective-other能找到一只蓝色小象
3.2、点击打开,可以在项目列表看到DFS Location的文件位置,如图
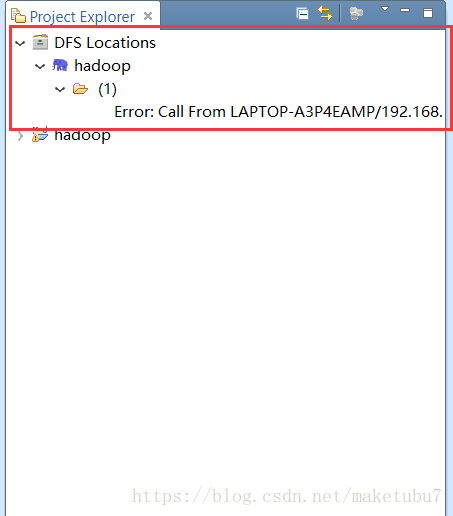
3.3、在视图窗口,右键新建HDFS链接,会弹出如下窗口
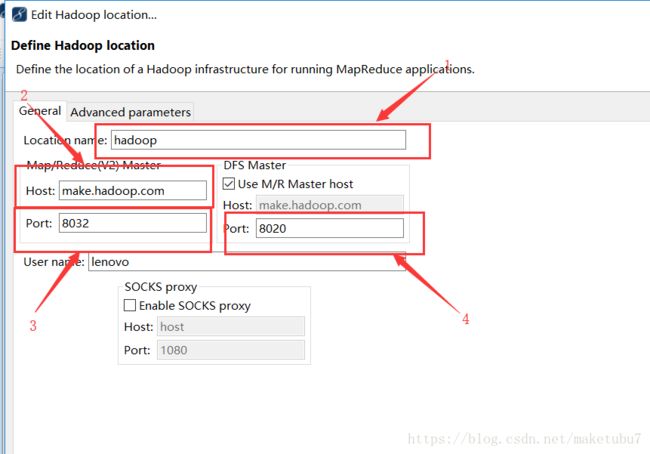
在这里1-随便写就是给个名字,23-对应的是你的yarn的haostname与其对应的端口号,如果你做过修改,这里改成和你自己的一致,4-对应的是hdfs的hostname与其对应的端口,与你自己相同的就好,到这里如果你的,hdfs的服务是开启的,应该就可以看到你的hdfs文件系统了
4、maven的配置,首先对maven的环境配置,不细说和jdk的环境配置一样一样的,截个图就OK
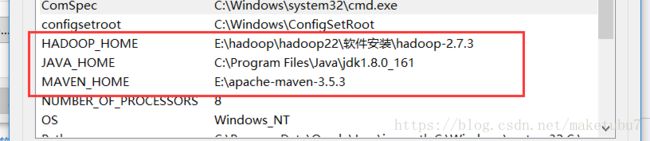
4.1、在myeclipse中设置你自己maven路径以及usersetting,如图
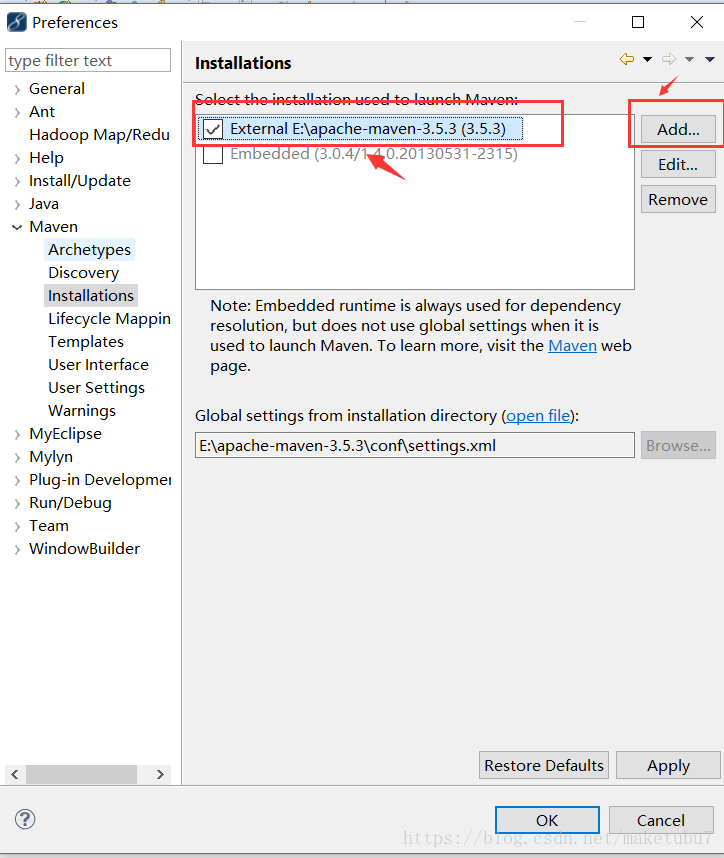

到这里,我们前面的配置基本就完成了,就可以开始新建工程,开始敲代码了!!!
5、新建一个maven工程
5.1 下面贴一段wordcount的简单代码
package make.hadoop.com.mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Mymapreduce {
// 1、自己的map类
// 2、继承mapper类,输入的key,输入的value,输出的key,输出的value
public static class MyMapper extends
Mapper {
private IntWritable MapOutputkey = new IntWritable(1);
private Text MapOutputValue = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 打印一下输入的key,value
// System.out.println("key: "+key+".......value: "+value);
// 从输入的字符串里,读取数据
String strs = value.toString();
// 分割数据
String[] str_i = strs.split(" ");
// 循环把value存入text输入下一环节
for (String str : str_i) {
MapOutputValue.set(str);
System.out.println("map的输出 key: " + str);
context.write(MapOutputValue, MapOutputkey);
}
}
}
// 1.5 自己的combiner类,map的聚合
public static class Mycombiner extends
Reducer {
IntWritable countvalue = new IntWritable(1);
@Override
// map类的map方法的数据输入到reduce类的group方法中,得到,再将这个数据输入到reduce方法中
protected void reduce(Text inputkey, Iterable inputvalue,
Context context) throws IOException, InterruptedException {
// 得到了key值
// String key = inputkey.toString();
// 查看得到的key值
// System.out.println("key......."+inputkey);
// 通过迭代Iterable得到总数
int sum = 0;
for (IntWritable i : inputvalue) {
System.out.println(i.get());
sum = sum + i.get();
}
// System.out.println("key: "+inputkey + "...."+sum);
countvalue.set(sum);
context.write(inputkey, countvalue);
}
}
// 2、自己的reduce类,这里的输入就是map方法的输出
public static class MyReduce extends
Reducer {
IntWritable countvalue = new IntWritable(1);
@Override
// map类的map方法的数据输入到reduce类的group方法中,得到,再将这个数据输入到reduce方法中
protected void reduce(Text inputkey, Iterable inputvalue,
Context context) throws IOException, InterruptedException {
// 得到了key值
// String key = inputkey.toString();
// 查看得到的key值
// System.out.println("key......."+inputkey);
// 通过迭代Iterable得到总数
int sum = 0;
for (IntWritable i : inputvalue) {
System.out.println(i.get());
sum = sum + i.get();
}
// System.out.println("key: "+inputkey + "...."+sum);
countvalue.set(sum);
context.write(inputkey, countvalue);
}
}
// 3运行类,run方法,在测试的时候使用main函数,调用这个类的run方法来运行
/**
* param args 参数是接受main方得到的参数,在run中使用
*/
/*
* public int run(String[] args) throws Exception {
*
* Configuration configuration = new Configuration();
*
* Job job = Job.getInstance(configuration, this.getClass()
* .getSimpleName()); job.setJarByClass(Mymapreduce.class);
*
* // set job // input Path inpath = new Path(args[0]);
* FileInputFormat.addInputPath(job, inpath);
*
* // output Path outPath = new Path(args[1]);
* FileOutputFormat.setOutputPath(job, outPath);
*
* //设置wordCountJob所用的mapper、reducer逻辑类为哪个类 //设置map输出的最终类型
* job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class);
* job.setMapOutputValueClass(IntWritable.class);
*
* // //设置wordCountJob所用的mapper、reducer逻辑类为哪个类 //设置reduce输出的最终类型
* job.setReducerClass(MyReduce.class); job.setOutputKeyClass(Text.class);
* job.setOutputValueClass(IntWritable.class);
*
* // submit job -> YARN boolean isSuccess = job.waitForCompletion(true);
* return isSuccess ? 0 : 1; } public static void main(String[] args) throws
* Exception {
*
* /*args = new String[] { "hdfs://make.hadoop.com:8020/make/test1.txt",
* "hdfs://make.hadoop.com:8020/out6" };
*
* // 运行job int status = new Mymapreduce().run(args);
*
* System.exit(status); }
*/
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job wordCountJob = Job.getInstance(conf, "wordcount");
// 重要:指定本job所在的jar包
wordCountJob.setJarByClass(Mymapreduce.class);
// 设置wordCountJob所用的mapper逻辑类为哪个类
wordCountJob.setMapperClass(MyMapper.class);
// 设置wordCountJob所用的reducer逻辑类为哪个类
wordCountJob.setReducerClass(MyReduce.class);
// 设置combiner的逻辑类是哪一个
wordCountJob.setCombinerClass(Mycombiner.class);
// 设置map阶段输出的kv数据类型
wordCountJob.setMapOutputKeyClass(Text.class);
wordCountJob.setMapOutputValueClass(IntWritable.class);
// 设置最终输出的kv数据类型
wordCountJob.setOutputKeyClass(Text.class);
wordCountJob.setOutputValueClass(IntWritable.class);
// 设置要处理的文本数据所存放的路径
Path inpath = new Path("hdfs://make.hadoop.com:8020/make/test1.txt");
FileInputFormat.setInputPaths(wordCountJob, inpath);
Path outpath = new Path("hdfs://make.hadoop.com:8020/wordout5");
FileOutputFormat.setOutputPath(wordCountJob, outpath);
// 提交job给hadoop集群
wordCountJob.waitForCompletion(true);
}
} 上面代码被注释掉的是写的另一种主类方法,结果是一样的,可以参考,接下来是报错的处理信息,我直接从另外一个贴过来
第一种类型、出现各种空指针:
例如:Exception in thread "main" java.lang.NullPointerException atjava.lang.ProcessBuilder.start(Unknown Source)
An internal error occurred during: "Map/Reducelocation status updater".java.lang.NullPointerException
如果出现这样的问题,就是上文的配置你没配置好,好好检查下!!!!然后在hdfs上创建目录,上传文件试试,如果配置好了,应该不会有这样的问题
第二种类型、需要修改源码型:
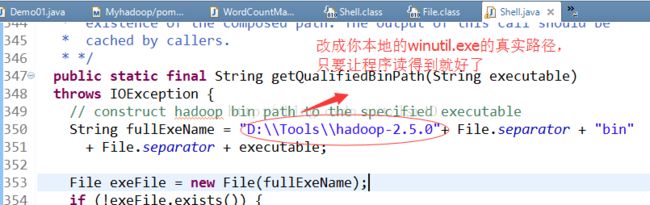
1、Failed to locate the winutils binary in the hadoop binary path java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
一开始看到这样的报错,我是拒绝的!!这里其实是因为在Windows下面运行mr代码必须有个文件叫做winutil.exe,默认解压的hadoop的bin目录下是没有的,自己下载一个然后放到hadoop目录的bin当中,程序会根据HADOOP_HOME找到bin目录下面的winutil.exe,但是有时候其实你都配置好了,它还报这个错,我就想打爆他的狗头,这时候就要修改源码了(看看源码是哪里获取的,你去手动写一个你正确的路径)
那么到底在源码的哪里呢?
在hadoop-common-2.5.0.jar这个jar包当中的org.apache.hadoop.util.Shell这个类里面
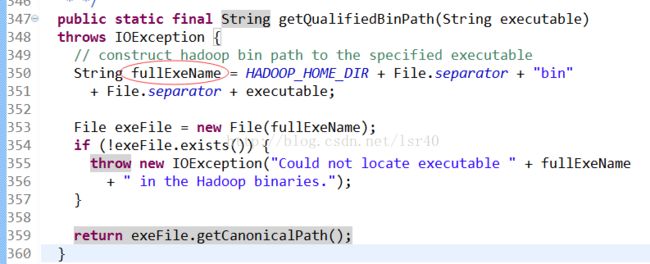
就是这个属性,修改下!!那怎么改,有个很简单的方法,Ctrl+A(全选),然后Ctrl+C(复制),把整个类复制下来,然后看下图!
点击画红圈的地方,Ctrl+V粘贴进去,他会自动生成想源码那样的包,然后直接改这个生成的java类,把350行改成:
第三种类型、修改配置文件
1、org.apache.hadoop.security.AccessControlException:
Permissiondenied: user=test, access=WRITE,inode="/user/root/output":root:supergroup:drwxr-xr-x
这里的问题是权限问题!
两种解决方法:
第一:使用命令 bin/hdfs dfs -chmod -R 777 / 这个就是将HDFS上面的所有目录都给777的权限,所有人都可以访问
第二:etc/hadoop下的hdfs-site.xml添加
dfs.permissions.enabled
false
然后重启hadoop,在运行应该就没问题了
2、Error: java.lang.RuntimeException: java.lang.ClassNotFoundException:
Class com.ibeifeng.cm.MapReduce$WordMap not found
- at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:1905)
- at org.apache.hadoop.mapreduce.task.JobContextImpl.getMapperClass(JobContextImpl.java:186)
- at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:722)
- at org.apache.hadoop.mapred.MapTask.run(MapTask.java:340)
- at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:168)
- at java.security.AccessController.doPrivileged(Native Method)
- at javax.security.auth.Subject.doAs(Subject.java:422)
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1614)
- at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:163)
- Caused by: java.lang.ClassNotFoundException: Class com.ibeifeng.cm.MapReduce$WordMap not found
- at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:1811)
- at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:1903)
- ... 8 more
这个报错其实很坑的,检查了好久,看不出来,最后终于找到:
因为新建项目的时候,其实有这个,请看下图:
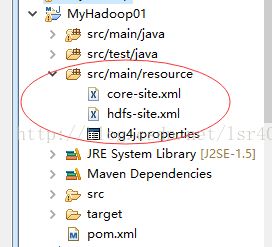
请注意:这里只能添加这3个,如果把yarn-site.xml也copy进来,那样你运行的时候,就会报如上的错误,因为你在mapred-site.xml当中指定了job运行于yarn,(其实你在本地运行的时候,应该是local模式的)你运行的时候,程序去yarn上面找对应的jar,class等信息,结果没找到所以。。。
两种解决方法:
1、把你src/main/resource中,mapred-site.xml这个yarn的值,改成local,就是下图的这个属性!!

2、把yarn-site.xml和mapred-site.xml这两个配置文件从src/main/resource中删除!就不会报这个错误了!!