记一次用pyspark 对地理数据的的索引距离判定
1、接到一次需求,需要对源手机的定位数据,来判定是否处于景区和商圈的范围内,来宏观统计消费流量
2、最开始,正常的想法,我需要对每条数据的经纬度和列表的经纬度做一次距离判定,判断该手机定位是否是属于某一个地方,如果是则对其进行保留,不是进行过滤,但是由于数据量巨大,每天的数据量约为80亿条,及每一条数据的经纬度都要做130次经纬度的距离计算,可以想象 这个计算量是非常巨大的,尝试跑了一下,但是非常耗时,于是想在网上找了下资料,知道有一种地理位置索引编码叫做geohash算法,如下
3、geohash原理
下面来正式介绍GeoHash算法。
GeoHash是一种通用的地理编码算法,是由Gustavo Niemeyer发明的,简言之,它可以将地理经纬度坐标编码为由字母和数字所构成的短字符串。它具有如下特性:
层级空间数据结构,将地理位置用矩形网格划分,同一网格内地理编码相同;
可以表示任意精度的地理位置坐标,只要编码长度足够长;
编码前缀匹配的越长,地理位置越邻近。
例如下图对北京中关村软件园附近进行6位的GeoHash编码结果,9个网格相互邻近且具有相同的前缀wx4ey。
那么GeoHash算法是怎么对经纬度坐标进行编码的呢?总的来说,它采用的是二分法不断缩小经度和纬度的区间来进行二进制编码,最后将经纬度分别产生的编码奇偶位交叉合并,再用字母数字表示。举例来说,对于一个坐标116.29513,40.04920的经度执行算法:
将地球经度区间[-180,180]二分为[-180,0]和[0,180],116.29513在右区间,记1;
将[0,180]二分为[0,90]和[90,180],116.29513在右区间,记1;
将[90,180]二分为[90,135]和[135,180],116.29513在左区间,记0;
递归上述过程(左区间记0,右区间记1)直到所需要的精度,得到一串二进制编码11010 01010 11001。
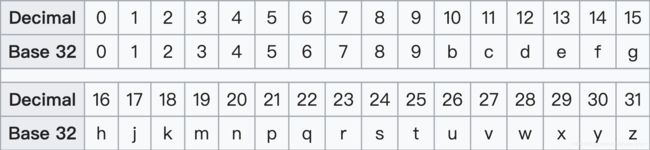
同理将地球纬度区间[-90,90]根据纬度40.04920进行递归二分得到二进制编码10111 00011 11010,接着生成新的二进制数,它的偶数位放经度,奇数位放纬度,得到11100 11101 00100 01101 11110 00110,最后使用32个数字和字母(字母去掉a、i、l、o这4个)进行32进制编码,即先将二进制数每5位转化为十进制28 29 4 13 30 6,然后对应着编码表进行映射得到wy4ey6。
对这样的GeoHash编码大小排序后,是按照Z形曲线来填充空间的,后来又衍生出多种填充曲线且具有多种特性,由于没有Z形曲线简单通用,这里就不赘述了。下表是GeoHash的编码长度与网格大小以及距离精度的关系,对于我们第一节讨论的匹配附近2公里的车辆,使用编码长度为5就可以了,如果需要更精细的匹配,可以在GeoHash匹配的结果上进行进一步的距离筛选。

因为,有这个算法,时间上来说还是大大节省了不少,之前一天的数据要跑几个小时,改了方法后,时间缩短到40分钟,但是仍然是比较长的,各种调参,也没找着很好的优化策略,
这里发现一个小的方法,就是在我们使用geohash这个算法时,我们的集群pyspark是没有这个模块的,需要通过
sparkContext.addFile('hdfs:///file_location'),先得来把你得zip包先提交到hdfs上,通过addFile方法,来申明这里也是我们的环境参数,于是在excutor执行时找不到,会自己去这个文件位置取,然后进行运算
# encoding=utf-8
from __future__ import division
import sys, os
from pyspark import SparkConf
from pyspark.sql import SparkSession
# from pyspark.sql import functions as fun
from pyspark.sql.functions import *
from pyspark.sql.types import *
from pyspark.sql.window import Window
import time, copy, re, math
from datetime import datetime, timedelta, date
from functools import reduce
from collections import OrderedDict
import itertools
from hashlib import md5
import json
import decimal
from math import sin, asin, cos, radians, fabs, sqrt
import logging
# from pandas import *
builtin = __import__('__builtin__')
abs = builtin.abs
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
logger = logging.getLogger(__name__)
reload(sys)
sys.setdefaultencoding('utf-8')
warehouse_location = '/user/hive/warehouse/'
conf = SparkConf().set('spark.driver.maxResultSize', '10g')
conf.set('spark.yarn.executor.memoryOverhead', '30g')
conf.set('spark.yarn.am.cores', 5)
conf.set('spark.executor.memory', '50g')
conf.set('spark.executor.instances', 75)
conf.set('spark.executor.cores', 8)
conf.set("spark.sql.shuffle.partitions",1500)
# conf.set("spark.default.parallelism",1500)
conf.set('spark.executor.extraJavaOptions', '-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseG1GC')
conf.set("spark.sql.warehouse.dir", warehouse_location)
spark = SparkSession \
.builder \
.config(conf=conf) \
.enableHiveSupport() \
.getOrCreate()
spark.sparkContext.addPyFile('hdfs:///user/bbd/dev/qindong/my_geohash.zip')
import geohash
from common import *
commonUtil = CommonUdf(spark)
hive_cp = 2018
path_prefix = '/user/bbd/dev/qindong/jz/'
def write_parquet(df, path):
'''写parquet'''
df.write.mode("overwrite").parquet(os.path.join(path_prefix, "parquet/", path))
def read_parquet(path):
'''读 parquet'''
df = spark.read.parquet(os.path.join(path_prefix, 'parquet/', path))
return df
def write_csv(df, path, header=False, delimiter='\t'):
'''写csv'''
df.write.mode("overwrite").csv(os.path.join(path_prefix, 'csv/', path), header=header, sep=delimiter, quote='"', escape='"')
def read_csv(path, schema, delimiter='\t'):
''' 读csv文件 '''
df = spark.read.csv(os.path.join(path_prefix, "csv/", path), schema=schema, sep=delimiter)
return df
schema = StructType([
StructField("gps_lat", StringType(), True),
StructField("gps_lng", StringType(), True),
StructField("google_lat", StringType(), True),
StructField("google_lng", StringType(), True),
StructField("location", StringType(), True),
StructField("name", StringType(), True),
])
def format_age(sfzh):
''' 根据身份证返回年龄 '''
try:
sfzh = sfzh.strip()
if len(sfzh) == 18:
csrq = int(sfzh[6:10])
age = 2019 - csrq
return age
else:
return 0
except:
pass
return 0
def hav(theta):
s = sin(theta / 2)
return s * s
def get_geohash(lat, lng, precision=6):
lat = float(lat)
lng = float(lng)
code = geohash.encode(lat, lng, precision)
return code
#商圈景区经纬度
li_view = {1:(29.594841,106.5214005,'wm78rg'),
2:(29.53596497,106.5123062,'wm78p8'),
3:(29.57569885,106.5733948,'wm7b30'),
5:(29.60033035,106.4996185,'wm78rk'),
6:(29.64196777,106.5484772,'wm7b8s'),
7:(29.52266312,106.5717697,'wm5zcn'),
8:(29.59950066,106.4891357,'wm78rh'),
9:(29.54494286,106.5888443,'wm7b16'),
10:(29.56221581,106.5789948,'wm7b1m'),
11:(29.57812691,106.5862961,'wm7b32'),
12:(29.57802391,106.5337906,'wm7b20'),
13:(29.57056999,106.5601654,'wm7b0z'),
14:(29.57028961,106.4977722,'wm78pr'),
15:(29.55892754,106.5779114,'wm7b1j'),
16:(29.61834526,106.5045242,'wm78rx'),
17:(29.55882645,106.5763626,'wm7b1j'),
18:(29.66465378,106.5608749,'wm7bbb'),
19:(29.6088047,106.5089645,'wm78rw'),
20:(29.60842705,106.2934647,'wm786y'),
21:(29.54308128,106.4740906,'wm78nf'),
22:(29.62797737,106.5335999,'wm7b81'),
23:(29.59466362,106.5206375,'wm78rg'),
24:(29.57148743,106.5716782,'wm7b1p'),
25:(29.57847977,106.54496,'wm7b22'),
26:(29.62204552,106.4753189,'wm78wb'),
27:(29.57389069,106.2404175,'wm781x'),
28:(29.55589294,106.5751038,'wm7b1h'),
29:(29.59815407,106.5222244,'wm78ru'),
30:(29.50613403,106.5162888,'wm5xzg'),
31:(29.5759449,106.5346756,'wm7b22'),
32:(29.55814171,106.5769272,'wm7b1h'),
33:(29.68911743,106.6015854,'wm7bcu'),
34:(29.55409241,106.5715256,'wm7b1h'),
35:(29.51082611,106.5174637,'wm5xzu'),
36:(29.57436943,106.5342712,'wm7b0p'),
37:(29.57852364,106.5312119,'wm7b20'),
38:(29.55319595,106.509407,'wm78pe'),
39:(29.60128021,106.5989685,'wm7b3s'),
40:(29.71186256,105.7110596,'wm71j8'),
41:(31.22267914,109.8650055,'wmw1s5'),
42:(29.04945755,107.1279449,'wmhjmb'),
43:(28.88797951,106.9982147,'wmhh6f'),
44:(28.86104774,108.7662354,'wmjk5j'),
45:(29.49711037,107.7389603,'wmhxg9'),
46:(28.61634064,106.390892,'wm5duc'),
47:(30.67636299,109.0140381,'wmmw88'),
48:(29.27522659,106.2605972,'wm5wd1'),
49:(30.42014503,108.1916122,'wmkvjc'),
50:(29.56155586,106.554039,'wm7b0t'),
51:(29.56767082,106.4278946,'wm78jy'),
52:(29.83379936,106.3817749,'wm79sz'),
53:(29.57217979,106.4423676,'wm78np'),
54:(29.55544472,106.6291733,'wm7b4k'),
55:(29.29112053,105.9083252,'wm5qdh'),
56:(29.55402565,106.4992294,'wm78pk'),
57:(29.78302956,107.798378,'wmk9mj'),
58:(30.90995789,108.704216,'wmmrcd'),
59:(29.64389801,108.7415924,'wmm2dk'),
60:(29.56688881,106.5879517,'wm7b1q'),
61:(29.55781174,106.586853,'wm7b1k'),
62:(29.58145523,106.4497986,'wm78q3'),
63:(29.85893631,106.8348999,'wm7cz5'),
64:(29.56205559,106.5504608,'wm7b0t'),
65:(29.56192398,106.5783005,'wm7b1j'),
66:(29.55850792,106.5261307,'wm7b0h'),
67:(29.49967003,106.2821045,'wm5xfd'),
68:(29.50395203,106.5058823,'wm5xze'),
69:(29.44965744,106.3643951,'wm5xs3'),
70:(29.57217216,106.5779953,'wm7b1p'),
71:(29.57212257,106.5324097,'wm7b0p'),
72:(29.48803139,106.4442749,'wm5xy0'),
73:(28.91946793,108.3517151,'wmjh98'),
74:(29.55580902,106.6139297,'wm7b4h'),
75:(30.18967056,108.3823547,'wmm5dr'),
76:(30.18230247,105.8050156,'wm75xw'),
77:(29.49216652,106.2944794,'wm5xfb'),
78:(30.65326309,108.2530746,'wmkyrk'),
79:(29.91559219,107.2405701,'wmk60m'),
80:(31.18979836,108.4138794,'wmt17j'),
81:(31.54327011,109.0835114,'wmte6q'),
82:(28.75422668,108.9683075,'wmj7xd'),
83:(29.71216774,107.3924255,'wmk35b'),
84:(29.5610199,106.5460129,'wm7b0t'),
85:(29.3678894,105.9026947,'wm5r1f'),
86:(29.15091133,108.1206818,'wmhvu6'),
87:(30.00382042,106.3126373,'wm7den'),
88:(29.60618973,106.682785,'wm7b7t'),
89:(30.02258492,106.6181335,'wm7ff1'),
90:(29.85761833,107.0662994,'wmk1u7'),
91:(30.93219757,108.7072906,'wmmrcx'),
92:(29.68033981,106.5526733,'wm7bbe'),
93:(29.55423737,106.2244339,'wm781h'),
94:(30.73953056,109.4826736,'wmmyg7'),
95:(31.07420158,109.8865204,'wmw0u8'),
96:(29.98851013,106.0288239,'wm76se'),
97:(30.18797493,105.8108749,'wm75xz'),
98:(29.4900589,107.5792236,'wmhxb0'),
99:(29.29940414,108.7731476,'wmjqej'),
100:(31.17863083,108.4658737,'wmt1k5'),
101:(29.48931694,105.6456528,'wm5pu0'),
102:(29.55308342,106.5097427,'wm78pe'),
103:(29.4848938,106.4512558,'wm5xwr'),
104:(30.1742382,106.4944763,'wm7exm'),
105:(29.30483437,108.7437592,'wmjqdw'),
106:(29.53843307,107.5934982,'wmk803'),
107:(29.62511635,107.6684647,'wmk8d1'),
108:(29.79516983,106.0464935,'wm73t0'),
109:(29.40148926,106.7700577,'wm5zm8'),
110:(29.20398903,106.2479858,'wm5w1s'),
111:(31.72506523,109.1442566,'wmts7x'),
112:(29.31637001,108.1280289,'wmhyu8'),
113:(30.24424362,108.2032547,'wmkun1'),
114:(29.50660706,108.8159637,'wmjru5'),
115:(29.81908989,106.407692,'wm79tk'),
116:(29.52758598,106.935318,'wmhpcr'),
117:(29.85761833,107.0662994,'wmk1u7'),
118:(30.58888626,107.7243118,'wmkw52'),
119:(29.65235901,108.6861038,'wmm29n'),
120:(29.57885551,106.587059,'wm7b32'),
121:(29.20556068,108.0430832,'wmhy4s'),
122:(29.54347038,106.4398727,'wm78n4'),
123:(29.68488884,106.8221207,'wm7byg'),
124:(29.10599136,108.6659393,'wmjm8f'),
125:(31.07819939,109.9319305,'wmw0v9'),
126:(29.55783653,106.5828094,'wm7b1k'),
127:(29.37404823,108.7860641,'wmjr57'),
128:(28.95664406,106.6072693,'wm5u9z'),
129:(29.88618851,107.7255325,'wmkd52'),
130:(31.04103279,109.575386,'wmtbt6'),
131:(29.46121216,106.8651123,'wm5zxg'),
132:(29.82650185,106.4159851,'wm79tt')}
#广播小数据集,景区商圈经纬度机器geohash值
bro_view = spark.sparkContext.broadcast(li_view)
view= bro_view.value
def get_distance(lat0, lng0, lat1, lng1):
''' 计算经纬度距离 '''
EARTH_RADIUS = 6371.393
lng0 = radians(lng0)
lat0 = radians(lat0)
lat1 = radians(lat1)
lng1 = radians(lng1)
dlng = fabs(lng0 - lng1)
dlat = fabs(lat0 - lat1)
h = hav(dlat) + cos(lat0) * cos(lat1) * hav(dlng)
distance = 2 * EARTH_RADIUS * asin(sqrt(h)) * 1000
return distance
def get_id(lat0, lng0):
''' 得到符合条件的商圈id '''
try:
lat0 = float(lat0)
lng0 = float(lng0)
phone_code = get_geohash(lat0, lng0)
p5_code = phone_code[:5]
index = 0
# data (lat, lng, view_code)
for id, data in view.items():
lat1,lng1,view_code = data
if phone_code == view_code:
distance = get_distance(lat0, lng0, lat1, lng1)
if distance <= 500:
index = id
break
# 扩大范围与前五位做比较 相同则比较周围8个邻居,没有则pass
elif p5_code == view_code[:5]:
neighbors = geohash.neighbors(phone_code)
if view_code in neighbors:
distance2 = get_distance(lat0, lng0, lat1, lng1)
if distance2 <= 500:
index = id
break
else:
pass
return index
except:
return 0
def verify_hour(timestamp):
''' 判断是否处于商圈活动区间 9-21 '''
try:
if timestamp:
hour = time.localtime(timestamp)[3]
if hour >=9 and hour <=21:
return 1
else:
return 0
except:
return 0
spark.udf.register("get_id", get_id, IntegerType())
spark.udf.register("verify_hour", verify_hour, IntegerType())
spark.udf.register("format_age", format_age, IntegerType())
spark.udf.register("get_geohash", get_geohash, StringType())