python处理优化自己的目标检测数据集
最近跑yolo的时候得到一批Penn-Fudan的行人数据集,想着处理优化后变成自己的数据放到yolo里面,会对模型的训练质量有提高。
这份数据集是开源的,需要的同学可以直接在网上搜索到。
希望能提供一些思路,如果觉得有用欢迎赞我表扬我~
首先看看拿到的数据集是什么样子的。
图片为png彩图,无固定尺寸:

标签label是txt格式,里面包含的信息如下:
# Compatible with PASCAL Annotation Version 1.00
Image filename : "PennFudanPed/PNGImages/FudanPed00001.png"
Image size (X x Y x C) : 559 x 536 x 3
Database : "The Penn-Fudan-Pedestrian Database"
Objects with ground truth : 2 { "PASpersonWalking" "PASpersonWalking" }
# Note there may be some objects not included in the ground truth list for they are severe-occluded
# or have very small size.
# Top left pixel co-ordinates : (1, 1)
# Details for pedestrian 1 ("PASpersonWalking")
Original label for object 1 "PASpersonWalking" : "PennFudanPed"
Bounding box for object 1 "PASpersonWalking" (Xmin, Ymin) - (Xmax, Ymax) : (160, 182) - (302, 431)
Pixel mask for object 1 "PASpersonWalking" : "PennFudanPed/PedMasks/FudanPed00001_mask.png"
# Details for pedestrian 2 ("PASpersonWalking")
Original label for object 2 "PASpersonWalking" : "PennFudanPed"
Bounding box for object 2 "PASpersonWalking" (Xmin, Ymin) - (Xmax, Ymax) : (420, 171) - (535, 486)
Pixel mask for object 2 "PASpersonWalking" : "PennFudanPed/PedMasks/FudanPed00001_mask.png"
可以看到有size,目标框的个数和位置坐标等等一些有用的信息,可以根据这些来制作我们需要的yolo格式的数据集。
基于以上数据集,我需要完成的任务如下:
1.图像变灰度,格式转换为jpg;
2.提取标注文件中的坐标,然后换算成标准的格式,保存成两个版本,一个是yolo训练格式,第一行种类,后面4列分别是归一化的框中心点坐标和宽度和高度;第二个版本,就是标准txt格式,第一列种类,然后是xmin ymin w h;只有行人,种类都给成0;
3. 每张图像的尺寸都不一样,根据图像中标注框的大小,将每张图像都裁剪成4:3的比例,同时修改标注文件中对应的标注框的坐标。
于是构建如下代码:
首先利用glob遍历所有文件,然后利用cv转换图片色彩。
至于提取标注文件中的信息,在这里利用了re的findall方法,十分方便~
然后就是对提取出来的坐标值一顿矩阵处理,成为想要的形式。
第三步的裁剪成4:3就稍微复杂一点,需要区分几种不同情况来进行处理,首先区分图片的长宽比,是大于3:4还是小于3:4,说明一下这里我把图片里的所有标注框都拿出来,给定一个正好能够覆盖这些标注框的大标注框,基于这个大标注框来对图片进行裁剪,当长宽比大于0.75的时候,即图像为竖图,这时候从图像底部往上开始裁剪,当遇到大标注框,裁剪暂停,变成从图片上部开始往下裁剪,当遇到大标注框,再从图像底部(这个时候也是大标注框的底部)开始裁剪,将大标注框的底部也一并裁剪掉,因为人的下半身数据相对于上半身没那么重要,直到达到4:3的要求,如果把一个框全部裁掉了,则在数据集中去掉这个框的信息,这样的方式裁剪,能让相对应的标注框的坐标变换变得简单一点。长宽比小于0.75的时候类似,这时为横图,从左到右处理,一样的,只是中间有一个条件太麻烦了,而满足这样条件的图片又很少,所以干脆丢掉这一部分图片,哈哈偷懒了。
描述的可能不太能够细致准确表达,结合看代码的话应该能提供清晰的思路。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from skimage import io,color
import glob
import os
import re
import numpy as np
from numpy import *
import cv2 as cv
pngpath='D:\\PNGImages\\'#原始png
opngpath='D:\\crop\\greyjpg\\'#裁剪输出jpg彩图路径
oritxt='D:\\行人数据集\\行人数据集\\PennFudanPed\\Annotation\\'#原始txt
newtxt='D:\\crop\\yolotxt\\'#裁剪输出txt保存路径
txtfiles=glob.glob(r'%s\*.txt' %oritxt)#获取所有txt文件
for txtpath in txtfiles:#对每个txt操作
txtname=os.path.basename(txtpath)[:-4]#获取txt文件名
f1 = open(oritxt+txtname+'.txt','r')#打开原始txt文件
ipng=cv.imread(pngpath+txtname+'.png',0)#读取原始png,可设定灰度图或彩图
matrix=[]#保存坐标值
for line in f1.readlines():#逐行操作,即对每个框操作
if re.findall('Image size',line):#获取图片size
size1=[int(x) for x in re.findall(r"\d+",line)]#提取w和h
if re.findall('Xmin',line): #查找包含坐标的line
line2=[int(x) for x in re.findall(r"\d+",line)]#提取坐标
matrix.append(line2)
size=size1
w=size[0]
h=size[1]
b=np.array(matrix)#原始坐标矩阵
b[:,0]=0#种类都为0
#提取所有框的范围
ymax=b[:,4].max()
xmax=b[:,3].max()
ymin=b[:,2].min()
xmin=b[:,1].min()
#裁剪后的值
oh=int(3*w/4)
ow=int(4*h/3)
#裁剪:竖图
if h/w>0.75:
if oh=ymin:
opng=ipng[ymin:(ymin+oh+1),:]#裁剪
for c in range(len(b)):
box_ymax=b[c,4]
box_ymin=b[c,2]
if box_ymax>(oh+ymin):
if box_ymin<(oh+ymin):
b[c,4]=oh
b[c,2]=max(0,(box_ymin-ymin))
elif box_ymin>=(oh+ymin):
delete(b,c,axis=0)
elif box_ymax<=(oh+ymin):
b[c,4]=max(0,(box_ymax-ymin))
b[c,2]=max(0,(box_ymin-ymin))
elif oh>=ymax:
opng=ipng[0:oh+1,:]#裁剪
'''
#在图片中显示框以核查
for m in range(len(b)):
cv.rectangle(opng,(b[m,1],b[m,2]),(b[m,3],b[m,4]),(0,0,255))
cv.imshow("checkout", opng)
cv.waitKey(0)
'''
#保存
cv.imwrite(opngpath+txtname+'.jpg',opng,[int(cv.IMWRITE_JPEG_QUALITY), 100])
'''
#转换成标准txt
b[:,3]=b[:,3]-b[:,1]
b[:,4]=b[:,4]-b[:,2]
'''
#转换成yolotxt
b.tolist()
b=np.array(b,dtype=float)
dw=1/opng.shape[1]
dh=1/opng.shape[0]
xc=(b[:,3]+b[:,1])/2
yc=(b[:,4]+b[:,2])/2
yolow=(b[:,3]-b[:,1])
yoloh=(b[:,4]-b[:,2])
b[:,1]=xc*dw
b[:,2]=yc*dh
b[:,3]=yolow*dw
b[:,4]=yoloh*dh
np.savetxt(newtxt+txtname+'.txt', b, fmt='%d %0.6f %0.6f %0.6f %0.6f')
#裁剪:横图
if h/w<=0.75:
if ow=xmin:#可以进一步细化好麻烦呜呜呜但是这个条件的图片很少所以就不处理了直接跳过哈哈
continue
elif ow>=xmax:
opng=ipng[:,0:ow+1]#裁剪
#保存
cv.imwrite(opngpath+txtname+'.jpg',opng,[int(cv.IMWRITE_JPEG_QUALITY), 100])
'''
#转换成标准txt
b[:,3]=b[:,3]-b[:,1]
b[:,4]=b[:,4]-b[:,2]
'''
#转换成yolotxt
b.tolist()
b=np.array(b,dtype=float)
dw=1/opng.shape[1]
dh=1/opng.shape[0]
xc=(b[:,3]+b[:,1])/2
yc=(b[:,4]+b[:,2])/2
yolow=(b[:,3]-b[:,1])
yoloh=(b[:,4]-b[:,2])
b[:,1]=xc*dw
b[:,2]=yc*dh
b[:,3]=yolow*dw
b[:,4]=yoloh*dh
np.savetxt(newtxt+txtname+'.txt', b, fmt='%d %0.6f %0.6f %0.6f %0.6f')
f1.close()
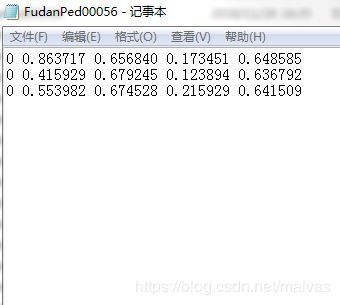
好了,看下处理完成的成品。
图片统一:

标准标签格式和yolo标签格式: