Storm(七)Storm Kafka集成
结构图
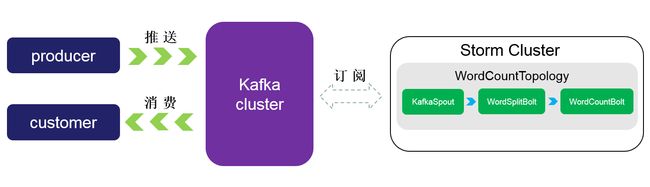
producer产生的message推送到kafka集群的topic中,再由KafkaSpout来订阅该topic中的message,并将获得的message传递给WordSplitBolt处理,WordSplitBolt处理完成后继续将message传递给WordCountBolt来处理,WordCountBolt处理完成之后可以继续往下传递,或者直接推送给kafka集群,让consumer处理。storm集群与kafka集群之间的数据可以双向传递。(kafka和storm集群的搭建网上有很多详细的参考资料,在这里就不赘述了。)
源码
pox.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>cn.com.dimensoftgroupId>
<artifactId>storm-kafkaartifactId>
<version>0.0.1-SNAPSHOTversion>
<packaging>jarpackaging>
<name>storm-kafkaname>
<url>http://maven.apache.orgurl>
<repositories>
<repository>
<id>clojars.orgid>
<url>http://clojars.org/repourl>
repository>
repositories>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
properties>
<dependencies>
<dependency>
<groupId>org.apache.stormgroupId>
<artifactId>storm-coreartifactId>
<version>0.9.5version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.twitter4jgroupId>
<artifactId>twitter4j-streamartifactId>
<version>3.0.3version>
dependency>
<dependency>
<groupId>commons-collectionsgroupId>
<artifactId>commons-collectionsartifactId>
<version>3.2.1version>
dependency>
<dependency>
<groupId>com.google.guavagroupId>
<artifactId>guavaartifactId>
<version>13.0version>
dependency>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka_2.10artifactId>
<version>0.8.2.1version>
<exclusions>
<exclusion>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.apache.stormgroupId>
<artifactId>storm-kafkaartifactId>
<version>0.9.5version>
dependency>
dependencies>
project>注:这里一定要注意将slf4j-log4j12的依赖包去除,否则topology运行的时候本地和集群都会出问题,本地报错信息如下(提交到集群错误信息也类似):
java.lang.NoClassDefFoundError: Could not initialize class org.apache.log4j.Log4jLoggerFactory
at org.apache.log4j.Logger.getLogger(Logger.java:39) ~[log4j-over-slf4j-1.6.6.jar:1.6.6]
at kafka.utils.Logging$class.logger(Logging.scala:24) ~[kafka_2.10-0.8.2.1.jar:na]
at kafka.consumer.SimpleConsumer.logger$lzycompute(SimpleConsumer.scala:30) ~[kafka_2.10-0.8.2.1.jar:na]
at kafka.consumer.SimpleConsumer.logger(SimpleConsumer.scala:30) ~[kafka_2.10-0.8.2.1.jar:na]
at kafka.utils.Logging$class.info(Logging.scala:67) ~[kafka_2.10-0.8.2.1.jar:na]
at kafka.consumer.SimpleConsumer.info(SimpleConsumer.scala:30) ~[kafka_2.10-0.8.2.1.jar:na]
at kafka.consumer.SimpleConsumer.liftedTree1$1(SimpleConsumer.scala:74) ~[kafka_2.10-0.8.2.1.jar:na]
at kafka.consumer.SimpleConsumer.kafka$consumer$SimpleConsumer$$sendRequest(SimpleConsumer.scala:68) ~[kafka_2.10-0.8.2.1.jar:na]
at kafka.consumer.SimpleConsumer.getOffsetsBefore(SimpleConsumer.scala:127) ~[kafka_2.10-0.8.2.1.jar:na]
at kafka.javaapi.consumer.SimpleConsumer.getOffsetsBefore(SimpleConsumer.scala:79) ~[kafka_2.10-0.8.2.1.jar:na]
at storm.kafka.KafkaUtils.getOffset(KafkaUtils.java:77) ~[storm-kafka-0.9.5.jar:0.9.5]
at storm.kafka.KafkaUtils.getOffset(KafkaUtils.java:67) ~[storm-kafka-0.9.5.jar:0.9.5]
at storm.kafka.PartitionManager.(PartitionManager.java:83) ~[storm-kafka-0.9.5.jar:0.9.5]
at storm.kafka.ZkCoordinator.refresh(ZkCoordinator.java:98) ~[storm-kafka-0.9.5.jar:0.9.5]
at storm.kafka.ZkCoordinator.getMyManagedPartitions(ZkCoordinator.java:69) ~[storm-kafka-0.9.5.jar:0.9.5]
at storm.kafka.KafkaSpout.nextTuple(KafkaSpout.java:135) ~[storm-kafka-0.9.5.jar:0.9.5]
at backtype.storm.daemon.executor$fn__3371$fn__3386$fn__3415.invoke(executor.clj:565) ~[storm-core-0.9.5.jar:0.9.5]
at backtype.storm.util$async_loop$fn__460.invoke(util.clj:463) ~[storm-core-0.9.5.jar:0.9.5]
at clojure.lang.AFn.run(AFn.java:24) [clojure-1.5.1.jar:na]
at java.lang.Thread.run(Thread.java:745) [na:1.7.0_75]
8789 [Thread-13-kafkaSpout] ERROR backtype.storm.util - Halting process: ("Worker died")
java.lang.RuntimeException: ("Worker died")
at backtype.storm.util$exit_process_BANG_.doInvoke(util.clj:325) [storm-core-0.9.5.jar:0.9.5]
at clojure.lang.RestFn.invoke(RestFn.java:423) [clojure-1.5.1.jar:na]
at backtype.storm.daemon.worker$fn__4694$fn__4695.invoke(worker.clj:493) [storm-core-0.9.5.jar:0.9.5]
at backtype.storm.daemon.executor$mk_executor_data$fn__3272$fn__3273.invoke(executor.clj:240) [storm-core-0.9.5.jar:0.9.5]
at backtype.storm.util$async_loop$fn__460.invoke(util.clj:473) [storm-core-0.9.5.jar:0.9.5]
at clojure.lang.AFn.run(AFn.java:24) [clojure-1.5.1.jar:na]
at java.lang.Thread.run(Thread.java:745) [na:1.7.0_75] WordCountTopology
WordCountTopology是程序运行入口,定义了完整的topology以及topology运行的方式,本地或者集群:
package cn.com.dimensoft.storm;
import cn.com.dimensoft.constant.Constant;
import storm.kafka.BrokerHosts;
import storm.kafka.KafkaSpout;
import storm.kafka.SpoutConfig;
import storm.kafka.StringScheme;
import storm.kafka.ZkHosts;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.spout.SchemeAsMultiScheme;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
/**
*
* class: WordCountTopology
* package: cn.com.dimensoft.storm
* author:zxh
* time: 2015年10月8日 下午2:06:55
* description:
*/
public class WordCountTopology {
/**
*
* name:main
* author:zxh
* time:2015年10月8日 下午2:07:02
* description:
* @param args
* @throws AlreadyAliveException
* @throws InvalidTopologyException
* @throws InterruptedException
*/
public static void main(String[] args) throws AlreadyAliveException,
InvalidTopologyException, InterruptedException {
TopologyBuilder builder = new TopologyBuilder();
// BrokerHosts接口有2个实现类StaticHosts和ZkHosts,ZkHosts会定时(默认60秒)从ZK中更新brokers的信息,StaticHosts是则不会
// 要注意这里的第二个参数brokerZkPath要和kafka中的server.properties中配置的zookeeper.connect对应
// 因为这里是需要在zookeeper中找到brokers znode
// 默认kafka的brokers znode是存储在zookeeper根目录下
BrokerHosts brokerHosts = new ZkHosts(Constant.ZOOKEEPER_STRING,
Constant.ZOOKEEPER_PTAH);
// 定义spoutConfig
// 第一个参数hosts是上面定义的brokerHosts
// 第二个参数topic是该Spout订阅的topic名称
// 第三个参数zkRoot是存储消费的offset(存储在ZK中了),当该topology故障重启后会将故障期间未消费的message继续消费而不会丢失(可配置)
// 第四个参数id是当前spout的唯一标识
SpoutConfig spoutConfig = new SpoutConfig(brokerHosts, //
Constant.TOPIC, //
"/" + Constant.TOPIC, //
"wc");
// 定义kafkaSpout如何解析数据,这里是将kafka的producer send的数据放入到String
// 类型的str变量中输出,这个str是StringSchema定义的变量名称
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
// 设置spout
builder.setSpout("kafkaSpout", new KafkaSpout(spoutConfig));
// 设置bolt
builder.setBolt("WordSplitBolt", //
new WordSplitBolt()).//
shuffleGrouping("kafkaSpout");
// 设置bolt
builder.setBolt("WordCountBolt", //
new WordCountBolt()).//
fieldsGrouping("WordSplitBolt", new Fields("word"));
// 本地运行或者提交到集群
if (args != null && args.length == 1) {
// 集群运行
StormSubmitter.submitTopology(args[0], //
new Config(), //
builder.createTopology());
} else {
// 本地运行
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("local", //
new Config(),//
builder.createTopology());
// 这里为了测试方便就不shutdown了
Thread.sleep(10000000);
// cluster.shutdown();
}
}
}WordSplitBolt
WordSplitBolt中首先获取KafkaSpout中传递过来的message,然后将其根据空格分割成一个个单词并emit出去:
/**
* project:storm-test
* file:WordBolt.java
* author:zxh
* time:2015年9月23日 下午2:29:12
* description:
*/
package cn.com.dimensoft.storm;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
/**
* class: WordSplitBolt
* package: cn.com.dimensoft.storm
* author:zxh
* time: 2015年9月23日 下午2:29:12
* description:
*/
public class WordSplitBolt extends BaseBasicBolt {
/**
* long:serialVersionUID
* description:
*/
private static final long serialVersionUID = -1904854284180350750L;
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
// 根据变量名获得从spout传来的值,这里的str是spout中定义好的变量名
String line = input.getStringByField("str");
// 对单词进行分割
for (String word : line.split(" ")) {
// 传递给下一个组件,即WordCountBolt
collector.emit(new Values(word));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 声明本次emit出去的变量名称
declarer.declare(new Fields("word"));
}
}WordCountBolt
WordCountBolt获得从WordSplitBolt中传递过来的单词并统计词频
/**
* project:storm-test
* file:WordCountBolt.java
* author:zxh
* time:2015年9月23日 下午2:29:39
* description:
*/
package cn.com.dimensoft.storm;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple;
/**
* class: WordCountBolt
* package: cn.com.dimensoft.storm
* author:zxh
* time: 2015年9月23日 下午2:29:39
* description:
*/
public class WordCountBolt extends BaseBasicBolt {
public Logger log = LoggerFactory.getLogger(WordCountBolt.class);
/**
* long:serialVersionUID
* description:
*/
private static final long serialVersionUID = 7683600247870291231L;
private static Map map = new HashMap();
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
// 根据变量名称获得上一个bolt传递过来的数据
String word = input.getStringByField("word");
Integer count = map.get(word);
if (count == null) {
map.put(word, 1);
} else {
count ++;
map.put(word, count);
}
StringBuilder msg = new StringBuilder();
for(Entry entry : map.entrySet()){
msg.append(entry.getKey() + " = " + entry.getValue()).append(", ");
}
log.info(msg.toString());
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
} Constant
Constant常量类:
/**
* project:storm-kafka
* file:Constant.java
* author:zxh
* time:2015年10月8日 下午2:06:29
* description:
*/
package cn.com.dimensoft.constant;
/**
* class: Constant
* package: cn.com.dimensoft.constant
* author:zxh
* time: 2015年10月8日 下午2:06:29
* description:
*/
public class Constant {
// 定义topic名称
public static final String TOPIC = "storm-kafka-test";
// zookeeper地址
public static final String ZOOKEEPER_STRING = "hadoop-main.dimensoft.com.cn:2181,"
+ "hadoop-slave1.dimensoft.com.cn:2181,"
+ "hadoop-slave2.dimensoft.com.cn:2181";
// broker在zookeeper中存储位置
public static final String ZOOKEEPER_PTAH = "/kafka/brokers";
}测试
创建topic
$ bin/kafka-topics.sh --create --zookeeper hadoop-main.dimensoft.com.cn:2181,hadoop-slave1.dimensoft.com.cn:2181,hadoop-slave2.dimensoft.com.cn:2181/kafka --partitions 2 --replication-factor 3 --topic storm-kafka-test查看该topic信息
$ bin/kafka-topics.sh --describe --zookeeper hadoop-main.dimensoft.com.cn:2181,hadoop-slave1.dimensoft.com.cn:2181,hadoop-slave2.dimensoft.com.cn:2181/kafka --topic storm-kafka-test
//结果
Topic:storm-kafka-test PartitionCount:2 ReplicationFactor:3 Configs:
Topic: storm-kafka-test Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: storm-kafka-test Partition: 1 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0直接在eclipse中运行WordCountTopology类,这样方便调试程序,运行完成之后使用kafka自带的producer来向storm-kafka-test这个topic推送数据
bin/kafka-console-producer.sh --broker-list hadoop-main.dimensoft.com.cn:9092,hadoop-slave1.dimensoft.com.cn:9092,hadoop-slave2.dimensoft.com.cn:9092 --topic storm-kafka-test将以下内容发送到kafka(每行数据回车一次)
hadoop is a good technology
hadoop and hbase
today is a good day 观察eclipse控制台输出
223538 [Thread-17-WordCountBolt] INFO cn.com.dimensoft.storm.WordCountBolt - hadoop = 2, is = 1, technology = 1, hbase = 1, a = 1, today = 1, good = 1, and = 1,
223538 [Thread-17-WordCountBolt] INFO cn.com.dimensoft.storm.WordCountBolt - hadoop = 2, is = 2, technology = 1, hbase = 1, a = 1, today = 1, good = 1, and = 1,
223538 [Thread-17-WordCountBolt] INFO cn.com.dimensoft.storm.WordCountBolt - hadoop = 2, is = 2, technology = 1, hbase = 1, a = 2, today = 1, good = 1, and = 1,
223538 [Thread-17-WordCountBolt] INFO cn.com.dimensoft.storm.WordCountBolt - hadoop = 2, is = 2, technology = 1, hbase = 1, a = 2, today = 1, good = 2, and = 1,
223539 [Thread-17-WordCountBolt] INFO cn.com.dimensoft.storm.WordCountBolt - hadoop = 2, is = 2, technology = 1, hbase = 1, a = 2, today = 1, good = 2, day = 1, and = 1, 注意:topology在本地运行的时候并不会在ZK中存储消费的storm-kafka-test offset,只有当将该topology提交到storm集群时才会在ZK中存储其offset。所以当该topology挂掉的时候如果producer仍然在往storm-kafka-test中推送信息的话当topology重启后这段时间所推送的信息就会丢失了。有兴趣的话可以测试一下,然后可以测试将该topology提交到storm集群,测试将topology kill掉,然后继续使用producer推送数据,然后再启动该topology,就会发现故障期间的信息在topology重启会进行消费而不会丢失。
自定义producer
上面测试的时候是使用kafka自带的producer,但是在业务场景中我们都是根据实际业务情况自定义自己的producer,其实跟上面的是相类似的,主体流程没有变化,只是将原先kafka自带的producer替换为自定义的producer,自定义的producer将message推送到storm-kafka-test这个topic即可,这样一旦有message推送过去的时候KafkaSpout就会接收到并进行处理。
SampleProducer
SampleProducer简单的从控制台读取用户输入信息并推送到kafka集群的storm-kafka-test中,然后storm通过订阅storm-kafka-test这个topic来对message进行处理:
/**
* project:kafka-study
* file:SampleProducer.java
* author:zxh
* time:2015年9月25日 下午4:05:51
* description:
*/
package cn.com.dimensoft.kafka;
import java.util.Properties;
import java.util.Scanner;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import cn.com.dimensoft.constant.Constant;
/**
* class: SampleProducer
* package: cn.com.dimensoft.kafka
* author:zxh
* time: 2015年9月25日 下午4:05:51
* description:
* step1 : 创建存放配置信息的properties
* step2 : 将properties封装到ProducerConfig中
* step3 : 创建producer对象
* step4 : 发送数据流
*/
public class SampleProducer {
@SuppressWarnings("resource")
public static void main(String[] args) throws InterruptedException {
// step1 : 创建存放配置信息的properties
Properties props = new Properties();
// 指定broker集群
props.put("metadata.broker.list", //
"hadoop-main.dimensoft.com.cn:9092,"
+ "hadoop-slave1.dimensoft.com.cn:9092,"
+ "hadoop-slave2.dimensoft.com.cn:9092");
/**
* ack机制
* 0 which means that the producer never waits for an acknowledgement from the broker
* 1 which means that the producer gets an acknowledgement after the leader replica has received the data
* -1 The producer gets an acknowledgement after all in-sync replicas have received the data
*/
props.put("request.required.acks", "1");
// 消息发送类型 同步/异步
props.put("producer.type", "sync");
// 指定message序列化类,默认kafka.serializer.DefaultEncoder
props.put("serializer.class", "kafka.serializer.StringEncoder");
// 设置自定义的partition,当topic有多个partition时如何对message进行分区
props.put("partitioner.class", "cn.com.dimensoft.kafka.SamplePartition");
// step2 : 将properties封装到ProducerConfig中
ProducerConfig config = new ProducerConfig(props);
// step3 : 创建producer对象
Producer producer = new Producer(config);
Scanner sc = new Scanner(System.in);
for (int i = 1; i <= 10; i++) {
// step4 : 发送数据流
// producer.send(new KeyedMessage(Constant.TOPIC, //
// i + "", //
// String.valueOf("我是 " + i + " 号")));
Thread.sleep(1000);
producer.send(new KeyedMessage(Constant.TOPIC, sc.next()));
}
}
} SamplePartition
SamplePartition是自定义的partition,用来对消息进行分区:
/**
* project:kafka-study
* file:SamplePartition.java
* author:zxh
* time:2015年9月28日 下午5:37:19
* description:
*/
package cn.com.dimensoft.kafka;
import kafka.producer.Partitioner;
import kafka.utils.VerifiableProperties;
/**
* class: SamplePartition
* package: cn.com.dimensoft.kafka
* author:zxh
* time: 2015年9月28日 下午5:37:19
* description: 设置自定义的partition,指明当topic有多个partition时如何对message进行分区
*/
public class SamplePartition implements Partitioner {
/**
* constructor
* author:zxh
* @param verifiableProperties
* description: 去除该构造方法后启动producer报错NoSuchMethodException
*/
public SamplePartition(VerifiableProperties verifiableProperties) {
}
@Override
/**
* 这里对message分区的依据只是简单的让key(这里的key就是Producer[K,V]中的K)对partition的数量取模
*/
public int partition(Object obj, int partitions) {
// 对partitions数量取模
return Integer.parseInt(obj.toString()) % partitions;
}
}
测试的时候直接将WordCountTopology打包提交到storm集群运行,打开storm的worker日志,然后eclipse运行SampleProducer程序,通过从eclipse控制台输入数据来观察storm的worker日志输出。
topology提交到storm集群之后可以发现ZK中存储了storm-kafka-test 被消费offset的znode,这样即使topology故障重启之后message也不会丢失

storm中work的日志输出
