推荐系统 - SR GNN架构详解(包含图神经网络GNN和门控图神经网络GGNN的介绍)
说明
1.SR-GNN是中科院提出的一种 基于会话序列建模的推荐系统,这里所谓的会话是指用户的交互过程(每个会话表示一次用户行为和对应的服务,所以每个用户记录都会构建成一张图),这里说的会话序列应该是专门表示一个用户过往一段时间的交互序列。 基于会话的推荐是现在比较常用的一种推荐方式,比较常用的会话推荐包括 循环神经网络、马尔科夫链。但是这些常用的会话推荐方式有以下的两个缺点:
(1)当一个会话中用户的行为数量十分有限时【就是比较少时】,这种方法较难捕获用户的行为表示。比如使用RNN神经网络进行会话方式的推荐建模时,如果前面时序的动作项较少,会导致最后一个输出产生推荐项时,推荐的结果并不会怎么准确。
(2)根据以往的工作发现,物品之前的转移模式在会话推荐中是十分重要的特征,但RNN和马尔科夫过程只对相邻的两个物品的单项转移向量进行 建模,而忽略了会话中其他的物品。【意思是RNN那种方式缺乏整体大局观,只构建了单项的转移向量,对信息的表达能力不够强】
2.因为SR-GNN主要基于图的思想,所以我首先详细介绍了GNN和GGNN的建模和训练过程,之后开始介绍将GNN用于会话推荐的SRGNN部分,如果已经熟悉GNN,可以直接跳过 前置知识 部分。
前置知识
1.SR-GNN主要是基于图的建模方式,对于推荐场景,我们确实能够把用户对商品项的点击序列构建成图的形式,但是当我们构建成转成图的形式后,又怎么对图结构的信息加以利用呢? 现在比较热门的基于深度学习的GNN网络就是专门用于处理图类型数据,该网络的目标是学习每个节点的 embeding表达hv【做图中结点和图的表示,映射成向量表达在加以利用做各种任务】,而该节点的表达由该节点的特征、与该节点连接的边的特征、该节点的邻居表示、它邻居节点的特征 计算得到的【说白话点,GNN会从图结构中学习到每个节点的embedding向量表示,相当于是利用了这个节点的图位置关系、节点上的相似性关系、节点交互关系 进行结点往高维空间的语义封装,获得类似word2vec那样的词向量表示】,这里的f包装函数是由GNN学习到的。

当我们获得每个节点进行封装后的embedding向量后,就可以拿向量化的结果做自己特定的任务【类似于word2ve对句子向量化后进行使用一样】,而对于关注整个图的任务,可以通过将所有节点的表示做pooling 或者其他方法获得一个全局的表示信息来做相应的任务【接下来的SR-GNN就是对整个图的信息进行利用的,因为我们是把整个会话session包装成一个图,所以对session的整体趋势预测,当然要整个图都用,只不过对session不同时间点的向量化结点,会有不同的关注度】。
这里提醒下,GNN是一类算法的统称,表示对图这种非欧几里得结构 数据的 神经网络的统称,其可以有不同的信息处理方式,可以进一步将GNN分为图卷积网络(GCN)、基于注意力更新的图网络(GAT)、基于门控更新的图网络、具有跳边的图网络,之后的文章中会进行介绍。

2.在SRGNN中所使用到的图网络是基于门控更新的图神经网络,所以在此处首先对该网络进行介绍下,内容可参照:https://zhuanlan.zhihu.com/p/28170197,接下来的内容是我个人的一些理解。
对图的介绍也可以分成两部分,首先是对传统GNN结构过程的介绍、之后是对 对应的门控更新图网络 GG-NN的介绍。
(1)首先说下GNN网络的目的,学会对图中每个结点的合适向量化表达【从图关系空间转到高维空间使用 指定长度的向量进行表达】,那如何获取表达向量呢,可以理解为三部曲:
* 首先 组织好图 数据【使用一定的方式进行存储】、
* 将图矩阵输入到图 网络中,进行传播的过程【对结点向量随时间进行更新】
* 第三步是 根据最终的结点表示得到目标输出的过程【根据训练任务,产生指定的输出,比如某个结点的类别、或者整个图的预测输出、不同的任务当然要有适应的向量转换形式】。
对应上面所说的三部曲,可以得知我们需要首先明确的东西:
* 需要确定好对图结构进行存储的形式,毕竟之后输入到图网络的信息都是从中提取出来的。
* 需要明确好自己的任务,只有明确好要做什么事情,才能让图网路知道该 如何最好的进行信息 和信息组织,所以明确好 GNN网络最后输出的意义,对于GNN生成有效果的 词向量至关重要。
* 传播过程是非常重要的,这类似于 神经网络中 的不断前向传播的过程,用于对信息不断进行 组合和包装抽取,是GNN强表达能力的保障,因此如何设计好传播层的结果 也是比较重要的。
为了形象化的理解,我们使用如下的图表达整个过程。我们来分别解释下两个图。
* 下图表示我们意义上的表达,当我们需要获取结点1的 目标向量化表达时【用符号x1表示,对符号的表示请看注释1,对数学符号的敏感对机器学习从业者的基本素质】,对其表达需要依赖的信息包括 自己和结点周围的状态xi【就是目标要获得的向量】、周围结点和本节点的边的特征Lv(i,j)、周围结点的特征Ls(i),这三部分信息【相当于预测依据,特征】,对应可以看到 左图中的fw公式,就是为了将这样的信息进行包装来学习到对结点1的目标向量化表达,这里有两个需要解释的,第一.为什么在fw式子中利用到周围结点的状态表达x(i),毕竟那些状态表达也是需要学习到的,在前期根据无法获取到,无法将其作为信息的输入,对这个理解,可以借鉴于GAN的思想,初始的x(i)是非训练的,但是我们可以在不断相互依赖和进行迭代,达到一种纳什均衡的状态,获得每个结点的合适的收敛的向量表示 x1【不断用 t轮的状态 去更新t+1轮的状态 ,最终得到全图收敛的状态,注意在传播过程中网络参数是不会变的】、此时我们是可以拿到收敛的结点的向量化表示x1的,但是这个只是收敛的结果,也无法保证这个收敛结果 是 适合当前任务的,所以需要根据真实标签 来进行梯度的计算和反向传播,因此我们会拿现在利用f函数获得的 结果向量 使用心得函数g来生成标签输出,求得损失函数,并对f函数和g函数进行参数调整,一直 到收敛、完成训练。 第二.这里的f函数 和g函数都是一个专门设定的网络结构,整体可以看做一个统一的神经网络,首先等待f函数熟练之后,使用g函数包装产生输出![]() ,算法使用 Almeida-Pineda算法完成训练【参见备注2】,根据o值和实际标签计算出损失并梯度下降。
,算法使用 Almeida-Pineda算法完成训练【参见备注2】,根据o值和实际标签计算出损失并梯度下降。
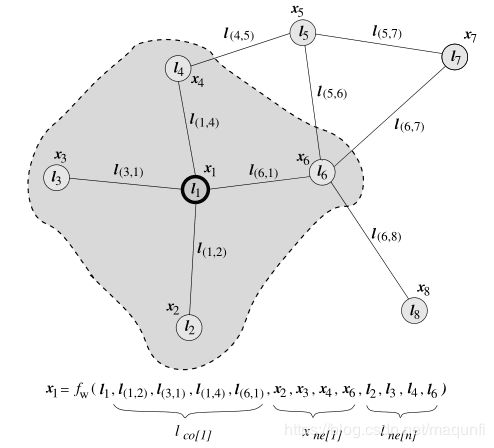
* 下图是 对整个图网络过程的整体化展示, 可以发现右侧输入的是把图中每个结点f函数可能用到的信息都作为 网络输入了, 就是与结点相连的 部分结点特征、边的特征等信息【注意最开始对周围结点的向量表示是最初始的】,之后从右由左的过程就是时序展开的,对应于针对 每个结点的向量状态表达不断收敛的过程,其中可以发现连接不同结点的线是不同的, 对线的理解可以对应到中间的图中, 这里对应于f的输入式子是需要 周围结点的状态x、自己和周围结点的特征Ls(i) 信息的,所以除了L作为输入外,还需要其他结点的状态fw 结果作为输入,所以 结点1 连接了 结点2和4、结点2连接 结点1和4 、结点3连接结点 4、结点4连接 1和2和3,也就是我们会把邻居结点 的fw结果作为 自己fw计算的输入,图中每个小块都是同一个神经网络, 网络输入的就是结点所需要的L和x信息【理解有点绕脑】,右图是对不断拟合过程的时序展开,最后达到拟合之后就可以获取到每个结点的x表示【也就是结点的向量化表示】,得到结点x向量表示后,我们会进一步输入到g网络中,获取对本任务的预测值![]() ,最后根据任务标签和预测值o计算损失,并对g和f网络梯度调整,其中两部分调整的含义是:对f网络的调整是 为了使得 f函数针对不同 结点处境 收敛出其最合适的结点应有的 向量化表达x【这也是最终的目标,我们最后需要获取这种向量化形式来做各种任务 】、对g网络的调整是对收敛效果的验证, 会根据任务误差对收敛结果进行调整。【这里注意我们只有一个f网络和g网络,下图的结构那么复杂只是因为对时序和 不同结点的处理进行了展开,只是输入和输出的意义不同罢了】
,最后根据任务标签和预测值o计算损失,并对g和f网络梯度调整,其中两部分调整的含义是:对f网络的调整是 为了使得 f函数针对不同 结点处境 收敛出其最合适的结点应有的 向量化表达x【这也是最终的目标,我们最后需要获取这种向量化形式来做各种任务 】、对g网络的调整是对收敛效果的验证, 会根据任务误差对收敛结果进行调整。【这里注意我们只有一个f网络和g网络,下图的结构那么复杂只是因为对时序和 不同结点的处理进行了展开,只是输入和输出的意义不同罢了】

(2)接下来说下GGNN网络,GGNN的特点是使用 循环神经网络 来进行信息传播, 也就是说我们把上面的f函数换成了GRU网络,GRU作为承载记忆的单元,用做信息在graph中信息的传播,具体怎么用的,我会详细介绍下传播过程的公式,总结下GRU的特点吧:
*对f函数限定为GRU单元,GRU单元的输入是 上一时刻所有结点的 向量化表达输出[h1,h2.....], 结点连接关系矩阵A,这里的A是有邻接矩阵的出度矩阵和入度矩阵构成的,用于表示节点和相邻结点间的相关作用关系,针对不同结点的时序处理,我们需要取出结点对应的矩阵上的两列Au,通过这样的[h1,h2.....]*Au对应相乘,就能在乘积过程中 通过 乘1乘0 的方式 只取出跟当前节点有关联的 上一时刻结点向量作为使用, 我觉得GNN的传播控制也是通过这样的方式来控制指点结点的输出作为输入的。
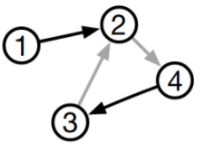
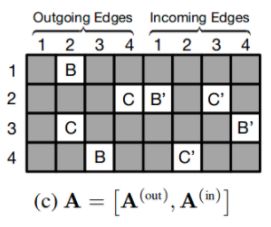
*GGNN将传播过程中结点的更新次数固定为T【传播时的时间长度,这里固定的传播时长,但是在传播结点还是需要自收敛的】,而不是之前GNN方式中是不固定的,直到自己收敛为止,通过设定固定值,使得GG-NN网络可以直接使用BPTT算法进行梯度的计算,而不是使用Almeida-Pineda算法,使用BPTT算法虽然需要更多的内存,但是它并不需要对参数进行约束【之前GNN传播过程需要约束参数到收敛,而GGNN则不需要,只要前向运行指定T步即可】。
*引入了结点标注的概念,引入的原因是因为在GNN中,结点的最终表示与结点的初始化没有多大关系,而在GGNN中,我们最后的表示形式会依赖于结点的初始状态,因此我们丰富结点的初始状态,我们引入了结点标注,注意有两个概念吧,一个是结点标签、一个是结点标注,结点标签是指使用的特征,而标注则是需要用到的额外的输入,需要根据任务做额外的标注作为输入,简单点理解的话,结点标注等同于 结点表示的初始化向量,只不过它不一定和结点表示等大,其实对于结点标注的构建很依赖实际工程,我也不算特别明白,这里就不做更多的介绍。
GGNN同GNN一样同样分为 传播模型和输出模型两个部分,这里先主要介绍下传播模型,针对于模型f,其计算过程可以分为如下从1-6的式子
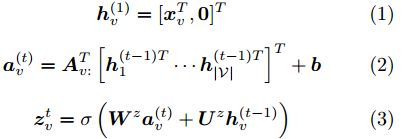
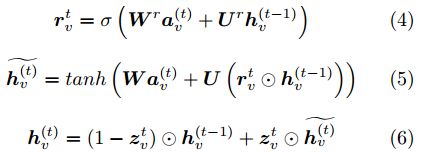
对以上六个式子,一个直观的介绍是如下的过程。

添加个人理解的话,就是我们针对每个当前处理时序的结点,(1)是对结点输入特征信息的包装、(2)是对前一时序处理的结果进行利用,这里通过Av矩阵来筛选出那些跟结点有边关联的结点向量信息 作为输入信息来使用,此时可以类比LSTM网络的思想,其中新产生的hv有点类似于新记忆、a类似对历史记忆的存储载入,之后的(3)-(6)过程对应于GRU中的控制、遗忘等信息加工过程获取得到最后GRU网络的输出hv, 从(2)-(6)的过程会持续下去,直到向量化输出收敛。
在输出模型部门,是对传播模型生成的每个结点的hv的利用,其对应两种输出,根据目标任务不同,对输出结果有两种使用方式,分别是结点单独输出 和 整个图输出 两种形式,可以看到结点单独输出和之前 讲GNN时候的差不多,而在整张图输出一个结果时候时,会比较合理了添加了对不同结点信息的注意力,更加关注那些跟最终输出更为关联的结点【接下来的SRGNN其实就是后一种添加了注意力的形式,因为其任务是对用户的下一时刻的点击项的推测】。

架构
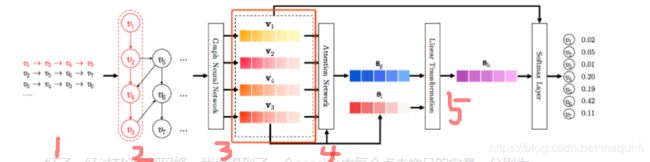
1.首先我们先整体看下架构,之后再分块解释:
(1)最左侧是我们应该输入的数据,每一行表示一个用户进行 物品点击的记录【每个会话表示了不止一行?是真的吗?队友这样解释的,但是感觉并不合理,但是如果只是一个用户的信息,好像又缺少什么一样】,v表示物品,对于每一行数据可以表示为一个会话 ,我们的目的是根据这样的用户点击序列,来预测用户下一个要点击的物品
(2)基于每个session去构建一个子图,注意是每个用户的历史情况都会构建成一个图。
(3)使用GNN网络对图进行信息的抽取挖掘,训练好GNN后,我们可以获取session图中每个点击物品的embedding_1向量化表示 [v1,v2,...,vn],其中每个Vi都是一个向量,对应下图红框中的结果。
(4)对于获得的每个物品的 向量化表示,实际上只有最后一个时刻物品是比较重要的【最后一次最能体现当前时间用户的兴趣】,我们单独将其取出为s1,而其他的信息,我们也会加以利用,但是是使用一种注意力分配的机制,添加了attention策略,根据前面几个物品跟最后一次点击的相似度,来进行注意力权值的附加,然后将这些最后一次之间的信息附加权重后加在一起,成为向量sg。
(5)最后一步是先对s1和sg进行横向拼接,并进行线性变换,得到结果sh,最后将sh与每个物品的embedding进行内积计算【这里的embedding和经过GNN网络获取到的embedding_1是有所不同的,是每个物品初始的embedding,在经过GNN处理前已经决定了,是GNN网络的初始输入】,并通过softmax包装获取得到对应不同物品的点击概率,根据概率的大小绝对最后的推荐物品。
2.针对每一块,接下来进行详细化的解释。
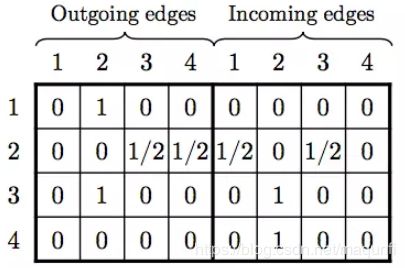
(1)首先说下把 用户的 的历史交互记录,转换成一个有向图,比如用户的点击序列是 v1->v2->v3->v2->v4,则其对应的图可以转化成如下的形式。这里为什么将每个用户的行为都包装成一个图,是因为如果将所有用户对商品的交互关系都放在一张图中,会导致对用户独特兴趣捕捉上的混乱,所以需要单独构建,而且这样构建的优势是后续训练时候,每一行样本都可以构建成一张图,还是比较方便的。

在实际实现中,我使用邻接矩阵进行图的存储,为每个图都构建一个出度矩阵、入度矩阵,并为了便于输入到神经网络,对度值进行了归一化处理,如下是对 v1->v2->v3->v2->v4序列的邻接矩阵存储形式,左边矩阵表示出度,右边矩阵表示入度,同时构建出度矩阵和入度矩阵的原因是为了让模型可以学到 丰富的双向关系,而不是简单的单向转移关系。
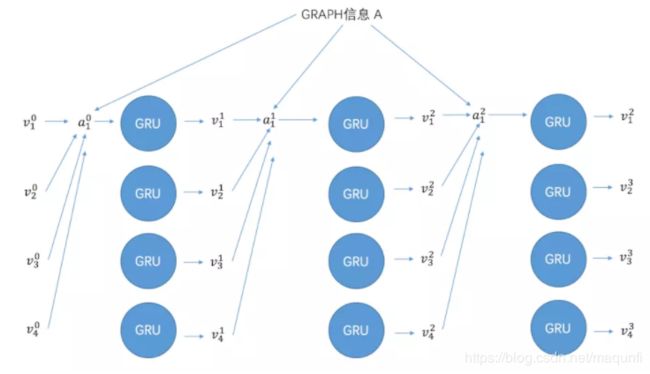
(2)接下来,使用GNN针对邻接矩阵 来学习 物品的嵌入向量的过程【其实就是传播过程中,达到一次收敛的过程,协调收敛】, 我们这里使用GNN网络是 门控图神经网络GGS-NN(Gated GNN),通过将所有的会话图送入到GGNN网络,就能够得到所有节点的嵌入向量,对于从GGNN通过GRU得到嵌入向量的过程,可以对照之前的公式,参考下面的描述,这里也是对GRU不断从前到后不断到收敛的过程,相当于传播过程,那之后的 生成会话嵌入向量和推荐决策 就对应于GNN中的输出过程。

如下的过程图也可以参照一下,下图可以这样解读,v对结点的向量化表达,下面的每一行是理解的并列的对每个结点的时序过程,时序利用数据和传播产生最终输出, 但是感觉图少了很多线,还是从公式上理解吧,下面这张图看了也许还没有不看好,仅供参考吧。
(3)生成会话嵌入向量阶段(获取对整个会话的向量表示形式)。对于整体的图,我们分为局部向量和全局向量进行考虑,从局部和全局角度进行表达来获得更有效的 图向量表达,其中,定义局部嵌入向量为会话中最后点击的物品s1=us,定义全局变量是结合所有节点嵌入向量 添加不同注意力优先级后,得到的向量表示。 这里使用了注意力机制,首先得到不同结点的注意力权重![]() ,之后对不同节点添加不同的注意力获取得到全局的向量嵌入结果,其中W1和W2都是注意力机制中可训练的权重,之后使将会话的局部嵌入向量和全局嵌入向量相结合得到融合的嵌入向量 sh=W3【s1,sg】,这里也是有权重的融合。
,之后对不同节点添加不同的注意力获取得到全局的向量嵌入结果,其中W1和W2都是注意力机制中可训练的权重,之后使将会话的局部嵌入向量和全局嵌入向量相结合得到融合的嵌入向量 sh=W3【s1,sg】,这里也是有权重的融合。

(3)最终就是推荐决策和模型训练阶段,使用得到的每个会话的嵌入向量sh和 每个候选物品计算得分z,使用softmax得到预测输出,最后可以利用真实标签结合预测输出得到 损失值,之后使用BPTT算法进行 传播和输出过程网络 的反向训练。
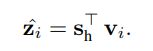
![]()
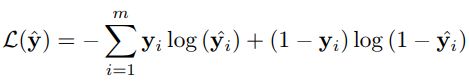
最后因为大多数会话的长度都比较短,因此训练时的迭代次数不能过多,防止训练过多导致过拟合。
备注
备注1
xi : 表示图学习的目标,对结点的向量化表示。
Lv(i) : 表示节点的特征,比如对于商品结点的话,其可以表示商品的价格等信息
Ls(i) : 表示边的特征,可以表示为商品点击先后的时间间隔等 这种连接项之间的信息。
备注2

参考资料
1.https://blog.csdn.net/yfreedomliTHU/article/details/91345348
2.https://www.jianshu.com/p/9186b2e40178
3.https://blog.csdn.net/lthirdonel/article/details/89286522