Domain Adaptation总结(2017.9)
有一篇论文([cvpr2017]Joint Geometrical and Statistical Alignment for Visual Domain Adaptation )对Domain Adaptation做了一定的总结,我直接把我当时的翻译抄一下(这里是针对判别式模型(discriminator model)的分析):
常见的域适应包括基于实例(instance-based)的适应、基于特征表示( feature representation)的适应、基于分类器(classifier-based )的适应,其中在非监督的情况下,因为没有target labels,所以基于分类器的适应是不可行的。
- 通常分布差异(distribution devergence)可以通过基于实例(instance-based)的适应,比如对source domain中的样本的权重重新加权
- 或者可以通过特征表示的方法(feature representation/transformation)的方式,将source domain和target domain的特征投影到第三个使得分布的偏差较小的domain当中。
- 基于实例(instance-based)的方法需要比较严格的假设:1)source domain和target domain的条件分布是相同的,2)source domain中的某些部分数据可以通过重新加权被重用于target domain中的学习。
- 基于特征表示(feature representation/transformation)的s适应的假设则相对来说更弱一点,仅仅假设存在一个使得source domain和target domain的分布相似的公共空间。
有两大类特征变换的方法:1)以数据为中心(data centric methods );2)以子空间为中心(subspace centric methods)
- 以数据为中心的方法(data centric methods ) 寻求一个统一的转换,将数据从source domain和target domain投影到域不变空间(domain invariant space)当中,以求减少source domain和target domain上数据的分布差异(distributional divergence),并且同时保留原始空间当中的数据属性
- 以数据为中心的方法(data centric methods )仅仅利用两个域中的共同特征(shared feature),然而当source domain和target domain的差异很大(have large discrepancy)的时候会导致失败,因为使得source domain和target domain分布一致的公共空间可能会不存在。
- 以子空间为中心的方法(subspace centric
methods)则是通过操纵两个域的子空间(比如建立线性映射,或者使用类似grassmann 这样的流形来进行映射)来减少域位移(domain shift),使得每个域的子空间都有助于最终映射的形成。 - 作者认为,以子空间为中心的方法仅在两个域的子空间上进行操作,而不用直接地考虑两个域的投影数据之间的分布偏移。(However, the subspace centric methods only manipulate on the subspaces of the two domains without explicitly considering the distribution shift between projected data of two domains.)
另外一篇论文([CVPR2017]Adversarial Discriminative Domain Adaptation)则是依据对抗性损失(Adversarial Loss)的建模方式进行分析,大致分为以下两种
- 使用生成式模型(generative model)的
- 最初的论文GAN就是典型的生成式建模,利用噪声直接生成对应标签图像,可以视为学习了类的联合分布,即生成式模型
- 域适应中比如CoGAN和下文中的Unsupervised Pixel–Level Domain Adaptation with Generative Adversarial Networks就是生成式建模
- 论文作者认为生成式模型的优点在于训练期间不需要复杂的推理和抽样(?),缺点是训练的难度可能很大,当source domain和target domain差异较大的时候,单纯使用生成式模型网络可能不收敛,并且对图像进行生成式建模是不必要的,毕竟神经网络最终学习的目的就是得到类的后验概率,即神经网络本身是个判别式模型。
- 使用判别式模型的(目前大部分的Domain Adaptation使用的是这个方法,差异也很大,不好直接归类)
- 例子:

- 使用生成式模型(generative model)的
我大致用上面的归类方法对目前的论文进行归类:
Deep Domain Confusion: Maximizing for Domain Invariance(2014)
- 点击查看笔记
- 基于特征变换-以数据为中心的方法(同一个映射)
- 采用的技术:
- maximum mean discrepancy:最大平均差异
- 模型:
- 特点:
- source domain和target domain之间参数的完全共享
- 性能:
Unsupervised Domain Adaptation by Backpropagation(2015)
- 点击查看笔记
- 基于特征变换-以子空间为中心的方法
- 适用于非监督
- 采用的技术:
- GAN loss的对抗性损失,具体实现使用的是梯度反转层GRL,其“pesudo function”表示如下:
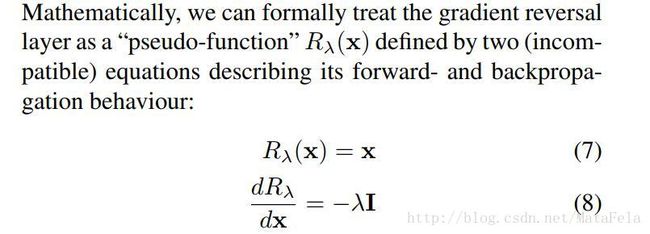
- GAN loss的对抗性损失,具体实现使用的是梯度反转层GRL,其“pesudo function”表示如下:
- 模型:
- 特点:
- 特征提取之后,在域分类器(domain classifier)之前加入了一个梯度反转层。
- 作者针对不同的数据集使用了不同的网络:

- 性能:

Beyond Sharing Weights for Deep Domain Adaptation(2016)
- 点击查看笔记
- 基于特征变换-以子空间为中心的方法
- 适用于非监督和半监督
- 采用的技术:
- maximum mean discrepancy:最大平均差异
- 模型:
- 特点:
- source domain和target domain之间参数的部分共享
- 在source domain和target domain之间学习一个线性的转换
- 有一个很严重的问题,就是网络的架构会随着任务的改变而改变(否则性能会下降)
- 性能的话(据作者所说)好于Deep Domain Confusion的
- 性能:
Domain Separation Networks(2016)
- 点击查看笔记
- 源代码(论文里给出了地址 https://github.com/tensorflow/models/domain_adaptation,但是我点进去404了)
- 基于特征变换-以子空间为中心的方法( Lsimilarity )
- 采用的技术:
- adversarial loss的对抗性损失,具体实现使用的是梯度反转层GRL
- MMD(后来作者觉得使用MMD效果不如GAN loss)
- 模型:
- 特点:
- 分别针对source domain与target domain共有的部分,source domain和target domain私有的部分进行训练
- 在source domain和target domain之间的共有部分之间,作者最终选择了GAN loss,在两个stream之间另外建立了一个Domain classifier(域分类器)从梯度反转层(GRL)产生的结果中进行学习,与交叉熵形式的 Lsimilarity 进行对抗性训练
- 备注:
- 论文里的 G 和 D 和GAN那篇论文里的 G 和 D 不太一样
- 论文里的图像重建部分(shared Decoder)仅仅是用于观察学习的进度,貌似和对抗性损失的关系不大。
- 性能:
Deep CORAL: Correlation Alignment for Deep Domain Adaptation(2016)
- 点击查看笔记
- 基于特征变换-以数据为中心的方法(同一个映射)
- 非监督
- 采用的技术:
- CORAL损失: lCORAL=∥CS−CT∥2F4d2
- CORAL作为二阶统计量,对齐source domain和target domain的CORAL能够对齐source domain和target domain的均值和协方差矩阵
- 后一个是矩阵的Frobenius范数
- 协方差矩阵计算:
- CS=1nS−1(DTSDS−(lTDS)T(lTDS)nS)
- CT=1nT−1(DTTDT−(lTDT)T(lTDT)nT)
- 其中 l 是一个所有元素为1的列向量
- 协方差矩阵计算:
- CORAL损失: lCORAL=∥CS−CT∥2F4d2
- 模型(AlexNet,fc8层引入CORAL):
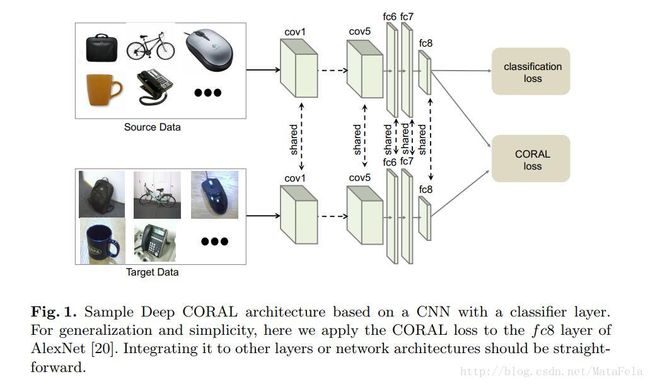
- 备注:
- 作者强调他的模型是”end-to-end”的,但是我没搞懂什么意思
- 作者也强调这个CORAL正则项很“易于实现”
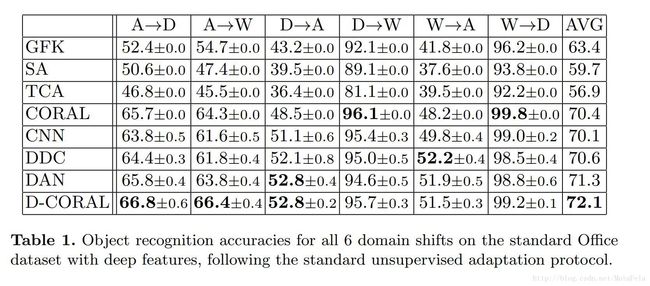
- 性能:
Unsupervised Domain Adaptation with Residual Transfer Networks(2017)
- 点击查看笔记
- 源代码
- 基于特征变换-以子空间为中心的方法
- 非监督
采用的技术:
- 多层MMD(Maximum Mean Discrepancy on multiple layers):
minfS,fTDL(DS,DT)=∑i=1ns∑j=1nsk(zsi,zsj)n2s+∑i=1nt∑j=1ntk(zti,ztj)n2t−2∑i=1ns∑j=1ntk(zsi,ztj)nsnt
- Residual function(Deep residual learning for image recognition.[CVPR2016])
- 多层MMD(Maximum Mean Discrepancy on multiple layers):
模型(前面AlexNet,ResNet等):

- 特点:
- 这篇论文更倾向于解决source domain和target domain差异较大的情况,source domain和target domain使用的是不同的分类器
- source domain和target domain的分类器作者认为不应差距过大,所以在source domain和target domain的分类器之间学习一个Residual function Δf(x) 使得source domain和target domain的分类器有个较小的区别,其中, fs(x)=ft(x)+Δf(x) (target domain上没有标签,所以用source domain的放在前面)
- 为保证target domain的分类器确实有分类的能力,使用entropy penalty(熵惩罚)保证分类器的输出趋向于one-hot vector(保证了low-density separation)。
- 性能:

[CVPR2017]Unsupervised Pixel–Level Domain Adaptation with Generative Adversarial Networks
- 点击查看笔记
- 源代码:”We plan to open source our code once author feedback is released”
- 非监督(实验中提到了半监督的拓展)
- 本文使用对抗性损失(adversarial loss)中的生成式模型(generative model)进行domain adaptation任务
- 模型(分类器和域适应解耦合):

- 采用的技术:
- adversarial loss:
- 与GAN那篇文章里有不同,本文将source domain图像和一个随机噪声(实验中提到是均匀分布的 U∈(−1,+1) )作为生成器(generator)的输入(类比GAN那篇文章里的 z ),去拟合target domain的图像的分布(类比GAN那篇文章中原始的图像分布)
- 本文:

- GAN:

- 受style transfer的启发,使用的Content–similarity loss
- 希望generator生成的图像,前景色和source domain基本一致(背景色不作要求),不过并不是阻止前景色的变化,而是希望前景色的变化能够保持一致。
- 在给定一个遮罩的情况下进行图像的Content–similarity loss,不过我没有看明白这个图像是数据集给定的,还是网络学习得出的,还是自己标记的(这个几乎不可能):
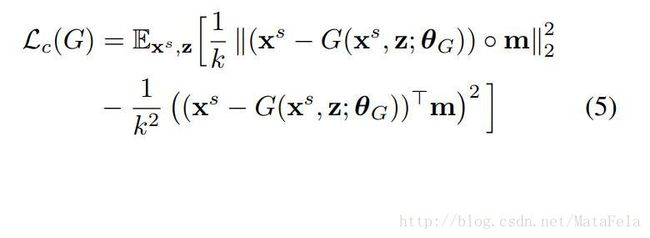

- adversarial loss:
- 备注:
- target domain和source domain的标签域可以不一样,target domain训练时和测试时可以使用不同的标签。
- 作者说因为这个域适应是在像素级别上进行的( because our model
maps one image to another at the pixel level),所以我们可以改变这个Task-Specific图像训练结构
- 网络对参数设置不敏感
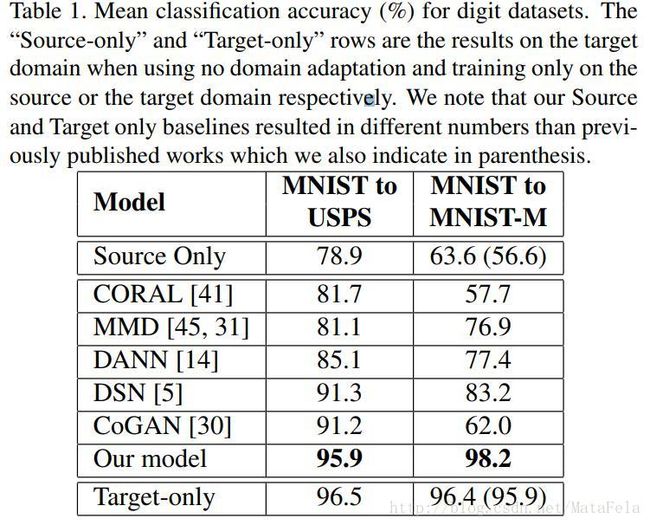
- 性能:
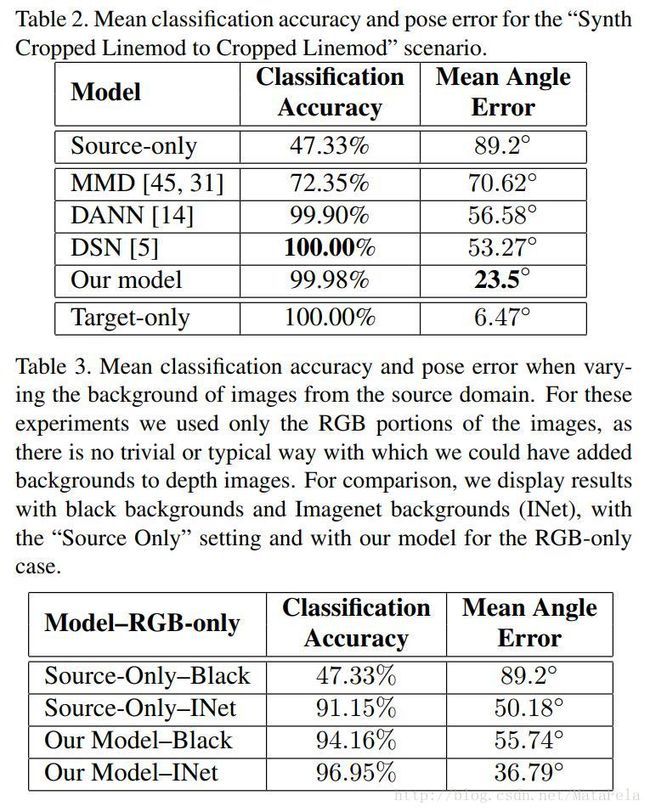
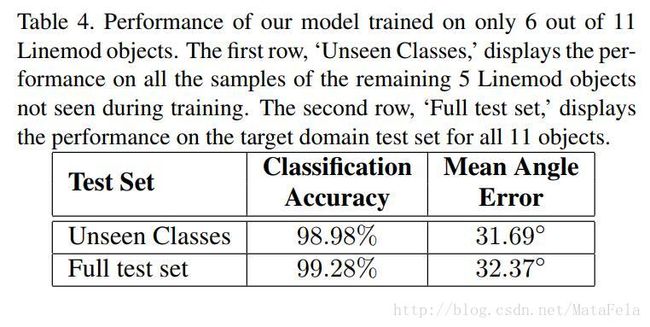
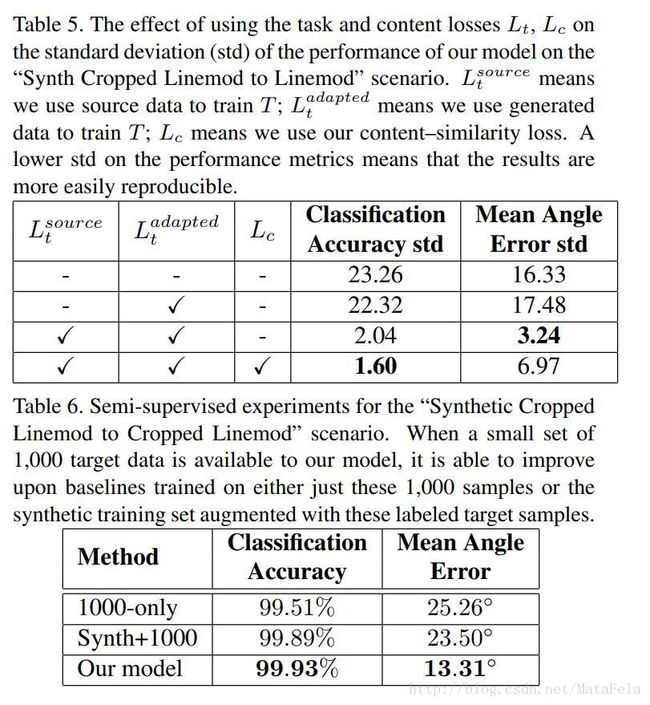
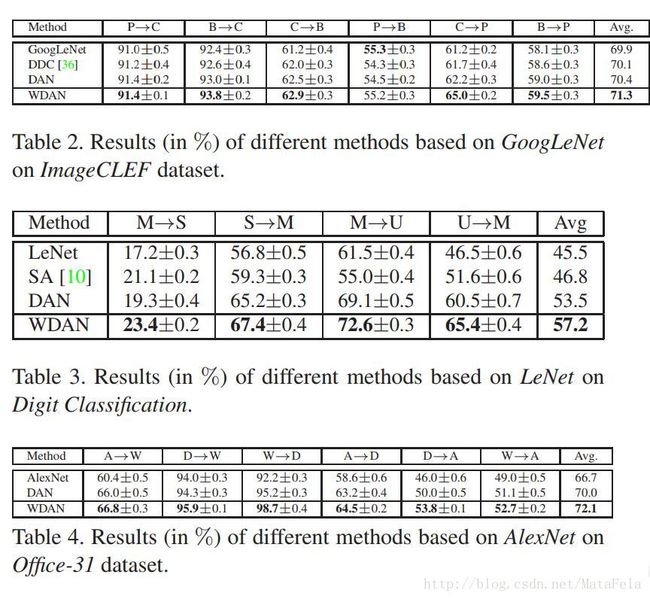
[CVPR2017]Mind the Class Weight Bias: Weighted Maximum Mean Discrepancy for Unsupervised Domain Adaptation
- 点击查看笔记
- 源代码
- 基于特征变换-以子空间为中心的方法
- 非监督
- weighted MMD 说明:
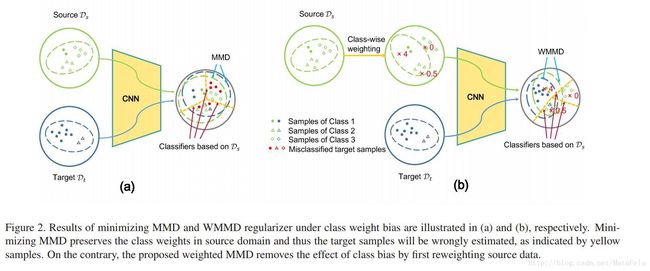
- 采用的技术:
- 改良后的MMD(weighted MMD,作者把相应的架构称为WDAN(weighted domain adaptation network)):
- 直接使用MMD来测量source domain和target domain作者认为会造成一定的误差,因为仅仅使用MMD没有考虑到source domain和target domain之间的class weight(类的先验分布)的不同。当source domain和target domain的类的先验分布差异很大的时候,仅仅使用MMD会造成target domain上严重的分类失误。
- 作者引入class-specific auxiliary
weights(类特定辅助权重?)对source domain的样本重新分配权重,以使得映射以后的source domain样本的类后验分布于target domain一致(但是难点在于target domain的类先验分布未知,因为没有标签,因此后验分布也未知)(对于判别式模型(discriminative model),网络学习的是类的后验概率) - 为了解决target domain的类先验分布未知的问题,作者又引入了一个新的训练方式,被称为ECM(具体见笔记)
- E:估计target domain的类后验概率(用上次迭代得到的分类器做出的预测来进行判断)
- C:利用E步骤中计算的类后验概率,给定每个target domain数据一个pesudo label,并计算class-specific auxiliary
weights(类特定辅助权重?)的估计值 - M:利用class-specific auxiliary
weights的估计值,更新网络的各个参数,得到的分类器用于下一次迭代给E以预测的结果。
- 改良后的MMD(weighted MMD,作者把相应的架构称为WDAN(weighted domain adaptation network)):
- 特点:
- 当source domain和target domain的类先验分布差异较大的时候,这个网络应该会有比较好的表现
- 性能:

[CVPR2017]Learning an Invariant Hilbert Space for Domain Adaptation
- 因为我水平所限(流形学习与相关的数学方面的知识不足),这篇论文很大一部分无法理解,所以只能简单归类一下)
- 点击查看笔记
- 源代码
- 基于特征变换-以子空间为中心的方法
- 非监督与半监督
- 模型说明:
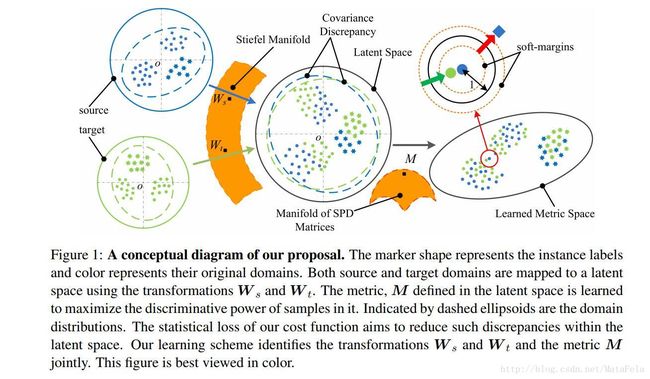
- 采用的技术:
- 流形学习
- 马氏距离
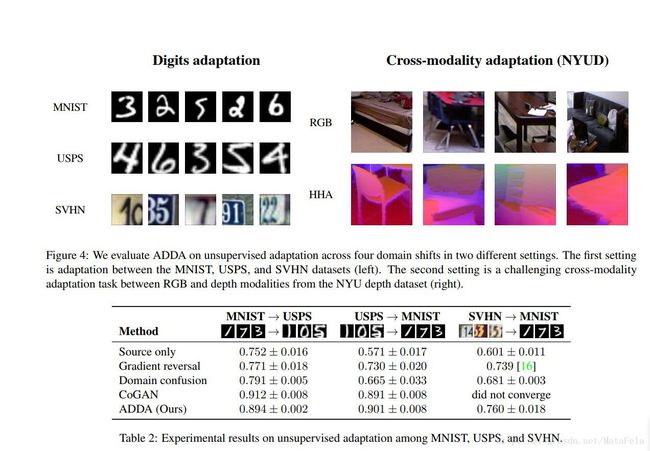
[CVPR2017]Adversarial Discriminative Domain Adaptation
- 点击查看笔记
- 基于特征变换-以子空间为中心的方法
- 非监督
- 模型说明:
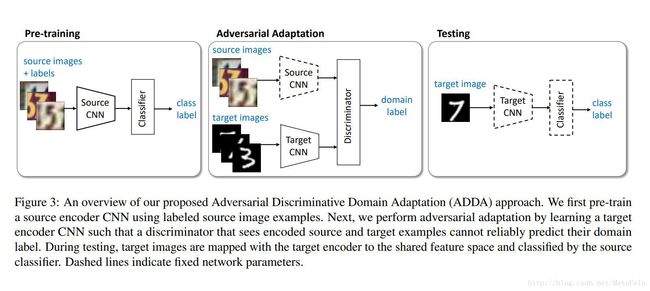
- 虚线为固定参数
- 先预训练source domain上的分类器 CS 和source mapping Ms ,其中作者假设source domain和target domain共用一个分类器
- 之后固定source domain上的参数,对抗性地训练域分类器 D 和target mapping Mt
- 测试期间则直接使用source domain上的分类器对映射后的target domain数据进行分类
- (我本人的想法)分类器仅仅使用source domain上的数据进行训练,可能并不能很好地推广(泛化),毕竟仅仅使用source domain训练的分类器可能会带有一定的域特定特征(domain-separated feature)
- 采用的技术:
- adversarial loss:
- 作者的对抗性损失考虑的比较周到,这也是该论文的亮点,详细的在笔记里有提到,这里就不再详细说了
- adversarial loss:
- 性能:
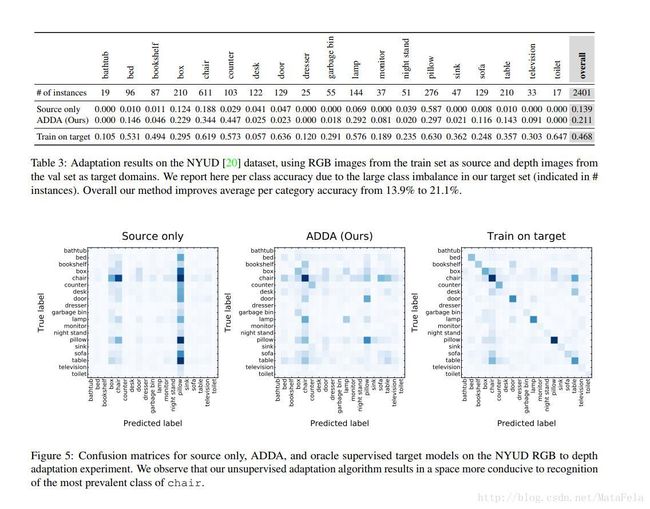
[cvpr2017]Deep Hashing Network for Unsupervised Domain Adaptation
- 点击查看笔记
- 源代码
- 基于特征变换-以子空间为中心的方法
- 非监督
- 模型:

- 采用的技术:
- 多层的的多核MMD(multi-kernel Maximum Mean Discrepancy (MK-MMD))
- Hash:
- 希望source domain学习到的哈希码中,同一类的哈希码尽可能相似,不同一类的哈希码尽可能不同(相似度的概率度量使用汉明距离(Hamming Distance))
- 希望target domain学习到的哈希码能够和source domain中某一类的图片的哈希码相似,但是和其他类的哈希码不相似
- 特点:
- 在数据量很庞大的时候,所以考虑到了哈希,可以利用哈希的快速查询和低内存使用
- 性能:

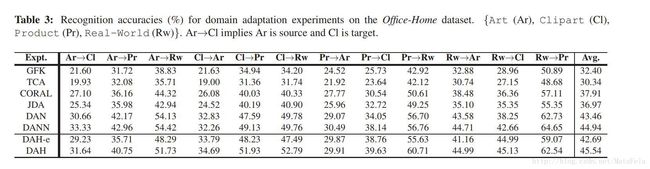
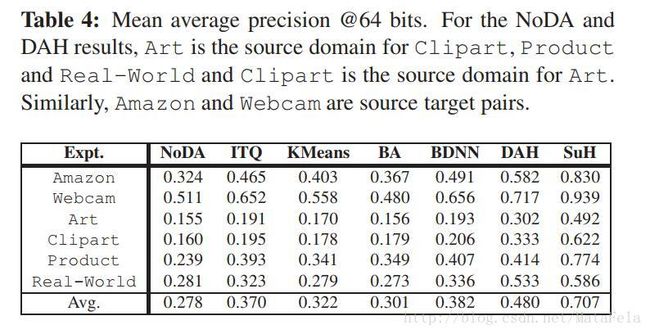
[cvpr2017]Joint Geometrical and Statistical Alignment for Visual Domain Adaptation
- 这篇文章我读的比较吃力,近期内我打算在学习LDA的相关知识以后再针对这篇文章进行校正,现在这篇笔记仅供参考
- 点击查看笔记
- 源代码
- 作者在他的网络中学习两个耦合的投影(coupled projections),将source domain和target domain上的数据映射到相应的子空间。在映射之后:
- 最大化target domain上数据的方差以保留target domain上数据的特征
- 保留source domain上数据的判别信息(discriminative information)以使得有效地传送类别的信息
- 最小化投影后的source domain和target domain上数据的条件分布差异(conditional distribution divergences),在统计上(statistically)减少域偏移(domain shift)
- 使得两个域的投影之间的差异较小(子空间之间的差异较小),在几何上(geometrically)减少域偏移(domain shift)。
- 1) the variance of target domain is maximized,
2) the discriminative information of source domain is preserved,
3) the divergence of source and target distributions
is small, and 4) the divergence between source and target
- 优势:
- 与基于数据的方法不同,作者的方法不需要强大的假设:统一变换可以减少分布偏移,同时保留数据属性。
- 不同于基于子空间的适应方法,作者的方式不仅减少了子空间的几何移动(reduce the shift of subspace geometries)并且减少了两个域之间的分布偏移
- 作者认为自己的方法可以很容易的扩展到kernelized(核方法)来处理域之间的偏移是非线性的情况
- 采用的技术:
- LDA:
- 线性判别分析
- 线性判别分析LDA原理总结
- LDA:
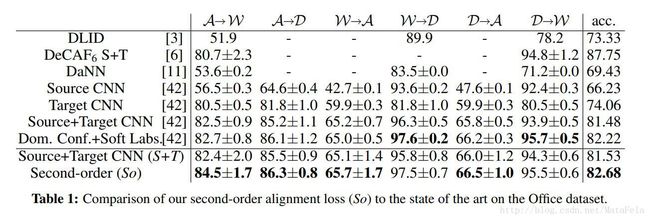
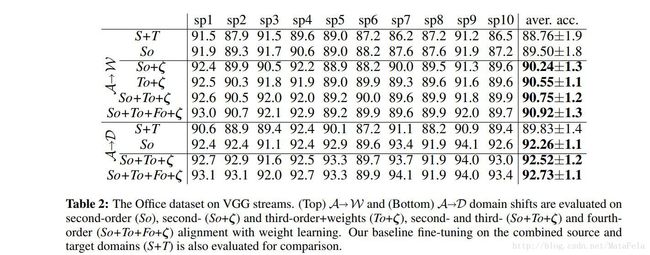
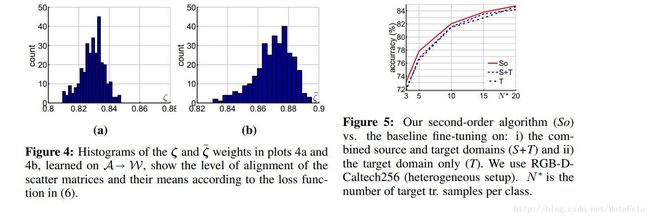
[cvpr2017]Domain Adaptation by Mixture of Alignments of Second- or Higher-Order Scatter Tensors
- 这篇文章我看起来依然有些吃力,以下写的仅供参考
- 点击查看笔记
- 基于特征变换-以子空间为中心的方法
- 模型:
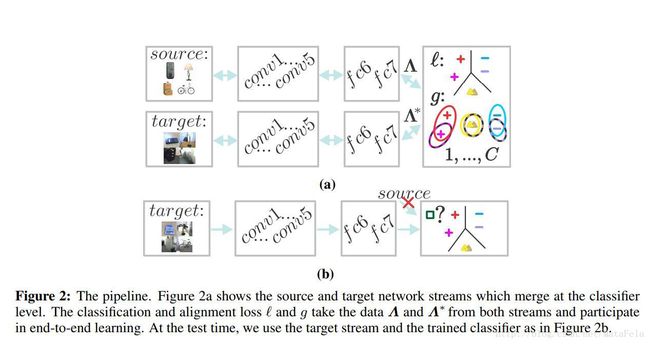
- 采用的技术:
- 使用高阶(二阶或者更高)的scatter张量积作为衡量source domain和target domain的距离
- 特点:
- 作者将自己的模型称为Second or
Higher-order Transfer of Knowledge (So-HoT),是一个对source domain和target domain之间进行二阶或者更高阶次的统计量的一个对齐(alignment).
- 作者将自己的模型称为Second or
- 性能: