一学就会的深度学习基础指令及操作步骤(6)迁移学习
文章目录
-
- 迁移学习
-
- 模型准备
- 数据增强
- 模型训练
- 模型微调和预测
- 检查预测结果
迁移学习
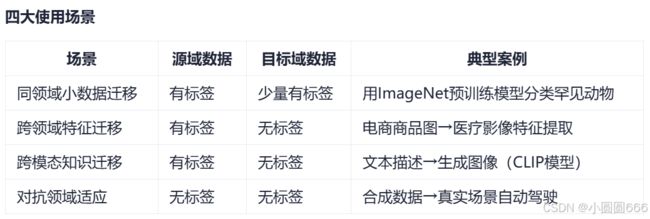
迁移学习是将一个任务中学到的知识应用到另一个相关任务上,以提高新任务的学习效率和性能。
优势:节省训练时间,提高模型性能,尤其在小数据场景下效果显著。
核心是利用源域的知识来帮助目标域任务,比如在ImageNet上预训练的模型用于医疗影像分类。
- 源域(Source Domain):已有知识的领域(如ImageNet图像库)。
- 目标域(Target Domain):待解决的新任务(如医疗影像分类)。
- 关键假设:源域和目标域存在共性(如边缘特征、语义结构)。
使用方法。常见的策略有
- 预训练+微调(Pre-training + Fine-tuning),比如用VGG16在ImageNet上预训练,然后针对特定任务调整部分层。
- 还有领域对抗训练(Domain Adversarial Training),通过对抗网络让模型学习领域不变特征,这在搜索结果中的DANN结构有所体现。
- 此外,特征提取和渐进式网络也是常用方法。
关键点包括:
- 选择合适的源任务和模型,确保源域与目标域的相关性;
- 调整模型结构,如冻结部分层或添加新的分类层;
- 处理数据分布差异,避免负迁移;
- 以及合理使用微调和对抗训练等技术。
- 需要注意数据预处理的一致性,比如在医疗影像中使用ImageNet的均值和标准差进行归一化。
模型准备
下载预训练模型
ImageNet torchvision.models 预训练模型已经学会对各种不同类型的图像进行分类,它们学会了检测许多不同类型的特征,这些特征对于图像识别非常重要。 可参考机器学习术语表。
现在需要找到一个擅长检测动物的预训练模型,根据现有的少量特殊品种狗的图片,进行迁移学习。由于 ImageNet 模型已学会检测包括狗在内的多种动物,下载相关模型。
下载预训练模型
from torchvision.models import vgg16
from torchvision.models import VGG16_Weights
# load the VGG16 network *pre-trained* on the ImageNet dataset
weights = VGG16_Weights.DEFAULT
vgg_model = vgg16(weights=weights)
vgg_model.to(device)
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
冻结预训练模型基础层
冻结预训练模型的基础层,在进行新的训练时,不会更新预训练模型的基础层。保留通过 ImageNet 数据集训练时所获得的学习成果。
冻结基础层非常简单,只需将模型的 requires_grad_ 参数设置为 False 即可。
vgg_model.requires_grad_(False)
添加新层
ImageNet 模型的最后一层是包含 1000个单元的密集连接层,用来表达数据集中的1000 个可能的分类。
这里需要模型作出一个不同的分类,可以添加一个新层专门来做新动物的分类。
在预训练模型上添加新的可训练层,它们将利用预训练层中的特征并将其转变成对新数据集的预测。
-
向模型添加两个层。利用 Sequential Model 的层,创建了一个自定义模型。
-
添加一个连接 VGG16 所有
1000个输出到1个神经元的Linear层。
N_CLASSES = 1
my_model = nn.Sequential(
vgg_model,
nn.Linear(1000, N_CLASSES)
)
my_model.to(device)
# 结果打印
Sequential(
(0): VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
(1): Linear(in_features=1000, out_features=1, bias=True)
)
可以通过遍历模型的参数来确认 VGG 层被冻结了。
for idx, param in enumerate(my_model.parameters()):
print(idx, param.requires_grad)
# 结果打印
0 False
1 False
2 False
3 False
4 False
5 False
6 False
7 False
8 False
9 False
10 False
11 False
12 False
13 False
14 False
15 False
16 False
17 False
18 False
19 False
20 False
21 False
22 False
23 False
24 False
25 False
26 False
27 False
28 False
29 False
30 False
31 False
32 True
33 True
如果我们想让 VGG 层能被训练,可以把 vgg_model 的 requires_grad_ 设置为 True
vgg_model.requires_grad_(True)
print("VGG16 Unfrozen")
for idx, param in enumerate(my_model.parameters()):
print(idx, param.requires_grad)
# 结果打印
VGG16 Unfrozen
0 True
1 True
2 True
3 True
4 True
5 True
6 True
7 True
8 True
9 True
10 True
11 True
12 True
13 True
14 True
15 True
16 True
17 True
18 True
19 True
20 True
21 True
22 True
23 True
24 True
25 True
26 True
27 True
28 True
29 True
30 True
31 True
32 True
33 True
编译模型
需要设置损失函数和评价函数选项来编译模型。本例只是一个二分类问题(是否是特殊动物),因此我们将使用二分类交叉熵 (binary cross-entropy)。使用二分类精度代替多分类精度作为评价函数。
通过设置 from_logits=True,我们可以告知损失函数输出值并未归一化(例如使用 softmax)。
loss_function = nn.BCEWithLogitsLoss()
optimizer = Adam(my_model.parameters())
my_model = my_model.to(device)
数据增强
自定义数据集并加载
读取图像文件,并根据文件路径推断 label。
DATA_LABELS = ["bo", "not_bo"]
class MyDataset(Dataset):
def __init__(self, data_dir):
self.imgs = []
self.labels = []
for l_idx, label in enumerate(DATA_LABELS):
data_paths = glob.glob(data_dir + label + '/*.jpg', recursive=True)
for path in data_paths:
img = Image.open(path)
self.imgs.append(pre_trans(img).to(device))
self.labels.append(torch.tensor(l_idx).to(device).float())
def __getitem__(self, idx):
img = self.imgs[idx]
label = self.labels[idx]
return img, label
def __len__(self):
return len(self.imgs)
创建 DataLoaders
n = 32
train_path = "data/presidential_doggy_door/train/"
train_data = MyDataset(train_path)
train_loader = DataLoader(train_data, batch_size=n, shuffle=True)
train_N = len(train_loader.dataset)
valid_path = "data/presidential_doggy_door/valid/"
valid_data = MyDataset(valid_path)
valid_loader = DataLoader(valid_data, batch_size=n)
valid_N = len(valid_loader.dataset)
数据增强
从 VGG 的 weights 中获取预处理变换列表。
pre_trans = weights.transforms()
IMG_WIDTH, IMG_HEIGHT = (224, 224)
random_trans = transforms.Compose([
transforms.RandomRotation(25),
transforms.RandomResizedCrop((IMG_WIDTH, IMG_HEIGHT), scale=(.8, 1), ratio=(1, 1)),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=.2, contrast=.2, saturation=.2, hue=.2)
])
模型训练
def get_batch_accuracy(output, y, N):
zero_tensor = torch.tensor([0]).to(device)
pred = torch.gt(output, zero_tensor)
correct = pred.eq(y.view_as(pred)).sum().item()
return correct / N
def train(model, check_grad=False):
loss = 0
accuracy = 0
model.train()
for x, y in train_loader:
output = torch.squeeze(model(random_trans(x)))
optimizer.zero_grad()
batch_loss = loss_function(output, y)
batch_loss.backward()
optimizer.step()
loss += batch_loss.item()
accuracy += get_batch_accuracy(output, y, train_N)
if check_grad:
print('Last Gradient:')
for param in model.parameters():
print(param.grad)
print('Train - Loss: {:.4f} Accuracy: {:.4f}'.format(loss, accuracy))
def validate(model):
loss = 0
accuracy = 0
model.eval()
with torch.no_grad():
for x, y in valid_loader:
output = torch.squeeze(model(x))
loss += loss_function(output, y.float()).item()
accuracy += get_batch_accuracy(output, y, valid_N)
print('Valid - Loss: {:.4f} Accuracy: {:.4f}'.format(loss, accuracy))
epochs = 10
for epoch in range(epochs):
print('Epoch: {}'.format(epoch))
train(my_model, check_grad=False)
validate(my_model)
# 打印结果
Epoch: 0
Train - Loss: 3.9825 Accuracy: 0.5252
Valid - Loss: 0.8333 Accuracy: 0.6333
Epoch: 1
Train - Loss: 2.4706 Accuracy: 0.8561
Valid - Loss: 1.4167 Accuracy: 0.6667
Epoch: 2
Train - Loss: 1.9898 Accuracy: 0.8633
Valid - Loss: 1.4064 Accuracy: 0.6667
Epoch: 3
Train - Loss: 1.9623 Accuracy: 0.8777
Valid - Loss: 1.2567 Accuracy: 0.6667
Epoch: 4
Train - Loss: 1.3193 Accuracy: 0.8633
Valid - Loss: 0.9433 Accuracy: 0.6667
Epoch: 5
Train - Loss: 1.8092 Accuracy: 0.8345
Valid - Loss: 0.6991 Accuracy: 0.6667
Epoch: 6
Train - Loss: 1.0085 Accuracy: 0.9281
Valid - Loss: 0.5126 Accuracy: 0.7333
Epoch: 7
Train - Loss: 1.2032 Accuracy: 0.8993
Valid - Loss: 0.4216 Accuracy: 0.7667
Epoch: 8
Train - Loss: 1.3833 Accuracy: 0.8993
Valid - Loss: 0.3045 Accuracy: 0.8333
Epoch: 9
Train - Loss: 1.0726 Accuracy: 0.8705
Valid - Loss: 0.1581 Accuracy: 0.9667
模型微调和预测
在经过冻结基础层,增加新层进行迁移学习后,还可以进一步采用微调的方法。
- 阶段一:冻结预训练层 + 训练新层
- 冻结预训练模型的所有层(如VGG16的卷积层),仅训练新增的顶层(如自定义的分类层),避免预训练层的权重被破坏(上节)
- 阶段二:解冻全部层 + 低学习率微调
- 前提:新增层已充分训练(如损失收敛、验证准确率稳定),确保其参数初步适配新任务
- 解冻所有层:允许预训练层和新层同时更新
- 然后以极小的学习率 重新训练模型如 0.0001(原学习率的1/10或更低),避免大幅破坏预训练特征。
- 只有在包含冻结层和新层的模型经过充分训练后才能执行此步骤,否则,由于我们先前添加到模型中的新的池化层和分类层是随机地初始化的,
- 我们需要对它们的参数进行大量的更新才能实现准确的图像分类。而通过反向传播过程,在整个模型解冻的状态下,这种对最后两层的大量更新也可能导致预训练层中出现大量更新,从而破坏那些重要的预训练特征。现在这最后2层已经过训练且已收敛,因此再次训练时对模型整体的更新都要小得多(尤其是学习率非常小时),不会破坏前面那些层所预学到的特征。
解冻预训练层,然后微调整个模型:
# Unfreeze the base model
vgg_model.requires_grad_(True)
optimizer = Adam(my_model.parameters(), lr=.000001) # 极低学习率
#少训练几个 `epoch`。因为 VGG16 是个很大的模型,在这个数据集上训练时间过长的话很容易过拟合。
epochs = 2
for epoch in range(epochs):
print('Epoch: {}'.format(epoch))
train(my_model, check_grad=False)
validate(my_model)
总结
分阶段训练,防止梯度冲突:
- 初始阶段:新层随机初始化时,若直接解冻底层,反向传播的大梯度会扰乱预训练特征。
- 后期微调:新层稳定后,小学习率微调可使预训练层适应新数据分布,而非彻底改变。
学习率选择:
- 初始训练:较高学习率(如 0.001)加速新层收敛。
- 微调阶段:极低学习率(如 0.0001)保护预训练特征。
检查预测结果
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
def show_image(image_path):
image = mpimg.imread(image_path)
plt.imshow(image)
def make_prediction(file_path):
show_image(file_path)
image = Image.open(file_path)
image = pre_trans(image).to(device)
image = image.unsqueeze(0)
output = my_model(image)
prediction = output.item()
return prediction