Ubuntu 16.04下Caffe-SSD的应用(二)——准备与处理VOC2007数据集
前言
- 前面已经介绍如何在Ubuntu上编译Caffe-SSD的CPU版本,那接下来就试一下用Caffe-SSD训练数据得到模型,并对模型进行测试。
- 我配置的环境是Ubuntu 16.04 LST 64位,Qt5.9,Python2.7,Caffe-SSD,因为只跑CPU版本,所以没有配置CUDA库。
一、数据准备
1.下载VOC2007和VOC2012数据集
cd caffe-ssd/data
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
下载完之后,在caffe-ssd/data文件夹下多了三个文件
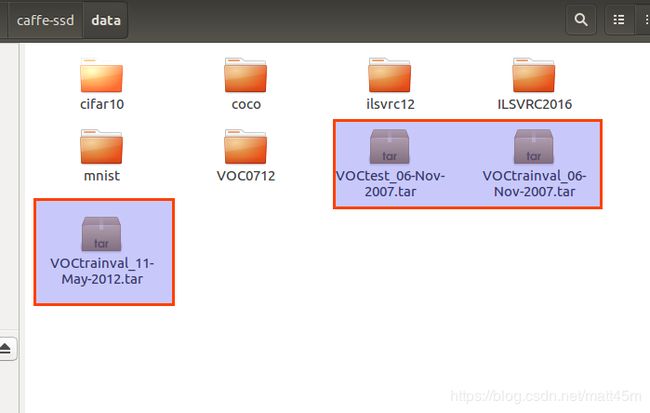
2.解压这三个文件,按以下的顺序解压
tar -xvf VOCtrainval_11-May-2012.tar
tar -xvf VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtest_06-Nov-2007.tar
解压完之后,在caffe-ssd/data目录下多了一个文件夹

二、更改脚本
1.从VOC0712这个目录下复制文件过刚刚解压出来的数据目录
cd caffe-ssd/data
cp VOC0712/create_list.sh VOCdevkit/VOC2007/
cp VOC0712/create_data.sh VOCdevkit/VOC2007/
cp VOC0712/labelmap_voc.prototxt VOCdevkit/VOC2007/
在VOCdevkit/VOC2007目录下多了三个文件
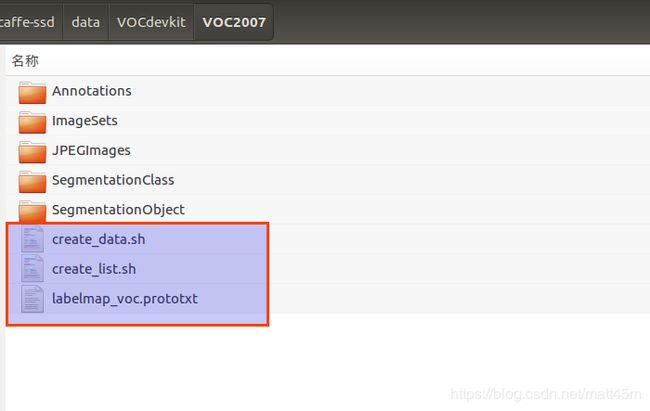
其中create_list.sh 是生成对应的列表文件,create_data.sh是把图像数据转换成caffe可识别的数据LMDB,labelmap_voc.prototxt 是放着对应的标签的名字。
2.更改配置文件的相关路径,因为data目录不是放在根目录上,所要更改相关路径。
(1)更改create_list.sh
cd VOCdevkit/VOC2007/
sudo gedit create_list.sh
更改create_list.sh的文件内容,总共要修改三个位置。
更改根目录
#root_dir=$HOME/data/VOCdevkit/
#更改为
root_dir=/home/matt/caffe-ssd/data/VOCdevkit/
更改数据来源
#for name in VOC2007 VOC2012
#更改为
for name in VOC2007
更改get_image_size路径
#$bash_dir/../../build/tools/get_image_size $root_dir $dst_file $bash_dir/$dataset"_name_size.txt"
#更改为
/home/matt/caffe-ssd/build/tools/get_image_size $root_dir $dst_file $bash_dir/$dataset"_name_size.txt"
(2)更改create_data.sh文件
在VOC2007目录下终端输入
sudo gedit create_list.sh
更改create_data.sh的文件内容,总共要修改五个位置。
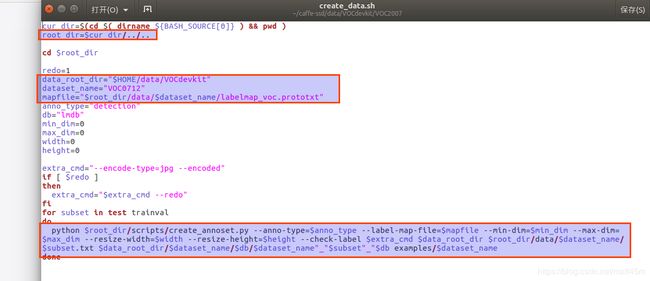
更改根路径
root_dir=$cur_dir/../..
改成:
root_dir=/home/matt/caffe-ssd
更改数据路径:
data_root_dir="$HOME/data/VOCdevkit"
dataset_name="VOC0712"
mapfile="$root_dir/data/$dataset_name/labelmap_voc.prototxt"
改成:
data_root_dir="/home/matt/caffe-ssd/data/VOCdevkit"
dataset_name="VOC2007"
mapfile="$root_dir/data/VOCdevkit/$dataset_name/labelmap_voc.prototxt"
anno_type="detection"
生成的数据路径
python $root_dir/scripts/create_annoset.py --anno-type=$anno_type --label-map-file=$mapfile --min-dim=$min_dim --max-dim=$max_dim --resize-width=$width --resize-height=$height --check-label $extra_cmd $data_root_dir $root_dir/data/$dataset_name/$subset.txt $data_root_dir/$dataset_name/$db/$dataset_name"_"$subset"_"$db examples/$dataset_name
改成:
python $root_dir/scripts/create_annoset.py --anno-type=$anno_type --label-map-file=$mapfile --min-dim=$min_dim --max-dim=$max_dim --resize-width=$width --resize-height=$height --check-label $extra_cmd $data_root_dir $root_dir/data/VOCdevkit/$dataset_name/$subset.txt $data_root_dir/$dataset_name/$db/$dataset_name"_"$subset"_"$db examples/$dataset_name

三、处理数据
1.运行create_list.sh脚本
sudo ./create_list.sh
如果不报错,在VOC2007目录下生成三个txt文件
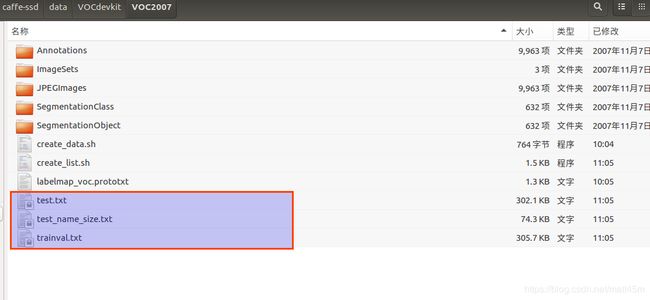
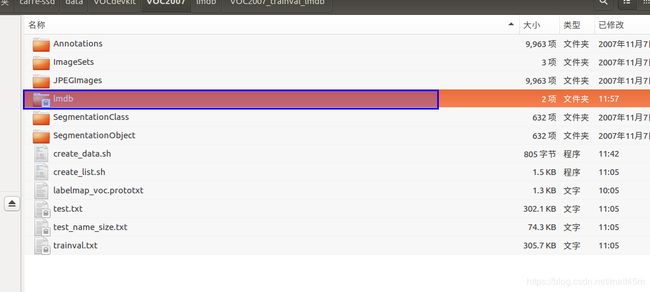
2.运行create_data.sh脚本,生成lmdb数据
sudo ./create_data.sh
有可能会报这个错误
./create_data.sh: 1: ./create_data.sh: Bad substitution
Traceback (most recent call last):
File "/home/matt/caffe-ssd/scripts/create_annoset.py", line 7, in
from caffe.proto import caffe_pb2
ImportError: No module named caffe.proto
Traceback (most recent call last):
File "/home/matt/caffe-ssd/scripts/create_annoset.py", line 7, in
from caffe.proto import caffe_pb2
ImportError: No module named caffe.proto
这种情况一般是没有把caffe中的和python相关的内容的路径添加到python的编译路径中。
第一种解决办法是把路径添加上,我的环境下终端运行,这个要每次要运行该脚本都要添加
export PYTHONPATH=/home/matt/caffe-ssd/python:$PYTHONPATH
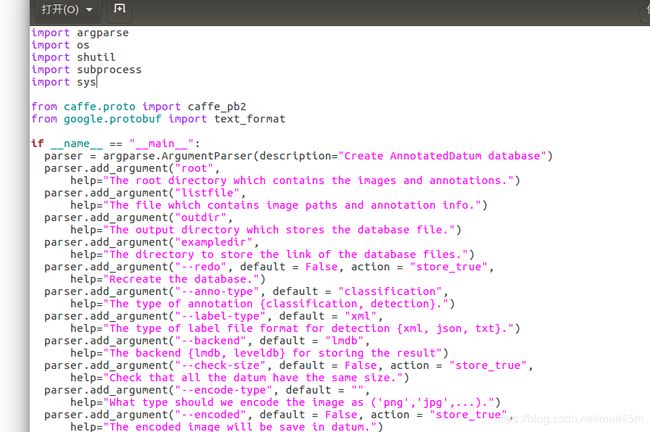
第二办法是直接更改/home/matt/caffe-ssd/scripts/create_annoset.py,在源码里添加自己的python的路径
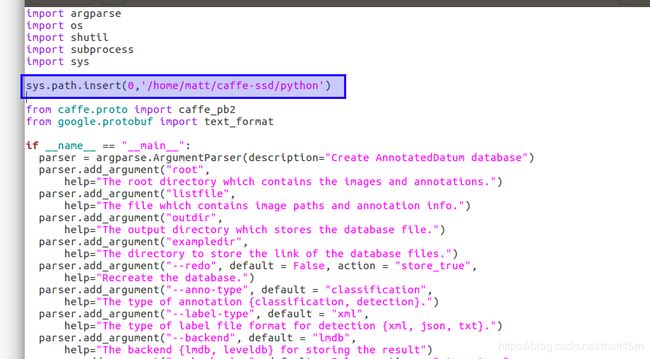
sys.path.insert(0,'/home/matt/caffe-ssd/python')
更改前
添加之后
再次运行成功,在VOC2007目录下多了一个lmdb的目录
结语
1.如是以上脚本全部运行成功,之后就是开始训练模型了。
2.关于运行以上脚本的问题,都可以加这个群(487350510)互相讨论学。