云计算Hadoop配置(三) ——完全分布配置
3.4.1 系统规划
由于条件的限制,不能够获得更多的机器来进行模拟,所以在模拟完全分布式计算中,只能使用三台机器搭建环境。一台机器作为Namenode和JobTracker,另外两台机器作为运行任务的Datanode节点。如下表3-1所示:
表3-1 分布式机器节点说明
| Node |
User |
IP adress |
备注 |
| Namenode |
administrator1 |
192.168.0.1 |
Namenode和Jobtracker使用同一台机器 |
| Datanode |
administrator2 |
192.168.0.2 |
|
| Datanode |
administrator3 |
192.168.0.3 |
3.4.2 修改hosts
$ sudo gedit /etc/hosts //将所使用到的三台主机及其名称添加到该文件中.
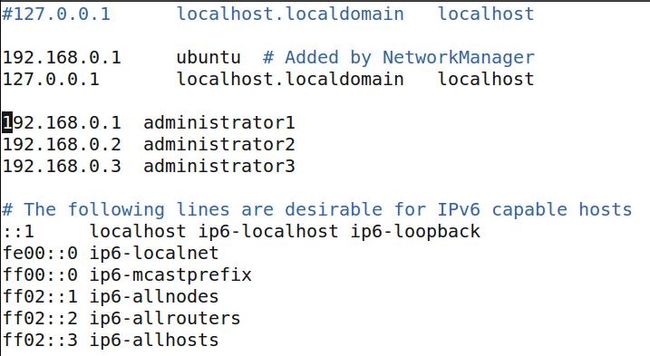
图3-1 修改hosts
3.4.3 配置ssh
//在Namenode节点上运行命令,使得Namenode能够无密码访问Datanode
$ scp [email protected]:/home/administrator/.ssh/id_dsa.pub 2_dsa.pub
$ cat 2_dsa.pub >> /home/administrator/authorized_keys
$ scp [email protected]:/home/administrator/.ssh/id_dsa.pub 3_dsa.pub
$ cat 3_dsa.pub >> /home/administrator/authorized_keys
//在Datanode节点上运行命令,使得Datanode能够无密码访问Namenode
$ scp [email protected]:/home/administrator/.ssh/id_dsa.pub 1_dsa.pub
$ cat 1_dsa.pub >> /home/administrator/authorized_keys
//在Datanode节点上运行命令,使得Datanode之间能够无密码访问
//在Datanode1(192.168.0.2)上
$ scp [email protected]:/home/administrator/.ssh/id_dsa.pub 3_dsa.pub
$ cat 3_dsa.pub >> /home/administrator/authorized_keys
//在Datanode2(192.168.0.3)上
$ scp [email protected]:/home/administrator/.ssh/id_dsa.pub 2_dsa.pub
$ cat 2_dsa.pub >> /home/administrator/authorized_keys
3.4.4 配置conf/masters、conf/slaves
在所有节点上都要配置:
1) 在$HADOOP_HOME/conf/masters 中加入 NameNode IP、Jobtracker IP,本论文中即添加一个IP即可,如下图3-2所示:

图3-2 配置masters
2) 在$HADOOP_HOME/conf/slaves 中加入 slaveIPs,本论文中即添加两个节点的IP地址即可,如下图3-3所示:

图3-3 配置slaves
3.4.5 配置三个文件
1) 配置$HADOOP_HOME/conf/core-site.xml
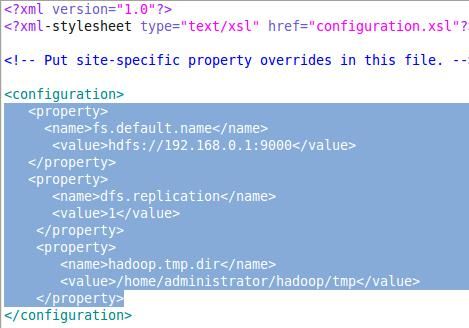
图3-4 配置core-site.xml
原来文件是空的,只要在该文件中添加图3-4中标示部分的内容即可。如没有配置 hadoop.tmp.dir 参数,此时系统默认的临时目录为:/tmp/hadoop/hadoop。而这个目录在每次重启后都会被干掉,必须重新执行format才行,否则会出错 。
2) 配置$HADOOP_HOME/conf/hdfs-site.xml,只要在该文件中添加图3-5中标示部分的内容即可。

图3-5 配置hdfs-site.xml
3) 配置$HADOOP_HOME/conf/mapred-site.xml,在原文件中添加图3-6中标示的内容即可。

图3-6 配置mapred-site.xml
3.4.6 启动Hadoop系统
1) 在Namenode上格式化分布式系统
$ bin/hadoop namenode –format //在Namenode上格式化系统
图3-7 格式化Namenode
2) 在Namenode上启动HDFS
$ bin/start-dfs.sh //该命令将访问NameNode 上的 conf/slaves 文件,在本机上启动 NameNode,本机JobTracker 上启动 SecondaryNameNode,在conf/slaves文件里的所有主机上启动DataNode

图3-8 启动HDFS
3) 在JobTracker上启动Map-Reduce
$ bin/start-mapred.sh //该命令将访问 JobTracker 上的 conf/slaves 文件,在本机上启动Jobtracker, 在 conf/slaves 文件里的所有主机上启动TaskTracker,本论文中的JobTracker和NameNode是同一个节点,所以在NameNode上启动 MapReduce。

图3-9 启动MapReduce
3.4.7 运行简单例子
1) 在/home/administrator文件夹下面创建临时文件test_file.txt,输入一些单词或语句。将本地文件test_file.txt文件复制到hdfs文件系统test-in文件夹中
$ bin/hadoop dfs -copyFromLocal /home/administrator/test_file.txt /test-in

图3-10 复制文件
$ bin/hadoop dfs –ls test-in//查看文件系统test-in文件夹中文件是否上传成功

图3-11 查看文件
2) 执行简单例子
$ bin/hadoop jar hadoop-mapred-examples-0.21.0.jar wordcount test-in test-out

图3-12 执行任务
3) 查看结果
$ bin/hadoop dfs –cat test-out/part-r-00000

图3-13 查看结果
3.4.8 关闭hadoop进程
1) 关闭Map-Reduce,在JobTracker上

图3-14 关闭Map-Reduce
2) 关闭HDFS,在NameNode上

图3-15 关闭HDFS