hadoop集群的安装步骤和配置
hadoop是由java语言编写的,首先我们肯定要在电脑中安装jdk,配置好jdk的环境,接下来就是安装hadoop集群的步骤了,在安装之前需要创建hadoop用户组和用户,另外我此时使用的是一主(master)三从(slave1、slave2、slave3)。
1、 创建hadoop组和hadoop用户
[root@master ~]# groupadd hadoop
[root@master ~]# useradd -g hadoop hadoop2、 上传、解压hadoop压缩包和重名解压后的目录
切换到hadoop用户:
[root@master ~]# su – hadoop上传hadoop安装包:
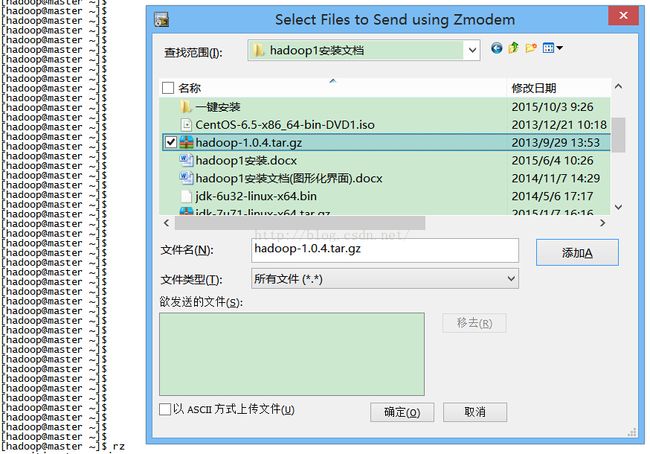
解压hadoop安装包和重命名解压目录:
[hadoop@master ~]$ tar -zxvf hadoop-1.0.4.tar.gz
[hadoop@master ~]$ mv hadoop-1.0.4 hadoop3、 配置hadoop的的配置文件
进入hadoop的conf目录:
[hadoop@master ~]$ cd hadoop
[hadoop@master hadoop]$ cd conf
[hadoop@master conf]$
[hadoop@master conf]$ ll
总用量 76
-rw-rw-r--. 1 hadoop hadoop 7457 10月 3 2012 capacity-scheduler.xml
-rw-rw-r--. 1 hadoop hadoop 535 10月 3 2012 configuration.xsl
-rw-rw-r--. 1 hadoop hadoop 178 10月 3 2012 core-site.xml
-rw-rw-r--. 1 hadoop hadoop 327 10月 3 2012 fair-scheduler.xml
-rw-rw-r--. 1 hadoop hadoop 2237 10月 3 2012 hadoop-env.sh
-rw-rw-r--. 1 hadoop hadoop 1488 10月 3 2012 hadoop-metrics2.properties
-rw-rw-r--. 1 hadoop hadoop 4644 10月 3 2012 hadoop-policy.xml
-rw-rw-r--. 1 hadoop hadoop 178 10月 3 2012 hdfs-site.xml
-rw-rw-r--. 1 hadoop hadoop 4441 10月 3 2012 log4j.properties
-rw-rw-r--. 1 hadoop hadoop 2033 10月 3 2012 mapred-queue-acls.xml
-rw-rw-r--. 1 hadoop hadoop 178 10月 3 2012 mapred-site.xml
-rw-rw-r--. 1 hadoop hadoop 10 10月 3 2012 masters
-rw-rw-r--. 1 hadoop hadoop 10 10月 3 2012 slaves
-rw-rw-r--. 1 hadoop hadoop 1243 10月 3 2012 ssl-client.xml.example
-rw-rw-r--. 1 hadoop hadoop 1195 10月 3 2012 ssl-server.xml.example
-rw-rw-r--. 1 hadoop hadoop 382 10月 3 2012 taskcontroller.cfg这里的配置文件有core-site.xml,hadoop-env.sh,hdfs-site.xml,mapred-site.xml,masters,slaves都需要修改,下面是这几个配置文件的内容:
core-site.xml配置文件的内容:
fs.default.name #++++hdfs的默认路径
hdfs://master:9000
hadoop-env.sh配置文件最后面添加的内容:
export JAVA_HOME=/usr/jdk #++++jdk的环境变量++++#hdfs-site.xml配置文件的内容:
dfs.replication #++++hdfs的备份数
3
dfs.name.dir #++++namenode的文件存储路径,包括edites、fsimage、fstime、VERSION
/home/hadoop/hadoop/namenode/
dfs.data.dir #++++datanode的存储路径,包含数据和数据的原信息。
/home/hadoop/hadoop/data/
hadoop.tmp.dir #++++mapreduce计算的中间结果的临时存储文件夹
/home/hadoop/hadoop/tmp/
dfs.permissions #++++认证策略
false
mapred-site.xml配置文件的内容:
mapred.job.tracker #++++jobtracker的ip和端口
master:9001
mapred.tasktracker.map.tasks.maximum #++++maptask的最大数
2
mapred.tasktracker.reduce.tasks.maximum #++++reducetask的最大数
2
masters配置文件的内容:
master
#SecondaryNameNode的位置,可以配置多个slaves配置文件的内容:
slave1#++++slave的ip或者域名
slave2
slave3说明:这些配置文件都是事先配置好的,只要上传到conf目录下,替换之前的文件即可,采用这种方式是因为在linux命令行下直接打开文件在里面输入内容更容易错并且不方便。这里还有一点需要注意,上面配置文件中存在的汉字是用于注释的,实际上传的文件是没有注释的,因为不支持汉字。
上传配置文件过程:

4、 到这里hadoop就安装结束了,接下来就是将安装完成的hadoop发送到其他的虚拟机中。
[hadoop@master conf]$ scp -r /home/hadoop/hadoop hadoop@slave1:/home/hadoop
[hadoop@master conf]$ scp -r /home/hadoop/hadoop hadoop@slave2:/home/hadoop
[hadoop@master conf]$ scp -r /home/hadoop/hadoop hadoop@slave3:/home/hadoop向另外三台机器发送hadoop,记住这里发送到另外一台机器的hadoop用户下,而非root用户下。发送完成,就意味着三台机器的hadoop都已经安装完成。
5、 安装ssh
为了在master机器中启动集群中所有的hadoop,这里安装ssh是提供启动方便。
将slave1、slave2、slave3三台机器都切换到hadoop用户;
在slave1、slave2、slave3三台机器中执行ssh localhost,是为了生成.ssh目录,这个目录默认是隐藏的需要使用ll –a命令查看。
[hadoop@slave1 ~]$ ll -a
总用量 32
drwx------. 5 hadoop hadoop 4096 11月 20 23:09 .
drwxr-xr-x. 3 root root 4096 11月 20 22:20 ..
-rw-r--r--. 1 hadoop hadoop 18 7月 18 2013 .bash_logout
-rw-r--r--. 1 hadoop hadoop 176 7月 18 2013 .bash_profile
-rw-r--r--. 1 hadoop hadoop 124 7月 18 2013 .bashrc
drwxr-xr-x. 2 hadoop hadoop 4096 11月 12 2010 .gnome2
drwxr-xr-x. 14 hadoop hadoop 4096 11月 20 23:03 hadoop
drwx------. 2 hadoop hadoop 4096 11月 20 23:09 .ssh在master机器中生成公钥和私钥:
进入.ssh目录,移除里面的known_hosts文件
[hadoop@master ~]$ cd .ssh
[hadoop@master .ssh]$ ll
总用量 4
-rw-r--r--. 1 hadoop hadoop 1209 11月 20 23:05 known_hosts
[hadoop@master .ssh]$
[hadoop@master .ssh]$ rm -rf known_hosts生成公钥和私钥:
[hadoop@master .ssh]$ ssh-keygen -t rsa出现需要输入内容的对话,一律回车,只到生成结束
把公钥放到认证列表中:
[hadoop@master .ssh]$ cat id_rsa.pub >> authorized_keys此时.ssh目录下回多出一个文件authorized_keys
给authorized_keys文件授权:
[hadoop@master .ssh]$ chmod 600 authorized_keys将authorized_keys文件发送到slave1、slave2、slave3的hadoop用户下的.ssh目录下:
[hadoop@master .ssh]$ scp ~/.ssh/authorized_keys hadoop@slave1:~/.ssh/
[hadoop@master .ssh]$ scp ~/.ssh/authorized_keys hadoop@slave2:~/.ssh/
[hadoop@master .ssh]$ scp ~/.ssh/authorized_keys hadoop@slave3:~/.ssh/至此ssh就安装成功了。
6、 启动hadoop,这里要注意,要使用hadoop用户,不能用root用户。
格式化集群:
[hadoop@master .ssh]$ hadoop namenode –format启动集群:
[hadoop@master ~]$ start-all.sh
Warning: $HADOOP_HOME is deprecated.
starting namenode, logging to /home/hadoop/hadoop/libexec/../logs/hadoop-hadoop-namenode-master.out
slave3: starting datanode, logging to /home/hadoop/hadoop/libexec/../logs/hadoop-hadoop-datanode-slave3.out
slave2: starting datanode, logging to /home/hadoop/hadoop/libexec/../logs/hadoop-hadoop-datanode-slave2.out
slave1: starting datanode, logging to /home/hadoop/hadoop/libexec/../logs/hadoop-hadoop-datanode-slave1.out
The authenticity of host 'master (192.168.56.200)' can't be established.
RSA key fingerprint is 63:e7:e2:e1:ae:bb:59:f8:ec:e8:23:e0:22:3e:ac:16.
Are you sure you want to continue connecting (yes/no)? yes
master: Warning: Permanently added 'master,192.168.56.200' (RSA) to the list of known hosts.
master: starting secondarynamenode, logging to /home/hadoop/hadoop/libexec/../logs/hadoop-hadoop-secondarynamenode-master.out
starting jobtracker, logging to /home/hadoop/hadoop/libexec/../logs/hadoop-hadoop-jobtracker-master.out
slave2: starting tasktracker, logging to /home/hadoop/hadoop/libexec/../logs/hadoop-hadoop-tasktracker-slave2.out
slave1: starting tasktracker, logging to /home/hadoop/hadoop/libexec/../logs/hadoop-hadoop-tasktracker-slave1.out
slave3: starting tasktracker, logging to /home/hadoop/hadoop/libexec/../logs/hadoop-hadoop-tasktracker-slave3.out这样集群就启动成功了。
7、 jps命令测试是否安装成功
master机器:
[hadoop@master ~]$ jps
2372 JobTracker
2298 SecondaryNameNode
2128 NameNode
2471 Jpsslave1机器:
[hadoop@slave1 ~]$ jps
2185 Jps
2019 DataNode
2106 TaskTrackerslave2机器:
[hadoop@slave2 ~]$ jps
2101 TaskTracker
2183 Jps
2013 DataNodeslave3机器:
[hadoop@slave3 ~]$ jps
2115 TaskTracker
2211 Jps
2041 DataNode至此hadoop集群的安装和启动就完成了,启动集群只需要在master机器上执行start-all.sh就可以。停止集群使用stop-all.sh命令。