Tensorflow使用Inception思想实现CIFAR-10十分类demo
返回目录:总目录——深度学习代码实战
使用Inception思想实现一个简单的CIFAR-10十分类.最主要的是领会Inception的结构.
Inception结构图如下:
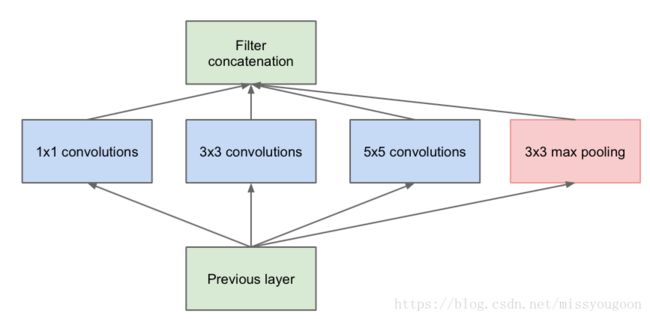
思想:
分别使用11,33,55卷积核和一个33最大池化层对上一层进行处理,然后将输入进行合并.
需要注意的是,因为最大池化之后,宽高都会发生变化,在合并的时候会出现问题,所以需要使用tf.pad()进行补齐.
上代码:
# -*- coding:utf-8 -*-
"""
@author:老艾
@file: neuton.py
@time: 2018/08/22
"""
import tensorflow as tf
import os
import numpy as np
import pickle
# 文件存放目录
CIFAR_DIR = "./cifar-10-batches-py"
def load_data( filename ):
'''read data from data file'''
with open( filename, 'rb' ) as f:
data = pickle.load( f, encoding='bytes' ) # python3 需要添加上encoding='bytes'
return data[b'data'], data[b'labels'] # 并且 在 key 前需要加上 b
class CifarData:
def __init__( self, filenames, need_shuffle ):
'''参数1:文件夹 参数2:是否需要随机打乱'''
all_data = []
all_labels = []
for filename in filenames:
# 将所有的数据,标签分别存放在两个list中
data, labels = load_data( filename )
all_data.append( data )
all_labels.append( labels )
# 将列表 组成 一个numpy类型的矩阵!!!!
self._data = np.vstack(all_data)
# 对数据进行归一化, 尺度固定在 [-1, 1] 之间
self._data = self._data / 127.5 - 1
# 将列表,变成一个 numpy 数组
self._labels = np.hstack( all_labels )
# 记录当前的样本 数量
self._num_examples = self._data.shape[0]
# 保存是否需要随机打乱
self._need_shuffle = need_shuffle
# 样本的起始点
self._indicator = 0
# 判断是否需要打乱
if self._need_shuffle:
self._shffle_data()
def _shffle_data( self ):
# np.random.permutation() 从 0 到 参数,随机打乱
p = np.random.permutation( self._num_examples )
# 保存 已经打乱 顺序的数据
self._data = self._data[p]
self._labels = self._labels[p]
def next_batch( self, batch_size ):
'''return batch_size example as a batch'''
# 开始点 + 数量 = 结束点
end_indictor = self._indicator + batch_size
# 如果结束点大于样本数量
if end_indictor > self._num_examples:
if self._need_shuffle:
# 重新打乱
self._shffle_data()
# 开始点归零,从头再来
self._indicator = 0
# 重新指定 结束点. 和上面的那一句,说白了就是重新开始
end_indictor = batch_size # 其实就是 0 + batch_size, 把 0 省略了
else:
raise Exception( "have no more examples" )
# 再次查看是否 超出边界了
if end_indictor > self._num_examples:
raise Exception( "batch size is larger than all example" )
# 把 batch 区间 的data和label保存,并最后return
batch_data = self._data[self._indicator:end_indictor]
batch_labels = self._labels[self._indicator:end_indictor]
self._indicator = end_indictor
return batch_data, batch_labels
# 拿到所有文件名称
train_filename = [os.path.join(CIFAR_DIR, 'data_batch_%d' % i) for i in range(1, 6)]
# 拿到标签
test_filename = [os.path.join(CIFAR_DIR, 'test_batch')]
# 拿到训练数据和测试数据
train_data = CifarData( train_filename, True )
test_data = CifarData( test_filename, False )
def inception_block(x, output_channel_for_each_path, name):
'''
inception结构函数
:param x: tensor
:param output_channel_for_each_path: 每一个组输出通道数 结构: eg: [10, 20, 5]
:param name: 防止重命名
:return: 已经合并好的tensor
'''
with tf.variable_scope(name):
conv1_1 = tf.layers.conv2d(x,
output_channel_for_each_path[0],
(1, 1),
strides = (1, 1),
padding = 'same',
activation = tf.nn.relu,
name = 'conv1_1'
)
conv3_3 = tf.layers.conv2d(x,
output_channel_for_each_path[1],
(3, 3),
strides=(1, 1),
padding='same',
activation=tf.nn.relu,
name='conv3_3'
)
conv5_5 = tf.layers.conv2d(x,
output_channel_for_each_path[2],
(5, 5),
strides=(1, 1),
padding='same',
activation=tf.nn.relu,
name='conv5_5'
)
max_pooling = tf.layers.max_pooling2d(x,
(2, 2),
(2, 2),
name = 'max_pooling'
)
# 因为池化层之后,宽高都变成了之前的一半,所以需要 tf.pad 进行补齐
max_pooling_shape = max_pooling.get_shape().as_list()[1:]
input_shape = x.get_shape().as_list()[1:]
width_padding = (input_shape[0] - max_pooling_shape[0]) // 2
height_padding = (input_shape[0] - max_pooling_shape[0]) // 2
padding_pooling = tf.pad(max_pooling,
[
[0, 0],
[width_padding, width_padding],
[height_padding, height_padding],
[0, 0]
]
)
# 接下来需要将 三个 卷积层 和 一个 池化层 拼接在一起,axis 是指定按照第几维合并
# 本实验其实就是把第四维进行合并
concat_layer = tf.concat([conv1_1, conv3_3, conv5_5, padding_pooling], axis = 3)
# axis = 3 第四个维度上合并,也就是在通道上合并
return concat_layer
# 设计计算图
# 形状 [None, 3072] 3072 是 样本的维数, None 代表位置的样本数量
x = tf.placeholder( tf.float32, [None, 3072] )
# 形状 [None] y的数量和x的样本数是对应的
y = tf.placeholder( tf.int64, [None] )
# [None, ], eg: [0, 5, 6, 3]
x_image = tf.reshape( x, [-1, 3, 32, 32] )
# 将最开始的向量式的图片,转为真实的图片类型
x_image = tf.transpose( x_image, perm= [0, 2, 3, 1] )
# conv1:神经元 feature_map 输出图像 图像大小: 32 * 32
conv1 = tf.layers.conv2d( x_image,
32, # 输出的通道数(也就是卷积核的数量)
( 3, 3 ), # 卷积核大小
padding = 'same',
activation = tf.nn.relu,
name = 'conv1'
)
# 池化层 图像输出为: 16 * 16
pooling1 = tf.layers.max_pooling2d( conv1,
( 2, 2 ), # 核大小 变为原来的 1/2
( 2, 2 ), # 步长
name='pool1'
)
inception_2a = inception_block(pooling1,
[16, 16, 16],
name = 'inception_2a'
)
inception_2b = inception_block(inception_2a,
[16, 16, 16],
name = 'inception_2b'
)
pooling2 = tf.layers.max_pooling2d( inception_2b,
( 2, 2 ), # 核大小 变为原来的 1/2
( 2, 2 ), # 步长
name='pool2'
)
inception_3a = inception_block(pooling2,
[16, 16, 16],
name = 'inception_3a'
)
inception_3b = inception_block(inception_3a,
[16, 16, 16],
name = 'inception_3b'
)
pooling3 = tf.layers.max_pooling2d( inception_3b,
( 2, 2 ), # 核大小 变为原来的 1/2
( 2, 2 ), # 步长
name='pool3'
)
flatten = tf.contrib.layers.flatten(pooling3)
y_ = tf.layers.dense(flatten, 10)
# 使用交叉熵 设置损失函数
loss = tf.losses.sparse_softmax_cross_entropy( labels = y, logits = y_ )
# 该api,做了三件事儿 1. y_ -> softmax 2. y -> one_hot 3. loss = ylogy
# 预测值 获得的是 每一行上 最大值的 索引.注意:tf.argmax()的用法,其实和 np.argmax() 一样的
predict = tf.argmax( y_, 1 )
# 将布尔值转化为int类型,也就是 0 或者 1, 然后再和真实值进行比较. tf.equal() 返回值是布尔类型
correct_prediction = tf.equal( predict, y )
# 比如说第一行最大值索引是6,说明是第六个分类.而y正好也是6,说明预测正确
# 将上句的布尔类型 转化为 浮点类型,然后进行求平均值,实际上就是求出了准确率
accuracy = tf.reduce_mean( tf.cast(correct_prediction, tf.float64) )
with tf.name_scope( 'train_op' ): # tf.name_scope() 这个方法的作用不太明白(有点迷糊!)
train_op = tf.train.AdamOptimizer( 1e-3 ).minimize( loss ) # 将 损失函数 降到 最低
# 初始化变量
init = tf.global_variables_initializer()
batch_size = 20
train_steps = 100000
test_steps = 100
with tf.Session() as sess:
sess.run( init ) # 注意: 这一步必须要有!!
# 开始训练
for i in range( train_steps ):
# 得到batch
batch_data, batch_labels = train_data.next_batch( batch_size )
# 获得 损失值, 准确率
loss_val, acc_val, _ = sess.run( [loss, accuracy, train_op], feed_dict={x:batch_data, y:batch_labels} )
# 每 500 次 输出一条信息
if ( i+1 ) % 500 == 0:
print('[Train] Step: %d, loss: %4.5f, acc: %4.5f' % ( i+1, loss_val, acc_val ))
# 每 5000 次 进行一次 测试
if ( i+1 ) % 5000 == 0:
# 获取数据集,但不随机
test_data = CifarData( test_filename, False )
all_test_acc_val = []
for j in range( test_steps ):
test_batch_data, test_batch_labels = test_data.next_batch( batch_size )
test_acc_val = sess.run( [accuracy], feed_dict={ x:test_batch_data, y:test_batch_labels } )
all_test_acc_val.append( test_acc_val )
test_acc = np.mean( all_test_acc_val )
print('[Test ] Step: %d, acc: %4.5f' % ( (i+1), test_acc ))
'''
训练一万次的最终结果:
=====================================================
[Train] Step: 10000, loss: 0.79420, acc: 0.75000
[Test ] Step: 10000, acc: 0.74150
=====================================================
'''