使用Requests+xpath实现简单的数据爬取
今天使用Requests+xpath实现简单的数据爬取,获取的是CSDN博客上的标题,发表时间,和阅读次数
##下载PyCharm
这里我使用的是PyCharm
http://www.jetbrains.com/pycharm/download/download-thanks.html?platform=windows&code=PCC
关于PyCharm的使用方法,和AndroidStudio是一样的,这里不在多说。
##正则表达式基础
- . 可以匹配任意字符,换行符\n除外
-
- 可以匹配前一个字符0次或无限次
- ?匹配前一个字符0次或者1次
- () 括号内的数据作为结果返回
###常用方法
- findall: 匹配所有复合规律的内容,返回包含结果的列表
- Search: 匹配并提取第一个复合规律的内容,返回一个正则表达式对象
- Sub: 替换复合规律的内容,返回替换后的值
##简单的正则demo
.的使用
a = "xzadkf"
b = re.findall('x...',a)
print b #输出['xzad']
*的使用
a = "xzaxkf"
b = re.findall('x*',a)
print b # ['x', '', '', 'x', '', '', '']
?的使用
a = "xzaxkf"
b = re.findall('x?',a)
print b # ['x', '', '', 'x', '', '', '']
rexStr = "adsfxxhelloxxiowengopfdwxxworldxxadjgoos"
b = re.findall('xx.*xx',rexStr) # 满足条件尽可能多的查找
print b # ['xxhelloxxiowengopfdwxxworldxx']
c = re.findall('xx.*?xx',rexStr)
print c # ['xxhelloxx', 'xxworldxx']
d = re.findall('xx(.*?)xx',rexStr)
print d # ['xxhelloxx', 'xxworldxx']
hello = '''adsfxxhello
xxiowengopfdwxxworldxxadjgoos'''
e = re.findall('xx(.*?)xx',hello,re.S)
print e
##获取标题
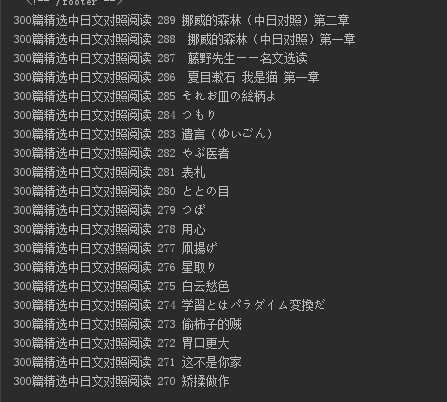
这里我们获取http://jp.tingroom.com/yuedu/yd300p/中的每个标题

![]()
html = requests.get('http://jp.tingroom.com/yuedu/yd300p/')
html.encoding = 'utf-8'
print html.text
title = re.findall('color: #039;">(.*?)',html.text,re.S)
for each in title:
print each
此时效果如下:
##安装xpath
使用pip安装xpath
pip install xpath
##抓取博客主页的内容
#.*-coding:utf-8-*-
import requests
import re
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
from lxml import etree
class spider(object):
# 获取url对应的网页源码
def getsource(self,url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0'}
sourceHtml = requests.get(url, headers=headers)
return sourceHtml.text
# 改变链接的地址页
def chagnePage(self,orginalStr):
currentPage = int(re.search('page=(\d+)', orginalStr, re.S).group(1))
pageGroup = []
for i in range(currentPage, currentPage + 3):
link = re.sub('page=\d+', 'page=%s' % i, orginalStr, re.S)
pageGroup.append(link)
return pageGroup
# 从html中解析我们需要的数据
def getNeedInfo(self,sourceHtml):
currentAllInfo = []
selector = etree.HTML(sourceHtml)
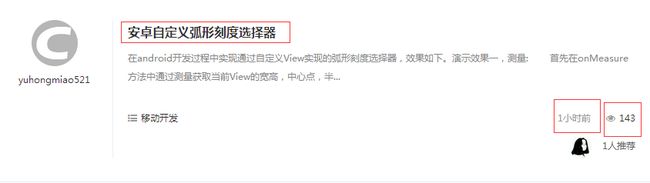
titles = selector.xpath('//dl[@class="blog_list clearfix"]//dd')
singlePageInfo = {};
for vs in titles:
info = vs.xpath('h3[@class="tracking-ad"]/a/text()')
print "标题:" + info[0]
singlePageInfo['title'] = info[0]
time = vs.xpath('div[@class="blog_list_b clearfix"]/div[@class="blog_list_b_r fr"]/label/text()')
print "时间:" + time[0]
singlePageInfo['time'] = time[0]
readCount = vs.xpath('div[@class="blog_list_b clearfix"]/div[@class="blog_list_b_r fr"]/span/em/text()')
print "阅读次数:" + readCount[0]
currentAllInfo.append(singlePageInfo)
print currentAllInfo
if __name__ == '__main__':
spider = spider()
url = "http://blog.csdn.net/?&page=1"
allPage = spider.chagnePage(url)
allPageInfo = []
for link in allPage:
print '正在处理:'+link
sourceHtml = spider.getsource(link)
spider.getNeedInfo(sourceHtml)

专注技术分享,包括Java,python,AI人工智能,Android分享,不定期更新学习视频,欢迎关注