基于简单seq to seq 的聊天机器人+代码实现 (tensorfow 1.1版本)
一、seq2seq模型简介
基本的Encoder-Decoder模型图如下:
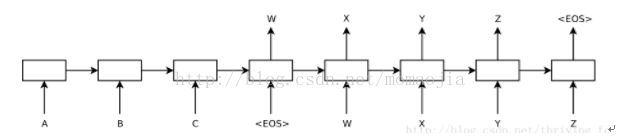
输入的序列为['A','B','C"]输出的序列为['W','X','Y','Z"]
二、tensorflow1.1 seq2seq接口
自从tensorflow1.0.0开始,出现新的seq2seq接口。新的接口主姚采用动态展开,旧接口是静态展开的。
静态展开: 指的是定义模型创建graph的时候,序列的长度是固定的,之后传入的所有序列都得是定义时指定的长度。这样所有的句子都要padding到指定的长度,很浪费存储空间,计算效率也不高。但想处理变长序列,也是有办法的,需要预先指定一系列的buckets,如[(5,10), (10, 15), (15, 20)]。
动态展开:使用控制流ops处理序列,可以不需要事先指定好序列长度。
三、seq2seq模型
搭建seq2seq模型,主要包括以下几方面的东西:
1. Encoder
2. Decoder
training decoder::decoder的输出已知
infereence decoder:decoder输出未知
3.seq2seq模型,把Encoder和Dccoder联系起来
4.建立图
5.训练模型
四、代码讲解
4.1每个句子特殊处理
(1)
(2)
(3)
(4)
4.2数据的输入
这部分主要包括对数据的预处理,分词等操作,把文本转化成对应的索引,
[[6, 28, 18, 14, 19, 3],
[10, 26, 3],
[16, 23, 11, 20, 3],
[16, 4, 15, 3]]
主要 代码如下:
4.3seq2seq模型搭建from distutils.version import LooseVersion
import tensorflow as tf
from tensorflow.python.layers.core import Dense
def get_inputs():
'''
模型输入tensor
'''
inputs = tf.placeholder(tf.int32, [None, None], name='inputs')
targets = tf.placeholder(tf.int32, [None, None], name='targets')
learning_rate = tf.placeholder(tf.float32, name='learning_rate')
target_sequence_length = tf.placeholder(tf.int32, (None,), name='target_sequence_length')
max_target_sequence_length = tf.reduce_max(target_sequence_length, name='max_target_len')
source_sequence_length = tf.placeholder(tf.int32, (None,), name='source_sequence_length')
return inputs, targets, learning_rate, target_sequence_length, max_target_sequence_length, source_sequence_length
def get_encoder_layer(input_data, rnn_size, num_layers,
source_sequence_length, source_vocab_size,
encoding_embedding_size):
encoder_embed_input = tf.contrib.layers.embed_sequence(input_data, source_vocab_size, encoding_embedding_size)
def get_lstm_cell(rnn_size):
lstm_cell = tf.contrib.rnn.LSTMCell(rnn_size, initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return lstm_cell
cell = tf.contrib.rnn.MultiRNNCell([get_lstm_cell(rnn_size) for _ in range(num_layers)])
encoder_output, encoder_state = tf.nn.dynamic_rnn(cell, encoder_embed_input,
sequence_length=source_sequence_length, dtype=tf.float32)
return encoder_output, encoder_state
def process_decoder_input(data, vocab_to_int, batch_size):
ending = tf.strided_slice(data, [0, 0], [batch_size, -1], [1, 1])
decoder_input = tf.concat([tf.fill([batch_size, 1], vocab_to_int['']), ending], 1)
return decoder_input
def decoding_layer(target_to_int, decoding_embedding_size, num_layers, rnn_size,target_sequence_length, max_target_sequence_length, encoder_state, decoder_input):
target_vocab_size = len(target_to_int)
decoder_embeddings = tf.Variable(tf.random_uniform([target_vocab_size, decoding_embedding_size]))
decoder_embed_input = tf.nn.embedding_lookup(decoder_embeddings, decoder_input)
def get_decoder_cell(rnn_size):
decoder_cell = tf.contrib.rnn.LSTMCell(rnn_size,
initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return decoder_cell
cell = tf.contrib.rnn.MultiRNNCell([get_decoder_cell(rnn_size) for _ in range(num_layers)])
#
output_layer = Dense(target_vocab_size,
kernel_initializer = tf.truncated_normal_initializer(mean = 0.0, stddev=0.1))
with tf.variable_scope("decode"):
training_helper = tf.contrib.seq2seq.TrainingHelper(inputs=decoder_embed_input,
sequence_length=target_sequence_length,
time_major=False)
training_decoder = tf.contrib.seq2seq.BasicDecoder(cell,
training_helper,
encoder_state,
output_layer)
training_decoder_output, _ = tf.contrib.seq2seq.dynamic_decode(training_decoder,
impute_finished=True,
maximum_iterations=max_target_sequence_length)
with tf.variable_scope("decode", reuse=True):
start_tokens = tf.tile(tf.constant([target_to_int['']], dtype=tf.int32), [batch_size],
name='start_tokens')
predicting_helper = tf.contrib.seq2seq.GreedyEmbeddingHelper(decoder_embeddings,
start_tokens,
target_to_int[''])
predicting_decoder = tf.contrib.seq2seq.BasicDecoder(cell,
predicting_helper,
encoder_state,
output_layer)
predicting_decoder_output, _ = tf.contrib.seq2seq.dynamic_decode(predicting_decoder,
impute_finished=True,
maximum_iterations=max_target_sequence_length)
return training_decoder_output, predicting_decoder_output
def seq2seq_model(input_data, targets, lr, target_sequence_length,
max_target_sequence_length, source_sequence_length,
source_vocab_size, target_vocab_size,
encoder_embedding_size, decoder_embedding_size,
rnn_size, num_layers):
#
_, encoder_state = get_encoder_layer(input_data,
rnn_size,
num_layers,
source_sequence_length,
source_vocab_size,
encoding_embedding_size)
decoder_input = process_decoder_input(targets, target_to_int, batch_size)
training_decoder_output, predicting_decoder_output = decoding_layer(target_to_int,
decoding_embedding_size,
num_layers,
rnn_size,
target_sequence_length,
max_target_sequence_length,
encoder_state,
decoder_input)
return training_decoder_output, predicting_decoder_output