curl在elasticSearch的应用
一、curl简介(摘自百度百科)
cURL是一个利用URL语法在命令行下工作的文件传输工具,1997年首次发行。它支持文件上传和下载,所以是综合传输工具,但按传统,习惯称cURL为下载工具。cURL还包含了用于程序开发的libcurl。
cURL支持的通信协议有FTP、FTPS、HTTP、HTTPS、TFTP、SFTP、Gopher、SCP、Telnet、DICT、FILE、LDAP、LDAPS、IMAP、POP3、SMTP和RTSP。
curl还支持SSL认证、HTTP POST、HTTP PUT、FTP上传, HTTP form based upload、proxies、HTTP/2、cookies、用户名+密码认证(Basic, Plain, Digest, CRAM-MD5, NTLM, Negotiate and Kerberos)、file transfer resume、proxy tunneling。
二、curl中put和post的区别
1)PUT是幂等方法,POST不是。所以PUT用户更新,POST用于新增比较合适。
2)PUT和DELETE操作是幂等的。所谓幂等是指不管进行多少次操作,结果都一样。比如用PUT修改一篇文章,然后在做同样的操作,每次操作后的结果并没有什么不同,DELETE也是一样。
3)POST操作不是幂等的,比如常见的POST重复加载问题:当我们多次发出同样的POST请求后,其结果是创建了若干的资源。
4)还有一点需要注意的就是,创建操作可以使用POST,也可以使用PUT,区别就在于POST是作用在一个集合资源(/articles)之上的,而PUT操作是作用在一个具体资源之上的(/articles/123),比如说很多资源使用数据库自增主键作为标识信息,这个时候就需要使用PUT了。而创建的资源的标识信息到底是什么,只能由服务端提供时,这个时候就必须使用POST。
- ES创建索引库和索引时的注意点:
①索引库名称必须要全部小写,不能以下划线开头,也不能包含逗号;
②如果没有明确指定索引数据的ID,那么es会自动生成一个随机的ID,需要使用POST参数:
curl -H "Content-Type: application/json" -XPOST
http://hadoop01:9200/bigdata/product/ -d '{"author" : "Doug Cutting"}'
创建成功:
二、curl在elasticSeach应用
-X 指定http的请求方法 有HEAD GET POST PUT DELETE
-d 指定要传输的数据
-H 指定http请求头信息
1、新建
1.1curl创建索引库
curl -H "Content-Type: application/json" -XPUT
http://:9200/index_name/
PUT或POST都可以创建
举例:
curl -H "Content-Type: application/json" -XPUT
'http://hadoop01:9200/bigdata'
创建成功:

1.2curl创建索引
curl -H "Content-Type: application/json" -XPOST 'http://localhost:9200/bigdata/product/1' -d
'{
"name" : "hadoop",
"author" : "Doug Cutting",
"core" : ["hdfs","mr","yarn"],
"latest_version": 3.0
}'
创建成功:
![]()
2、查询
2.1根据产品ID查询
curl -XGET http://hadoop01:9200/bigdata/product/1?pretty
在任意的查询url中添加pretty参数,这样可以获取更易识别的json结果。
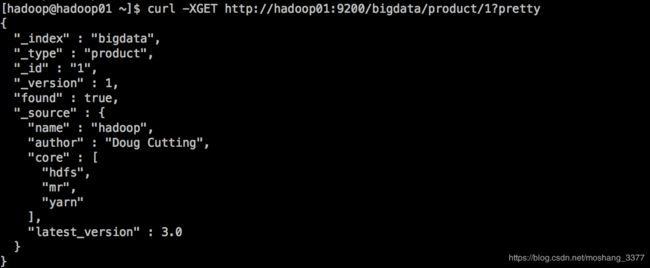
2.2检索文档中的一部分,显示特定的字段内容
curl -XGET ‘http://localhost:9200/bigdata/product/1?_source=name,author&pretty’
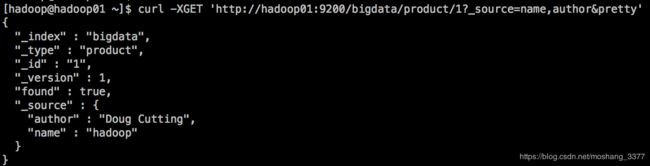
2.3获取source的数据
curl -XGET ‘http://hadoop01:9200/bigdata/product/1/_source?pretty’
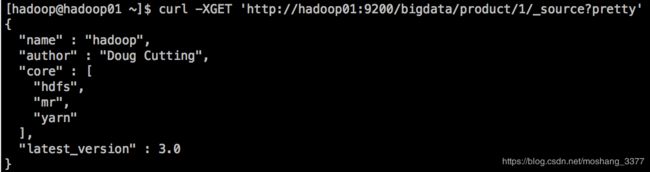
2.4查询所有
curl -XGET ‘http://hadoop01:9200/bigdata/product/_search?pretty’
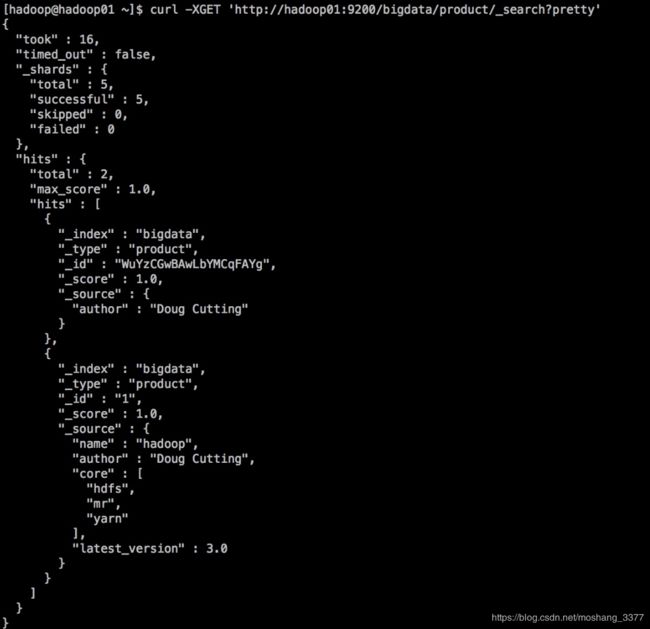
2.5根据条件进行查询
curl -XGET ‘http://hadoop01:9200/bigdata/product/_search?q=name:hadoop&pretty’
2.6大结果集的分页查询
格式:
curl -XGET http://hadoop01:9200/account/bank/_search?pretty&from={num}&size={size}
其中from代表的是从哪一条开始,最开始的索引是0,size代表查询多少条记录
es默认,每页显示10条记录,所以默认的操作其实就是如下:
curl -XGET http://hadoop01:9200/account/bank/_search?pretty&from=0&size=10
拓展——分页算法:
我们想查询第N页的数据,每页使用默认10记录
起始索引就是(N-1) * 10
http://bigdata01:9200/account/bank/_search?pretty&from=20&size=10
3、更新
ES可以使用PUT或者POST对文档进行更新,如果指定ID的文档已经存在,则执行更新操作
注意: 执行更新操作的时候,ES首先将旧的文档标记为删除状态,然后添加新的文档,旧的文档不会立即消失,但是你也无法访问,ES会继续添加更多数据的时候在后台清理已经标记为删除状态的文档。
3.1局部更新
可以添加新字段或者更新已经存在字段(必须使用POST)
curl -H "Content-Type: application/json" -XPOST http://hadoop01:9200/bigdata/product/1/_update -d '{"doc":{"name" : "apache-hadoop"}}'
![]()
4、ES删除
3.2普通删除,根据主键删除
curl -XDELETE http://localhost:9200/bigdata/product/3/
说明:如果文档存在,es属性found:true,successful:1,_version属性的值+1。
如果文档不存在,es属性found为false,但是版本值version依然会+1,这个就是内部
管理的一部分,有点像svn版本号,它保证了我们在多个节点间的不同操作的顺序被正确标记了。
注意: 一个文档被删除之后,不会立即生效,他只是被标记为已删除。ES将会在你之后添加更多索引的时候才会在后台进行删除。
4、批量操作-bulk
Bulk api可以帮助我们同时执行多个请求
格式:
action:[index|create|update|delete]
metadata:_index,_type,_id
request body:_source(删除操作不需要)
{action:{metadata}}\n
{request body}\n
{action:{metadata}}\n
{request body}\n
create和index的区别:
如果数据存在,使用create操作失败,会提示文档已经存在,使用index则可以成功执行。
使用文件的方式:
创建一个索引库来保存批量信息,index=account,type=bank
curl -XPUT -H "Content-Type: application/json" http://localhost:9200/account?pretty
执行批量操作:
curl -XPUT -H "Content-Type: application/json" http://localhost:9200/account/bank/_bulk?pretty --data-binary @/home/hadoop/data/accounts.json
如果出现如下报错信息:
"type" : "illegal_argument_exception",
"reason" : "The bulk request must be terminated by a '\n'
解决办法:
在json文件中的末尾加上一个换行符~