【资源聚合平台进度总结】Word2Vec+TextRank实现摘要生成技术
前言
在本系统中,由于自动获取的网络上的资源参差不齐,即使通过了机器的审核,仍然可能会给用户的检索带来很大困难。另一方面,现在大多主流的博客所谓自动生成摘要,其实都是自动截取前100个字符,这实在是辜负了现在人工智能和NLP技术的发展。
因此在我们的项目中,我们计划引入摘要生成技术,一是方便用户的检索查看,二是想看看能否利用其作为质量控制系统的一部分。
1958年,Luhn便提出了“词频”的方法,通过计算文章中“keywords”的出现频率找到文章的中心句子以此来生成文章摘要,这被当做文章摘要的鼻祖。在此基础上,Edmundson通过选取标题词、句子位置、线索词和关键词四种特征表示句子计算句子权重,通过句子的分数(权重)排序比较句子的重要性来生成摘要。后来,Mihalcea在google的算法pagerank的基础上提出了计算文章内在结构,主观上评价句子重要性的textrank算法,该算法意义重大极大的推动了自动文摘的发展。后来,更大的方法被发表出来包括比较著名的tf*idf算法。
以上的生成方式被称为“抽取式”,因为他们的主要工作都是找到可以最大限度概括全文的原文中的句子。他们大多采用的是统计的方式,并没有真正地去“理解”文章的内容。于是便出现了另一种文本摘要的方法,被称之为“生成式”方法,机器通过阅读文章然后来概括文章的大意。无疑这种方法难度较大,与传统的人工摘要一样,机器必须自己读懂文章才能生成摘要。
搜索网上的资料,有关生成式摘要的尝试,最具代表性的就是google在2016年发布的开源项目“TextSum”。在google的textsum项目中,用到了seq2seq+attention的深度学习模型,它是google翻译模型。简单的说这种模型是文章的content生成title的模型,RNN神经网络(循环神经网络)将content即文章的内容通过encoder(编码)生成一种sequence,然后另外一个RNN神经网络用来decoder(解码)生成文章的title。这个模型对训练数据的要求极为苛刻,如果不是专门清洗过的数据集,生成的句子语义都不通顺更别说组合成为摘要了,在stackoverflow论坛上,很多跑过这个程序都说其效果不佳。google自己也承认该项目有待优化。
后来终于发现了一个目前来说比较成熟的抽取式文本摘要方法,通word2vec生成词向量,再利用textrank的方法寻找文本的中心句形成摘要。这种方法被多个学术研究所发表,很多人都提出了各种改进的算法,例如
顾益军, 夏天. 融合 LDA 与 TextRank 的关键词抽取研究[J]. 现代图书情报技术, 2014(7-8): 41-47.
(Gu Yijun, XiaTian. Study on Keyword Extraction with LDA and
TextRankCombination [J]. New Technology of Library and
InformationService, 2014(7-8): 41-47.)
和
融合 Word2vec 与 TextRank 的关键词抽取研究宁建飞 刘降珍(罗定职业技术学院电子信息系 罗定 527200)
Word2Vec
word2vec也叫word embeddings,中文名“词向量”,作用就是将自然语言中的字词转为计算机可以理解的稠密向量(Dense Vector)。在word2vec出现之前,自然语言处理经常把字词转为离散的单独的符号,也就是One-Hot Encoder。
杭州 [0,0,0,0,0,0,0,1,0,……,0,0,0,0,0,0,0]
上海 [0,0,0,0,1,0,0,0,0,……,0,0,0,0,0,0,0]
宁波 [0,0,0,1,0,0,0,0,0,……,0,0,0,0,0,0,0]
北京 [0,0,0,0,0,0,0,0,0,……,1,0,0,0,0,0,0]
比如上面的这个例子,在语料库中,杭州、上海、宁波、北京各对应一个向量,向量中只有一个值为1,其余都为0。但是使用One-Hot Encoder有以下问题。一方面,城市编码是随机的,向量之间相互独立,看不出城市之间可能存在的关联关系。其次,向量维度的大小取决于语料库中字词的多少。如果将世界所有城市名称对应的向量合为一个矩阵的话,那这个矩阵过于稀疏,并且会造成维度灾难,即词的数量达到了一定程度,以亿计的单词用这种表示方法那肯定是极大的臃肿与恐怖。 word2vec在此基础上用低维的向量来表示单词,一般为50维或100维,这种向量被表示成这个样子:
[0.11212,0.116545,0.878789,0.5644659,……]
而Word2Vec实际上就是对上面的词向量做降维操作,将“每个词一个维度”这种尴尬的情况转换为在有限的维度中表示更多的单词。
word2vec模型其实就是简单化的神经网络。
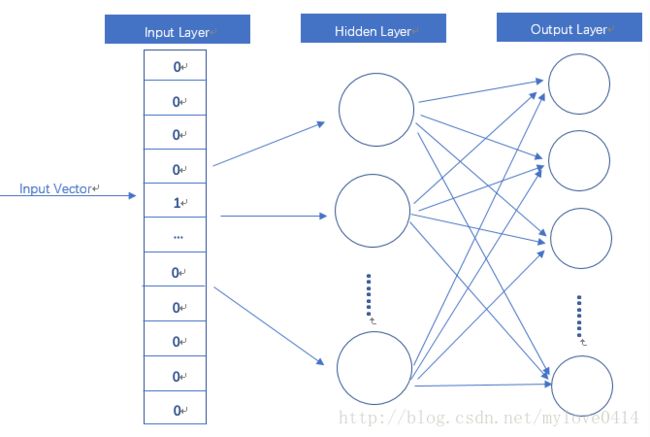
输入是One-Hot Vector,也就是刚才提到的最基础的词向量形式,Hidden Layer没有激活函数,也就是线性的单元。输出层神经元的个数可以自己设定,也就是最终得到的词向量的维度。
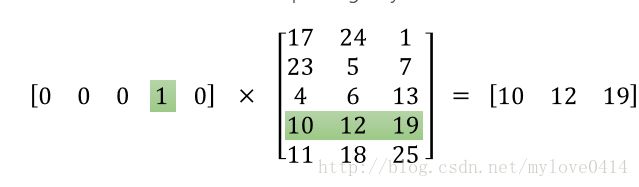
可以看出,word2vec实际做的工作实际上就是通过矩阵操作进行降维处理。更好的一个特性是,经过训练之后,我们可以得到,含义相近的单词,他们的词向量也是比较临近的,这就给我们进行自然语言处理提供了很好的基础。
word2vec的训练和使用现在已经有比较完善的python库:gensim
from gensim.models import word2vec
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentences = word2vec.LineSentence(u'./cut_std.txt')
model = word2vec.Word2Vec(sentences,size=300,window=5,min_count=5,workers=4)
model.save('./SRModel')
在我们的系统中,在一开始我使用了wiki的中文语料库来进行训练,但是在训练结束后,测试效果发现结果并不理想,分析原因后得出,这是由于词汇的范围不同,我们用来测试的文章大多是计算机有关。
因此我们想办法爬取了接近1个G的技术文章,筛除掉其中的代码后进行训练,最终得出了比较良好的效果(最终效果,包含接下来要讲的TextRank技术):

当然这还是比不上人类总结的,但是对于本项目已经足够。
TextRank算法
说道TextRank算法,大家肯定都会觉得它跟PageRank的名字有点像,但实际上,它就是PageRank的另一种形式。
简单介绍一下PageRank的基本思想,PageRank是Google发家的技术,用于做搜索页面的排行,它是如何得出一个页面与搜索内容的相关程度的呢?答案是,根据相关页面指向它的次数。一个页面被相关页面引用的越多,代表它越相关,同时,更相关的页面会给其引用的其他页面提供更大的权重。
化作公式就是:
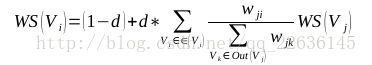
其中WS(Vi)代表i节点(对,以图的形式存储)的得分,d是阻尼系数,一般取0.85(经验得出)。
看到这里可能就有很多人可以反应过来了,这个算法中的节点从网页换做是句子也是完全可以的!当节点是句子时,这个得分的意义便是:与整篇文章最相关的句子。这自然就是我们需要的摘要了。
当然,句子无法以网页的连接来计算关联。这里暂停一下,想想我们刚才提到的Word2Vec,它生成的词向量拥有可以计算两个词之间相似度的特性。
那我们可以大胆地做个猜想,一个句子中,所有词向量相加求平均,得到的“词向量”可以代表这个句子的特征。实际上也是这样。因此,我们可以通过求两个句子的平均词向量之间的余弦相似度来得出句子之间的相似度。

然后计算每一句的相对于另一句的分数,具体方式在上述的pagerank的算法中。但是循环一次是得不到稳定结果的,遍历所有句子对所有句子的得分称为一个迭代,当本次迭代与上一次迭代修改的权重不超过0.0001,我们即可判断已经收敛,停止迭代,输出分数第n高的句子即为要抽取的n个句子,以此作为摘要。
#!/usr/bin/python
# -*- coding: utf-8 -*-
import jieba
import math
from string import punctuation
from heapq import nlargest
from itertools import product, count
from gensim.models import word2vec
import numpy as np
model = word2vec.Word2Vec.load("SRModel")
np.seterr(all='warn')
def cut_sentences(sentence):
puns = frozenset(u'。!?.?;!')
tmp = []
for ch in sentence:
tmp.append(ch)
if puns.__contains__(ch):
yield ''.join(tmp)
tmp = []
yield ''.join(tmp)
# 句子中的stopwords
def create_stopwords():
stop_list = [line.strip() for line in open("stopwords.txt", 'r', encoding='utf-8').readlines()]
return stop_list
def two_sentences_similarity(sents_1, sents_2):
'''''
计算两个句子的相似性
:param sents_1:
:param sents_2:
:return:
'''
counter = 0
for sent in sents_1:
if sent in sents_2:
counter += 1
return counter / (math.log(len(sents_1) + len(sents_2)))
def create_graph(word_sent):
"""
传入句子链表 返回句子之间相似度的图
:param word_sent:
:return:
"""
num = len(word_sent)
board = [[0.0 for _ in range(num)] for _ in range(num)]
for i, j in product(range(num), repeat=2):
if i != j:
board[i][j] = compute_similarity_by_avg(word_sent[i], word_sent[j])
return board
def cosine_similarity(vec1, vec2):
'''''
计算两个向量之间的余弦相似度
:param vec1:
:param vec2:
:return:
'''
tx = np.array(vec1)
ty = np.array(vec2)
cos1 = np.sum(tx * ty)
cos21 = np.sqrt(sum(tx ** 2))
cos22 = np.sqrt(sum(ty ** 2))
cosine_value = cos1 / float(cos21 * cos22)
return cosine_value
def compute_similarity_by_avg(sents_1, sents_2):
'''''
对两个句子求平均词向量
:param sents_1:
:param sents_2:
:return:
'''
if len(sents_1) == 0 or len(sents_2) == 0:
return 0.0
vec1 = model[sents_1[0]]
for word1 in sents_1[1:]:
vec1 = vec1 + model[word1]
vec2 = model[sents_2[0]]
for word2 in sents_2[1:]:
vec2 = vec2 + model[word2]
similarity = cosine_similarity(vec1 / len(sents_1), vec2 / len(sents_2))
return similarity
def calculate_score(weight_graph, scores, i):
"""
计算句子在图中的分数
:param weight_graph:
:param scores:
:param i:
:return:
"""
length = len(weight_graph)
d = 0.85
added_score = 0.0
for j in range(length):
fraction = 0.0
denominator = 0.0
# 计算分子
fraction = weight_graph[j][i] * scores[j]
# 计算分母
for k in range(length):
denominator += weight_graph[j][k]
if denominator == 0:
denominator = 1
added_score += fraction / denominator
# 算出最终的分数
weighted_score = (1 - d) + d * added_score
return weighted_score
def weight_sentences_rank(weight_graph):
'''''
输入相似度的图(矩阵)
返回各个句子的分数
:param weight_graph:
:return:
'''
# 初始分数设置为0.5
scores = [0.5 for _ in range(len(weight_graph))]
old_scores = [0.0 for _ in range(len(weight_graph))]
# 开始迭代
while different(scores, old_scores):
for i in range(len(weight_graph)):
old_scores[i] = scores[i]
for i in range(len(weight_graph)):
scores[i] = calculate_score(weight_graph, scores, i)
return scores
def different(scores, old_scores):
'''''
判断前后分数有无变化
:param scores:
:param old_scores:
:return:
'''
flag = False
for i in range(len(scores)):
if math.fabs(scores[i] - old_scores[i]) >= 0.0001:
flag = True
break
return flag
def filter_symbols(sents):
stopwords = create_stopwords() + ['。', ' ', '.']
_sents = []
for sentence in sents:
for word in sentence:
if word in stopwords:
sentence.remove(word)
if sentence:
_sents.append(sentence)
return _sents
def filter_model(sents):
_sents = []
for sentence in sents:
for word in sentence:
if word not in model:
sentence.remove(word)
if sentence:
_sents.append(sentence)
return _sents
def summarize(text, n):
tokens = cut_sentences(text)
sentences = []
sents = []
for sent in tokens:
sentences.append(sent)
sents.append([word for word in jieba.cut(sent) if word])
# sents = filter_symbols(sents)
print(len(sents))
filter_model(sents)
print(len(sents[0]))
filter_model(sents)
print(len(sents[0]))
graph = create_graph(sents)
scores = weight_sentences_rank(graph)
sent_selected = nlargest(n, zip(scores, count()))
sent_index = []
for i in range(n):
sent_index.append(sent_selected[i][1])
return [sentences[i] for i in sent_index]
if __name__ == '__main__':
with open("文档.txt", "r") as myfile:
text = myfile.read().replace('\n', '').decode('utf-8')
result = summarize(text, 3)
for res in result:
print(res.encode('utf-8'))
def summary_interface(text, n):
text = myfile.read().replace('\n', '').decode('utf-8')
result = summarize(text, 3)
encoding_result = []
for res in result:
encoding_result.append(res.encode('utf-8'))
return encoding_result
参考:
https://blog.csdn.net/qq_22636145/article/details/75099792
https://blog.csdn.net/mylove0414/article/details/61616617