hive udaf详解
原理
UDAF函数,简单地理解就是多行输入一行输出,其实就是一个聚合的过程,但聚合的过程可以在mapreduce任务中的多个地方可以实现,要了解UDAF的过程还需要清楚mapreduce的模型,请看下图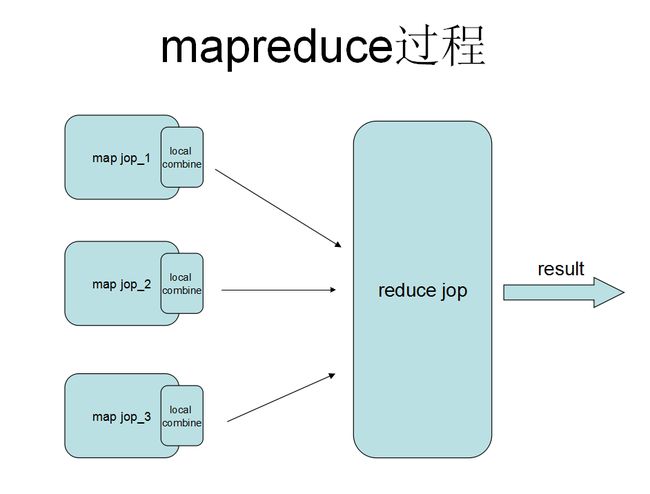
详解
聚合的过程在上述的图中,可以发生在map阶段,可以发生在local combie阶段,也可以发生在reduce阶段,不同阶段的聚合需要不同的实现函数,在源码里也表现定义抽象类:GenericUDAFEvaluator
public abstract class GenericUDAFEvaluator implements Closeable {
......
//用于初始化类;
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {
// This function should be overriden in every sub class
// And the sub class should call super.init(m, parameters) to get mode set.
mode = m;
return null;
}
//开辟新空间存储计算结果
public abstract AggregationBuffer getNewAggregationBuffer() throws HiveException;
//重置计算状态
public abstract void reset(AggregationBuffer agg) throws HiveException;
//map阶段调用,只要把保存当前和的对象agg,再加上输入的参数,就可以了。
public abstract void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException;
//mapper结束要返回的结果,还有combine结束返回的结果
public abstract Object terminatePartial(AggregationBuffer agg) throws HiveException;
//combiner合并map返回的结果,还有reducer合并mapper或combine返回的结果。
public abstract void merge(AggregationBuffer agg, Object partial) throws HiveException;
//reducer返回结果,或者是只有mapper,没有reducer时,在mapper端返回结果。
public abstract Object terminate(AggregationBuffer agg) throws HiveException;
......
//此函数是主要是对某条件范围内进行聚合时调用的(只是猜测,还没测试出来)
public GenericUDAFEvaluator getWindowingEvaluator(WindowFrameDef wFrmDef)
}当然可以从GenericUDAFEvaluator的内部枚举当中获取当前阶段的状态;
public static enum Mode {
/**
* PARTIAL1: 这个是mapreduce的map阶段:从原始数据到部分数据聚合
* 将会调用iterate()和terminatePartial()
*/
PARTIAL1,
/**
* PARTIAL2: 这个是mapreduce的map端的Combiner阶段,负责在map端合并map的数据::从部分数据聚合到部分数据聚合:
* 将会调用merge() 和 terminatePartial()
*/
PARTIAL2,
/**
* FINAL: mapreduce的reduce阶段:从部分数据的聚合到完全聚合
* 将会调用merge()和terminate()
*/
FINAL,
/**
* COMPLETE: 如果出现了这个阶段,表示mapreduce只有map,没有reduce,所以map端就直接出结果了:从原始数据直接到完全聚合
* 将会调用 iterate()和terminate()
*/
COMPLETE
};一般情况下,完整的UDAF逻辑是一个mapreduce过程,如果有mapper和reducer,就会经历PARTIAL1(mapper),FINAL(reducer),如果还有combiner,那就会经历PARTIAL1(mapper),PARTIAL2(combiner),FINAL(reducer)。而有一些情况下的mapreduce,只有mapper,而没有reducer,所以就会只有COMPLETE阶段,这个阶段直接输入原始数据,出结果。
下面以count的功能的UDAF函数进行详解;
hive sql任务:select chepai.oil_type,mcount(chepai.oil_type) from chepai group by chepai.oil_type;
sql任务由一个map,三个reduce任务组成;
//调试源码
package org.hive.segment;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.parse.SemanticException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFParameterInfo;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFResolver2;
import org.apache.hadoop.hive.ql.util.JavaDataModel;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.LongObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
import org.apache.hadoop.io.LongWritable;;
/**
* This class implements the COUNT aggregation function as in SQL.
*/
@Description(name = "count",
value = "_FUNC_(*) - Returns the total number of retrieved rows, including "
+ "rows containing NULL values.\n"
+ "_FUNC_(expr) - Returns the number of rows for which the supplied "
+ "expression is non-NULL.\n"
+ "_FUNC_(DISTINCT expr[, expr...]) - Returns the number of rows for "
+ "which the supplied expression(s) are unique and non-NULL.")
public class udafCount implements GenericUDAFResolver2 {
private static final Log LOG = LogFactory.getLog(udafCount.class.getName());
@Override
public GenericUDAFEvaluator getEvaluator(TypeInfo[] parameters)
throws SemanticException {
// This method implementation is preserved for backward compatibility.
return new udafCountEvaluators();
}
@Override
public GenericUDAFEvaluator getEvaluator(GenericUDAFParameterInfo paramInfo)
throws SemanticException {
TypeInfo[] parameters = paramInfo.getParameters();
if (parameters.length == 0) {
if (!paramInfo.isAllColumns()) {
throw new UDFArgumentException("Argument expected");
}
assert !paramInfo.isDistinct() : "DISTINCT not supported with *";
} else {
if (parameters.length > 1 && !paramInfo.isDistinct()) {
throw new UDFArgumentException("DISTINCT keyword must be specified");
}
assert !paramInfo.isAllColumns() : "* not supported in expression list";
}
return new udafCountEvaluators().setCountAllColumns(
paramInfo.isAllColumns());
}
/**
* GenericUDAFCountEvaluator.
*
*/
public static class udafCountEvaluators extends GenericUDAFEvaluator {
private boolean countAllColumns = false;
//用于反序列化数据对象
private LongObjectInspector partialCountAggOI;
private LongWritable result;
//Mode mode;
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters)
throws HiveException {
super.init(m, parameters);
LOG.info("..............job at part:"+m.name()+"..........");
if (m == Mode.PARTIAL2 || m == Mode.FINAL) {
partialCountAggOI = (LongObjectInspector)parameters[0];
}
result = new LongWritable(0);
return PrimitiveObjectInspectorFactory.writableLongObjectInspector;
}
private udafCountEvaluators setCountAllColumns(boolean countAllCols) {
countAllColumns = countAllCols;
return this;
}
/** class for storing count value,即是缓存数据 */
@AggregationType(estimable = true)
static class CountAgg extends AbstractAggregationBuffer {
long value;
@Override
public int estimate() { return JavaDataModel.PRIMITIVES2; }
}
@Override
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
CountAgg buffer = new CountAgg();
reset(buffer);
LOG.info("setion_1: getNewAggregationBuffer .......");
return buffer;
}
@Override
public void reset(AggregationBuffer agg) throws HiveException {
((CountAgg) agg).value = 0;
LOG.info("setion_2: reset .......");
}
@Override
public void iterate(AggregationBuffer agg, Object[] parameters)
throws HiveException {
// parameters == null means the input table/split is empty
//后面添加的测试,日志就不放上来了,判断value值只是为了减少日志量;
if(((CountAgg) agg).value>100){
if(strObject!=null){
LOG.info("setion_3: iterate .......");
for(int i=0;i//parameters的类型是LazyString,不能强制转换数据为String;
LOG.info("Parameters:"+((StringObjectInspector)(strObject)).getPrimitiveJavaObject(parameters[i]));
}
}
}
LOG.info("setion_3: iterate .......");
if (parameters == null) {
return;
}
if (countAllColumns) {
assert parameters.length == 0;
((CountAgg) agg).value++;
} else {
boolean countThisRow = true;
for (Object nextParam : parameters) {
if (nextParam == null) {
countThisRow = false;
break;
}
}
if (countThisRow) {
((CountAgg) agg).value++;
}
}
}
@Override
public void merge(AggregationBuffer agg, Object partial)
throws HiveException {
LOG.info("setion_4: merge .......");
if (partial != null) {
long p = partialCountAggOI.get(partial);
((CountAgg) agg).value += p;
}
}
//最终被调用返回结果;
@Override
public Object terminate(AggregationBuffer agg) throws HiveException {
result.set(((CountAgg) agg).value);
LOG.info("setion_5: terminate .......");
return result;
}
@Override
public Object terminatePartial(AggregationBuffer agg) throws HiveException {
LOG.info("setion_6: terminatePartial .......");
return terminate(agg);
}
}
}
//map runlong
2015-08-11 10:51:51,699 INFO [main] org.apache.hadoop.hive.ql.exec.SelectOperator: Operator 1 SEL initialized
2015-08-11 10:51:51,699 INFO [main] org.apache.hadoop.hive.ql.exec.SelectOperator: Initializing children of 1 SEL
2015-08-11 10:51:51,699 INFO [main] org.apache.hadoop.hive.ql.exec.GroupByOperator: Initializing child 2 GBY
2015-08-11 10:51:51,699 INFO [main] org.apache.hadoop.hive.ql.exec.GroupByOperator: Initializing Self GBY[2]
2015-08-11 10:51:51,751 INFO [main] org.hive.segment.udafCount: ..............job at part:PARTIAL1..........
2015-08-11 10:51:51,752 INFO [main] org.hive.segment.udafCount: setion_2: reset .......
2015-08-11 10:51:51,752 INFO [main] org.hive.segment.udafCount: setion_1: getNewAggregationBuffer .......
2015-08-11 10:51:51,753 INFO [main] org.hive.segment.udafCount: setion_2: reset .......
2015-08-11 10:51:51,753 INFO [main] org.hive.segment.udafCount: setion_1: getNewAggregationBuffer .......
2015-08-11 10:51:51,778 INFO [main] org.apache.hadoop.hive.ql.exec.GroupByOperator: Operator 2 GBY initialized
2015-08-11 10:51:51,778 INFO [main] org.apache.hadoop.hive.ql.exec.GroupByOperator: Initializing children of 2 GBY
2015-08-11 10:51:51,778 INFO [main] org.apache.hadoop.hive.ql.exec.ReduceSinkOperator: Initializing child 3 RS
2015-08-11 10:51:51,778 INFO [main] org.apache.hadoop.hive.ql.exec.ReduceSinkOperator: Initializing Self RS[3]
2015-08-11 10:51:51,780 INFO [main] org.apache.hadoop.hive.ql.exec.ReduceSinkOperator: Using tag = -1
2015-08-11 10:51:52,005 INFO [main] org.apache.hadoop.hive.ql.exec.ReduceSinkOperator: Operator 3 RS initialized
2015-08-11 10:51:52,005 INFO [main] org.apache.hadoop.hive.ql.exec.ReduceSinkOperator: Initialization Done 3 RS
2015-08-11 10:51:52,005 INFO [main] org.apache.hadoop.hive.ql.exec.GroupByOperator: Initialization Done 2 GBY
2015-08-11 10:51:52,005 INFO [main] org.apache.hadoop.hive.ql.exec.SelectOperator: Initialization Done 1 SEL
2015-08-11 10:51:52,005 INFO [main] org.apache.hadoop.hive.ql.exec.TableScanOperator: Initialization Done 0 TS
2015-08-11 10:51:52,005 INFO [main] org.apache.hadoop.hive.ql.exec.MapOperator: Initialization Done 4 MAP
2015-08-11 10:51:52,048 INFO [main] org.hive.segment.udafCount: setion_2: reset .......
2015-08-11 10:51:52,048 INFO [main] org.hive.segment.udafCount: setion_1: getNewAggregationBuffer .......
2015-08-11 10:51:52,048 INFO [main] org.hive.segment.udafCount: setion_3: iterate .......
2015-08-11 10:51:52,049 INFO [main] org.apache.hadoop.hive.ql.exec.MapOperator: MAP[4]: records read - 1
2015-08-11 10:51:52,049 INFO [main] org.hive.segment.udafCount: setion_3: iterate .......
2015-08-11 10:51:52,049 INFO [main] org.hive.segment.udafCount: setion_3: iterate .......
2015-08-11 10:51:52,049 INFO [main] org.hive.segment.udafCount: setion_3: iterate .......
2015-08-11 10:51:52,049 INFO [main] org.hive.segment.udafCount: setion_3: iterate .......
2015-08-11 10:51:52,049 INFO [main] org.hive.segment.udafCount: setion_3: iterate .......
2015-08-11 10:51:52,049 INFO [main] org.hive.segment.udafCount: setion_3: iterate .......
2015-08-11 10:51:52,049 INFO [main] org.hive.segment.udafCount: setion_3: iterate .......
2015-08-11 10:51:52,049 INFO [main] org.hive.segment.udafCount: setion_3: iterate .......
2015-08-11 10:51:52,049 INFO [main] org.hive.segment.udafCount: setion_3: iterate .......
2015-08-11 10:51:52,049 INFO [main] org.apache.hadoop.hive.ql.exec.MapOperator: MAP[4]: records read - 10
2015-08-11 10:51:52,049 INFO [main] org.hive.segment.udafCount: setion_3: iterate .......
2015-08-11 10:51:52,049 INFO [main] org.hive.segment.udafCount: setion_3: iterate .......
2015-08-11 10:51:52,049 INFO [main] org.hive.segment.udafCount: setion_3: iterate .......
2015-08-11 10:51:52,049 INFO [main] org.hive.segment.udafCount: setion_3: iterate .......
2015-08-11 10:51:52,050 INFO [main] org.hive.segment.udafCount: setion_3: iterate .......
2015-08-11 10:51:52,050 INFO [main] org.hive.segment.udafCount: setion_2: reset .......
2015-08-11 10:51:52,050 INFO [main] org.hive.segment.udafCount: setion_1: getNewAggregationBuffer .......
2015-08-11 10:51:52,050 INFO [main] org.hive.segment.udafCount: setion_3: iterate .......
2015-08-11 10:51:52,050 INFO [main] org.hive.segment.udafCount: setion_3: iterate .......
//reduce runlog
2015-08-11 10:52:43,731 INFO [main] org.apache.hadoop.hive.ql.exec.GroupByOperator: Initializing Self GBY[0]
2015-08-11 10:52:43,743 INFO [main] org.hive.segment.udafCount: ..............job at part:FINAL..........
2015-08-11 10:52:43,744 INFO [main] org.hive.segment.udafCount: setion_2: reset .......
2015-08-11 10:52:43,744 INFO [main] org.hive.segment.udafCount: setion_1: getNewAggregationBuffer .......
2015-08-11 10:52:43,747 INFO [main] org.apache.hadoop.hive.ql.exec.GroupByOperator: Operator 0 GBY initialized
2015-08-11 10:52:43,747 INFO [main] org.apache.hadoop.hive.ql.exec.GroupByOperator: Initializing children of 0 GBY
2015-08-11 10:52:43,747 INFO [main] org.apache.hadoop.hive.ql.exec.SelectOperator: Initializing child 1 SEL
2015-08-11 10:52:43,747 INFO [main] org.apache.hadoop.hive.ql.exec.SelectOperator: Initializing Self SEL[1]
2015-08-11 10:52:43,747 INFO [main] org.apache.hadoop.hive.ql.exec.SelectOperator: SELECT struct<_col0:string,_col1:bigint>
2015-08-11 10:52:43,747 INFO [main] org.apache.hadoop.hive.ql.exec.SelectOperator: Operator 1 SEL initialized
2015-08-11 10:52:43,747 INFO [main] org.apache.hadoop.hive.ql.exec.SelectOperator: Initializing children of 1 SEL
2015-08-11 10:52:43,747 INFO [main] org.apache.hadoop.hive.ql.exec.FileSinkOperator: Initializing child 2 FS
2015-08-11 10:52:43,747 INFO [main] org.apache.hadoop.hive.ql.exec.FileSinkOperator: Initializing Self FS[2]
2015-08-11 10:52:43,747 INFO [main] org.apache.hadoop.conf.Configuration.deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
2015-08-11 10:52:43,777 INFO [main] org.apache.hadoop.conf.Configuration.deprecation: mapred.healthChecker.script.timeout is deprecated. Instead, use mapreduce.tasktracker.healthchecker.script.timeout
2015-08-11 10:52:43,779 INFO [main] org.apache.hadoop.hive.ql.exec.FileSinkOperator: Operator 2 FS initialized
2015-08-11 10:52:43,779 INFO [main] org.apache.hadoop.hive.ql.exec.FileSinkOperator: Initialization Done 2 FS
2015-08-11 10:52:43,779 INFO [main] org.apache.hadoop.hive.ql.exec.SelectOperator: Initialization Done 1 SEL
2015-08-11 10:52:43,779 INFO [main] org.apache.hadoop.hive.ql.exec.GroupByOperator: Initialization Done 0 GBY
2015-08-11 10:52:43,782 INFO [main] org.hive.segment.udafCount: setion_2: reset .......
2015-08-11 10:52:43,782 INFO [main] org.hive.segment.udafCount: setion_4: merge .......
2015-08-11 10:52:43,782 INFO [main] org.hive.segment.udafCount: setion_5: terminate .......
2015-08-11 10:52:43,782 INFO [main] org.apache.hadoop.hive.ql.exec.FileSinkOperator: Final Path: FS hdfs://uruncluster/datas/hadoop/hdp/tmp/hive/hdfs/544ba723-d852-4bdc-844f-8b9ab62e6619/hive_2015-08-11_10-51-34_252_8711439857738442726-1/_tmp.-ext-10001/000000_0
2015-08-11 10:52:43,783 INFO [main] org.apache.hadoop.hive.ql.exec.FileSinkOperator: Writing to temp file: FS hdfs://uruncluster/datas/hadoop/hdp/tmp/hive/hdfs/544ba723-d852-4bdc-844f-8b9ab62e6619/hive_2015-08-11_10-51-34_252_8711439857738442726-1/_task_tmp.-ext-10001/_tmp.000000_0
2015-08-11 10:52:43,783 INFO [main] org.apache.hadoop.hive.ql.exec.FileSinkOperator: New Final Path: FS hdfs://uruncluster/datas/hadoop/hdp/tmp/hive/hdfs/544ba723-d852-4bdc-844f-8b9ab62e6619/hive_2015-08-11_10-51-34_252_8711439857738442726-1/_tmp.-ext-10001/000000_0
2015-08-11 10:52:43,883 INFO [main] org.apache.hadoop.hive.ql.exec.FileSinkOperator: FS[2]: records written - 1
2015-08-11 10:52:43,883 INFO [main] org.hive.segment.udafCount: setion_2: reset .......
2015-08-11 10:52:43,883 INFO [main] org.hive.segment.udafCount: setion_4: merge .......
2015-08-11 10:52:43,883 INFO [main] org.hive.segment.udafCount: setion_5: terminate .......
2015-08-11 10:52:43,883 INFO [main] org.hive.segment.udafCount: setion_2: reset .......
2015-08-11 10:52:43,883 INFO [main] org.hive.segment.udafCount: setion_4: merge .......
2015-08-11 10:52:43,883 INFO [main] org.apache.hadoop.hive.ql.exec.GroupByOperator: 0 finished. closing...
2015-08-11 10:52:43,883 INFO [main] org.hive.segment.udafCount: setion_5: terminate .......
2015-08-11 10:52:43,883 INFO [main] org.apache.hadoop.hive.ql.exec.SelectOperator: 1 finished. closing...
2015-08-11 10:52:43,884 INFO [main] org.apache.hadoop.hive.ql.exec.FileSinkOperator: 2 finished. closing...
2015-08-11 10:52:43,884 INFO [main] org.apache.hadoop.hive.ql.exec.FileSinkOperator: FS[2]: records written - 3
2015-08-11 10:52:44,127 INFO [main] org.apache.hadoop.hive.ql.exec.FileSinkOperator: RECORDS_OUT:3
2015-08-11 10:52:44,127 INFO [main] org.apache.hadoop.hive.ql.exec.FileSinkOperator: 2 Close done
2015-08-11 10:52:44,127 INFO [main] org.apache.hadoop.hive.ql.exec.SelectOperator: 1 Close done
2015-08-11 10:52:44,127 INFO [main] org.apache.hadoop.hive.ql.exec.GroupByOperator: 0 Close done
2015-08-11 10:52:44,127 INFO [main] org.apache.hadoop.mapred.Task: Task:attempt_1437935091736_30472_r_000000_0 is done. And is in the process of committing
2015-08-11 10:52:44,165 INFO [main] org.apache.hadoop.mapred.Task: Task 'attempt_1437935091736_30472_r_000000_0' done.
2015-08-11 10:52:44,166 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Stopping ReduceTask metrics system...
2015-08-11 10:52:44,167 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: ReduceTask metrics system stopped.
2015-08-11 10:52:44,167 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: ReduceTask metrics system shutdown complete.可以看到接口方法的调用过程是符合我们的之前的分析的,但仅能了解这些对于写UDAF函数仍然有困难的,需要了解其大概的过程以及主要的类;
我们知道,Hive最终生成的MapReduce任务,Map阶段和Reduce阶段均由OperatorTree组成。逻辑操作符,就是在Map阶段或者Reduce阶段完成单一特定的操作。详细请看http://www.open-open.com/lib/view/open1400644430159.html
基本的操作符包括TableScanOperator,SelectOperator,FilterOperator,JoinOperator,GroupByOperator,ReduceSinkOperator
从名字就能猜出各个操作符完成的功能,TableScanOperator从MapReduce框架的Map接口原始输入表的数据,控制扫描表的数据行数,标记是从原表中取数据。JoinOperator完成Join操作。FilterOperator完成过滤操作
ReduceSinkOperator将Map端的字段组合序列化为Reduce Key/value, Partition Key,只可能出现在Map阶段,同时也标志着Hive生成的MapReduce程序中Map阶段的结束。
Operator在Map Reduce阶段之间的数据传递都是一个流式的过程。每一个Operator对一行数据完成操作后之后将数据传递给childOperator计算。
Operator类的主要属性和方法如下
•RowSchema表示Operator的输出字段
•InputObjInspector outputObjInspector解析输入和输出字段
•processOp接收父Operator传递的数据,forward将处理好的数据传递给子Operator处理
•Hive每一行数据经过一个Operator处理之后,会对字段重新编号,colExprMap记录每个表达式经过当前Operator处理前后的名称对应关系,在下一个阶段逻辑优化阶段用来回溯字段名
•由于Hive 的MapReduce程序是一个动态的程序,即不确定一个MapReduce Job会进行什么运算,可能是Join,也可能是GroupBy,所以Operator将所有运行时需要的参数保存在OperatorDesc 中,OperatorDesc在提交任务前序列化到HDFS上,在MapReduce任务执行前从HDFS读取并反序列化。Map阶段 OperatorTree在HDFS上的位置在Job.getConf(“hive.exec.plan”) + “/map.xml”
从map任务可以看到任务是从MapOperator开始的,简单地描述为下述过程
public abstract class GenericUDAFEvaluator implements Closeable {
......
public void aggregate(AggregationBuffer agg, Object[] parameters) throws HiveException {
if (mode == Mode.PARTIAL1 || mode == Mode.COMPLETE) {
iterate(agg, parameters);
} else {
assert (parameters.length == 1);
merge(agg, parameters[0]);
}
}
}//WindowingTableFunction 类继承自TableFunctionEvaluator
public class WindowingTableFunction extends TableFunctionEvaluator {
.......
@Override
public Listpublic class PTFOperator extends Operator<PTFDesc> implements Serializable {
//持有PTFInvocation 对象;
transient PTFInvocation ptfInvocation;
@Override
public void process(Object row, int tag) throws HiveException {
if (!isMapOperator ) {
/*
* checkif current row belongs to the current accumulated Partition:
* - If not:
* - process the current Partition
* - reset input Partition
* - set currentKey to the newKey if it is null or has changed.
*/
newKeys.getNewKey(row, inputObjInspectors[0]);
boolean keysAreEqual = (currentKeys != null && newKeys != null)?
newKeys.equals(currentKeys) : false;
if (currentKeys != null && !keysAreEqual) {
ptfInvocation.finishPartition();
}
if (currentKeys == null || !keysAreEqual) {
ptfInvocation.startPartition();
if (currentKeys == null) {
currentKeys = newKeys.copyKey();
} else {
currentKeys.copyKey(newKeys);
}
}
} else if ( firstMapRow ) {
ptfInvocation.startPartition();
firstMapRow = false;
}
ptfInvocation.processRow(row);
}
}
class PTFInvocation {
//持有TableFunctionEvaluator对象
TableFunctionEvaluator tabFn;
//调用TableFunctionEvaluator 的processRow方法;WindowingTableFunction 实现了TableFunctionEvaluator
void processRow(Object row) throws HiveException {
if ( isStreaming() ) {
handleOutputRows(tabFn.processRow(row));
} else {
inputPart.append(row);
}
}
}
至此再去看看MapOperator是何被调用的就可以大概了解其过程了,现在只需要了解其输入是什么类封装的就可以了,后面再详解。