Hadoop-2.7.5 + Spark-2.2.0分布式集群搭建过程(2)
文章目录
- 接上篇 https://blog.csdn.net/muumian123/article/details/90201286
- 5.3 启动并验证Hadoop分布式集群
- 5.3.1 启动Hadoop分布式集群
- 5.3.2 验证Hadoop 分布式集群
- 至此,我们成功构建了Hadoop 分布式集群并完成了测试!
- 六、搭建 Spark集群
- 6.1 安装Scala - 2.12.4
- 6.1.1 Scala下载
- 6.1.2 Scala安装配置
- 6.1.3 其他服务器安装配置Scala
- 6.2 安装配置Python
- 6.3 安装配置 Spark2.2.0
- 6.3.1 安装Spark2.2.0
- 6.3.2.配置spark集群
- 6.3.3 启动Spark 集群
- 6.3.4.测试Spark 集群
- 上述信息表明程序成功在Spark 集群上运行.
- 至此,Spark集群搭建并测试完毕!
- 6.3.5 PyCharm远程连接Spark
- 至此,Hadoop+Spark分布式集群搭建全部完毕并测试成功!
接上篇 https://blog.csdn.net/muumian123/article/details/90201286
5.3 启动并验证Hadoop分布式集群
5.3.1 启动Hadoop分布式集群
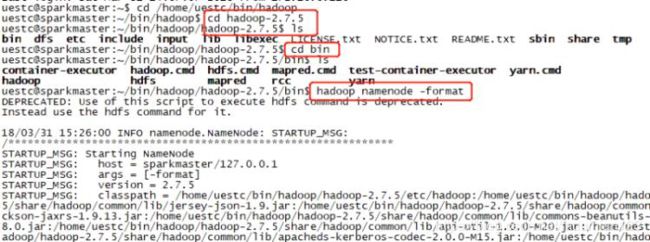
- 格式化hdfs文件系统:
hadoop namenode -format
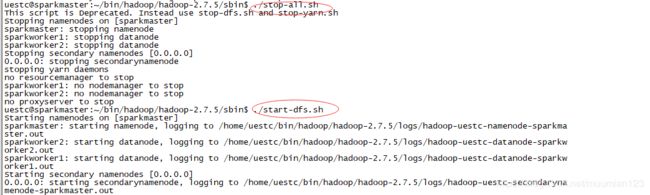
- 进入 sbin 中启动 hdfs:
./start-dfs.sh

注意:如果出现上图中错误,需先将hdfs进行关闭再重新开启,如下图所示:

- 在sparkworker1 和sparkworker2 上均启动了DataNode:


- 访问 http://sparkmaster:50070/ 登录Web控制可以查看HDFS集群的状况:
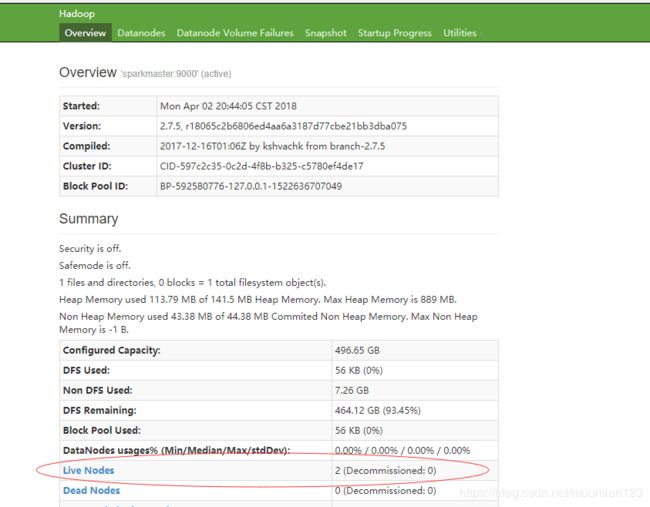
- 从控制台我们可以看见有两个DataNode,此时我们点击“Live Nodes”查看一下其信息:

从控制台中看到了我们的两个Datanode 节点sparkworker1 和sparkworker2。
- 启动 yarn 集群:
./start-yarn.sh- 使用jps 命令可以发现 SparkMaster 机器上启动了ResourceManager 进程

- 在 sparkworker1 和sparkworker2上则分别启动了 NodeManager 进程:


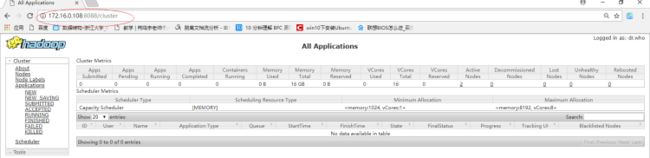
- 在 sparkmaster 上访问 http://sparkmaster:8088 可以通过 Web 控制台查看 ResourceManager
运行状态:
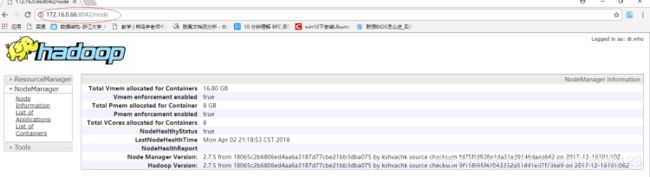
- 在sparkmaster 上访问 http://sparkworker1:8042 可以通过 Web 控制台查看 sparkworker1 上
的NodeManager 运行状态:
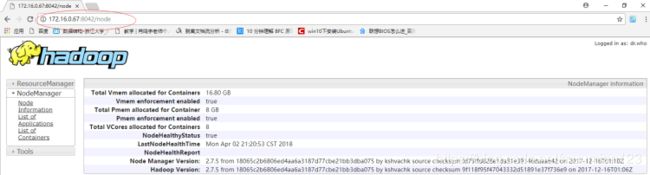
- 在sparkmaster 上访问 http://sparkworker2:8042 可以通过 Web 控制台查看 sparkworker2 上
的 Node Manager 运行状态:
- 使用“mr-jobhistory-daemon.sh”来启动JobHistory Server:
./mr-jobhistory-daemon.sh start historyserver

启动后可以通过 http://sparkmaster:19888 在Web 控制台上看到JobHistory 中的任务执行历史信
息:

结束historyserver 的命令为:./mr-jobhistory-daemon.sh stop historyserver

- 使用jps 命令可以发现 SparkMaster 机器上启动了ResourceManager 进程
5.3.2 验证Hadoop 分布式集群
- 在 hdfs 文件系统上创建两个目录,创建过程如下所示:
hadoop fs -mkdir -p /data/wordcount
hadoop fs -mkdir -p /output

HDFS 中的/data/wordcount 用来存放Hadoop 自带的WordCount 例子的数据文件,程序运行的结果输出到/output/wordcount 目录中,透过Web 控制可以发现我们成功创建了两个文件夹:

- 将本地文件的数据上传到HDFS 文件夹中:
hadoop fs -put ../etc/hadoop/*.xml /data/wordcount

- 通过 Web 控制可以发现我们成功上传了文件
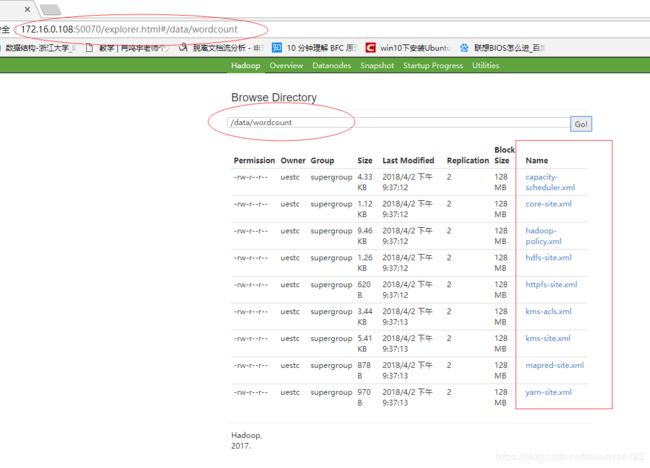
也可以通过 Hadoop 的 hdfs 命令在控制命令终端查看信息
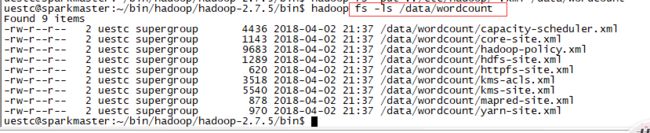
- 运行 Hadoop 自带的 WordCount 例子,执行如下命令:
hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar
wordcount /data/wordcount /output/wordcount
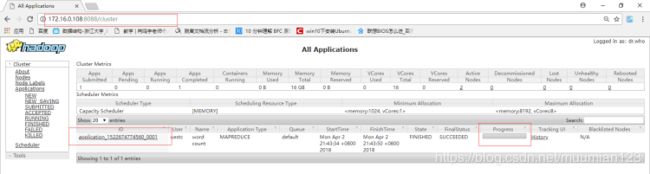
- 当我们在运行作业的过程中也可以查看 Web 控制台的信息,此时发现了一个作业 ID,点击进入可以查看作业进一步的信息:
- 进一步看通过Web 控制台看 SparkWorker1 中的 Container 中的运行信息:
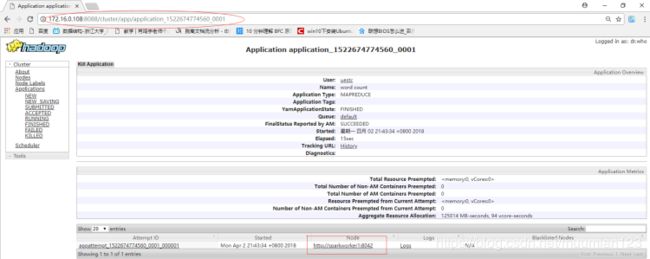
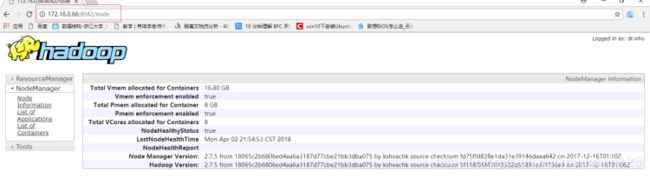
- 查看一下SparkWorker2 上的运行情况:
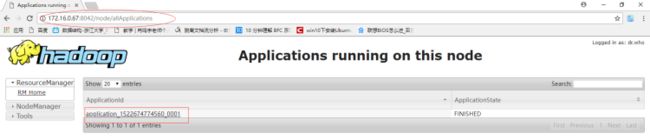
- 进一步看通过Web 控制台看 SparkWorker1 中的 Container 中的运行信息:
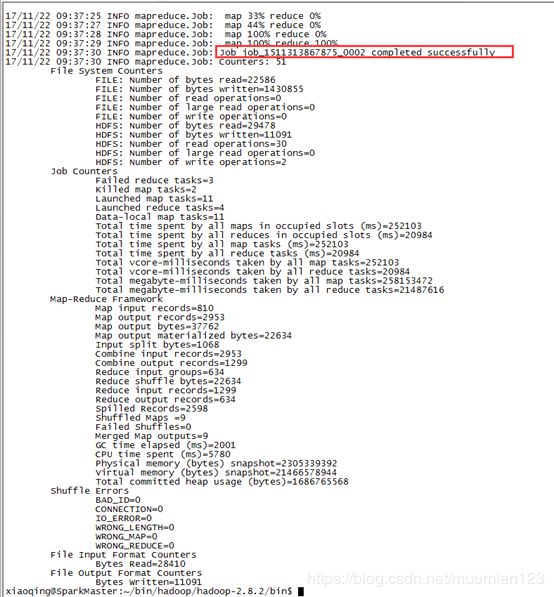
- 程序运行结束后我们可以执行一下命令查看运行结果:
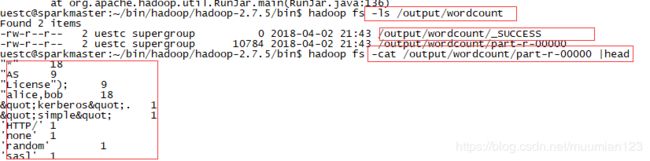
也可通过HDFS 控制台查看运行结果:
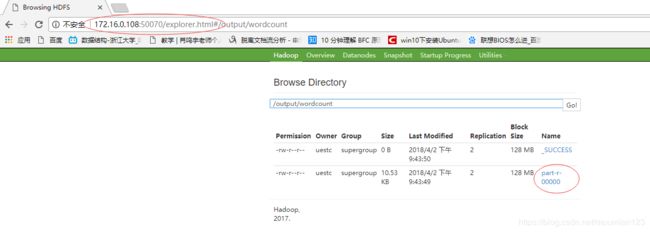
至此,我们成功构建了Hadoop 分布式集群并完成了测试!
六、搭建 Spark集群
6.1 安装Scala - 2.12.4
6.1.1 Scala下载
wget https://downloads.lightbend.com/scala/2.12.4/scala-2.12.4.tgz
6.1.2 Scala安装配置
- 创建新目录:
mkdir /home/uestc/bin/scalar - 将下载的Scala移动至新建文件夹中:
mv /home/uestc/桌面/soft/scala-2.12.4.tgz /home/uestc/bin/scalar - 解压文件夹:
tar -xvf scala-2.12.4.tgz - 配置Scala:
# a. 修改环境变量:
sudo vim /etc/profile
# b. 在末尾添加
export SCALA_HOME=/home/uestc/bin/scalar/scala-2.12.4
export PATH=$SCALA_HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/sbin:
$SPARK_HOME/bin:$PATH:/usr/bin
# c. 保存退出后使配置文件生效:
source /etc/profile
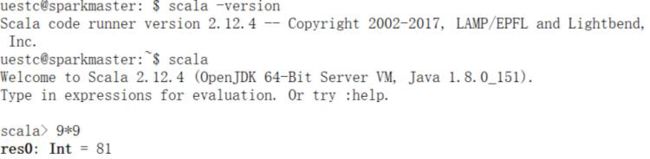
- 检测Scala:
# a. 检测版本:
scala -version
# b. 输入9*9进行测试,得到预期输出值
6.1.3 其他服务器安装配置Scala
运用scp在sparkworker1和sparkworker2上安装Scala并采用上面相同的方式进行配置环境和检测:
scp -r [email protected]:/ home/uestc/bin/scalar /home/uestc/bin/scalar
6.2 安装配置Python
Spark默认版本Python2,本项目使用python2,所以不进行安装测试了。(备注:saprk支持python3,但目前不支持python3.6)
6.3 安装配置 Spark2.2.0
6.3.1 安装Spark2.2.0
- 下载Spark2.2.0:
wget http://mirror.bit.edu.cn/apache/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz - 在sparkmaster上安装和配置Spark2.2.0集群
# a. 创建新目录:
mkdir /home/uestc/bin/spark
# b. 将下载的spark移动至新建文件夹中:
mv /home/uestc/桌面/soft/spark-2.2.0-binhadoop2.7
/home/uestc/bin/spark
# c. 解压文件夹:
tar -xvf spark-2.2.0-bin-hadoop2.7
# d. 配置Spark:
sudo vim /etc/profile
export SPARK_HOME=/home/uestc/bin/spark/spark-2.2.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile
- 进入 spark 的 conf 目录

6.3.2.配置spark集群
打开spark-2.2.0文件夹(cd spark-2.2.0)此处需要配置的文件为两个:spark-env.sh和slaves
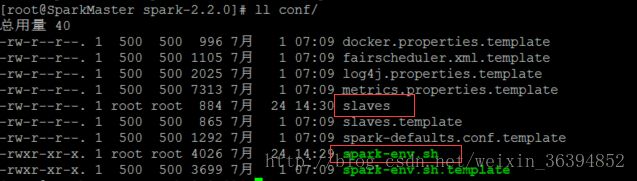
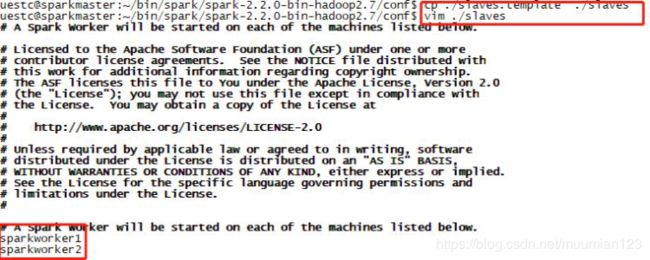
- 修改文件名
cp ./slaves.template ./slaves
cp ./spark-env.sh.template ./spark-env.sh

- 修改 slaves 文件:vim ./slaves并将末尾修改为以下内容:
sparkworker1
sparkworker2
- 配置 spark-env.sh文件:
vim conf/spark-env.sh
export JAVA_HOME=/home/uestc/bin/java/jdk1.8.0_162
export SCALA_HOME=/home/uestc/bin/scalar/scala-2.12.4
export HADOOP_HOME=/home/uestc/bin/hadoop/hadoop-2.7.5
export HADOOP_CONF_DIR=/home/uestc/bin/hadoop/hadoop-2.7.5/etc/hadoop
export SPARK_MASTER_IP=sparkmaster
export SPARK_WORKER_MEMORY=1g
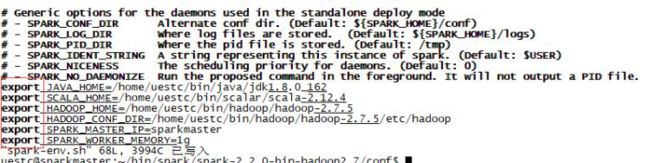
- sparkworker1 和 sparkworker2 采用和 sparkmaster 完全一样的 Spark 安装配置
scp -r [email protected]:/home/uestc/bin/spark /home/uestc/bin/spark
6.3.3 启动Spark 集群
启动 Spark 分布式集群并查看信息
- 启动Hadoop集群,在sparkmaster使用 jps命令
./start-dfs.sh
./start-yarn.sh
./mr-jobhistory-daemon.sh start historyserver
具体操作如下:
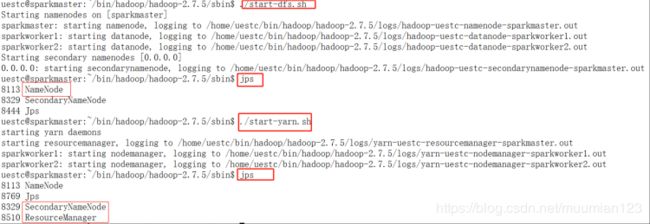

在 sparkworker1 和sparkworker2 上使用 jps会看到如下进程信息:


- 启动 Spark 集群
- 在Hadoop 集群成功启动的基础上,启动Spark 集群需要使用Spark 的sbin 目录下
start-all.sh:(注意指令运行目录)
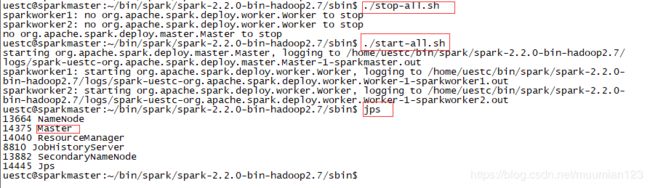
- 查看 SparkWorker1 和 SparkWorker2 会出现新的进程“Worker”:


- 进入 Spark 集群的 Web 页面,访问“http://SparkMaster:8080”:
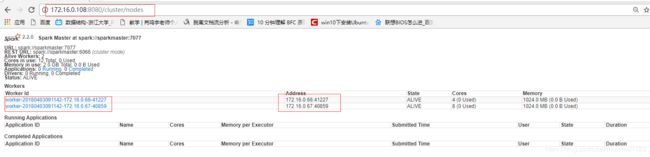
从页面上我们可以看到我们有两个Worker 节点及这两个节点的信息。 - 进入 Spark 的 bin 目录,使用“spark-shell”控制台:
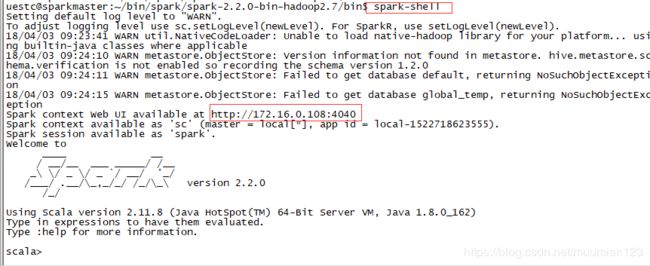
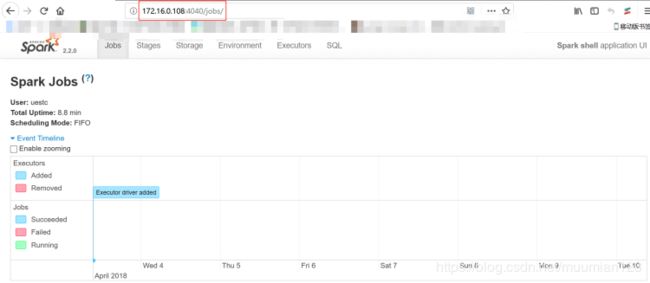
此时已经进入了Spark 的shell 世界,根据输出的提示信息,我们可以通过“http://sparkmaster:4040” 从Web 的角度看一下SparkUI 的情况,如下图所示:
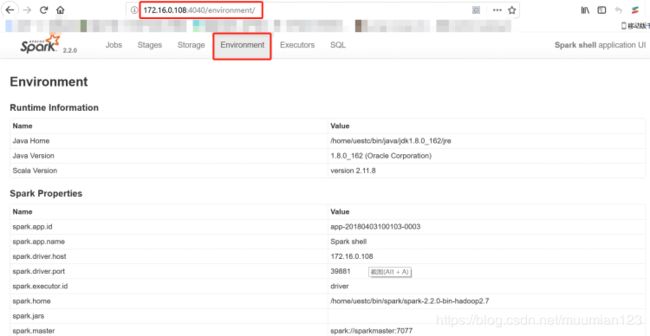
可以查看“Environment”信息,如下:
6.3.4.测试Spark 集群
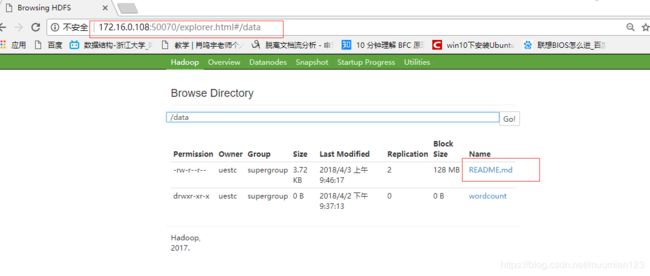
- 把 Spark 安装包下的”README.txt”上传到hdfs:
hadoop fs -put README.md /data/

通过 hdfs 的 web 控制台可以发现成功上传了文件
- 使用
MASTER=spark://SparkMaster:7077 ./spark-shell命令启动 Spark shell,正确的退出指令为::quit
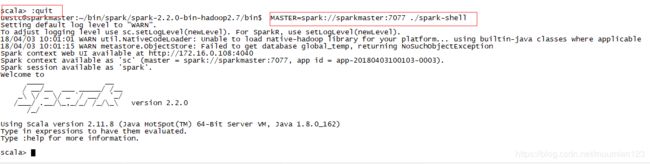
- 通过以下命令读取刚刚上传到 HDFS 上的“README.md”文件 :
val file = sc.textFile("hdfs://SparkMaster:9000/data/README.md")

- 对读取的文件进行操作:
val count = file.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_)

- 使用 collect 命令提交并执行 Job:
count.collect

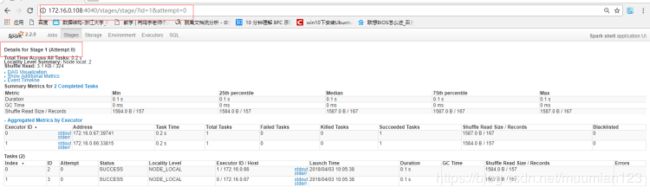
- 从控制台可以查看程序成功在集群上运行:

- Detail for Stage 1:
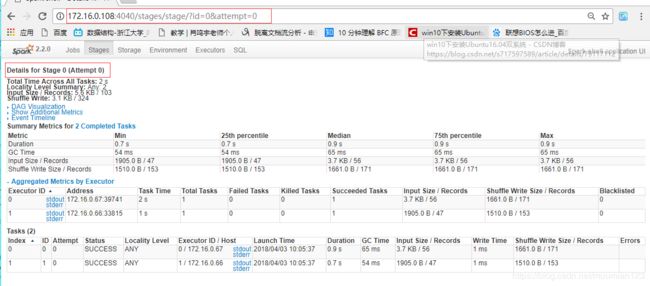
- Detail for Stage 0:
- 查看 Executors 的信息:
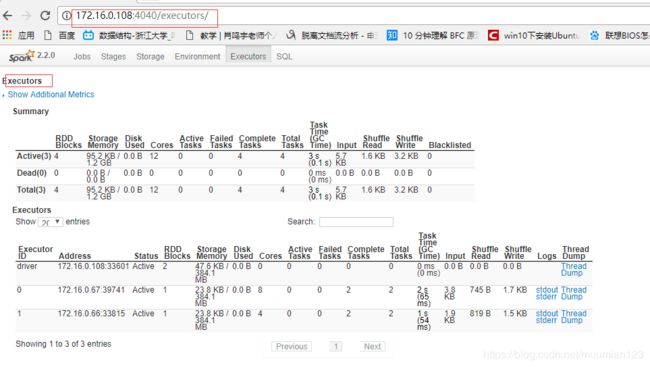
上述信息表明程序成功在Spark 集群上运行.
至此,Spark集群搭建并测试完毕!
6.3.5 PyCharm远程连接Spark
- 服务器端安装配置
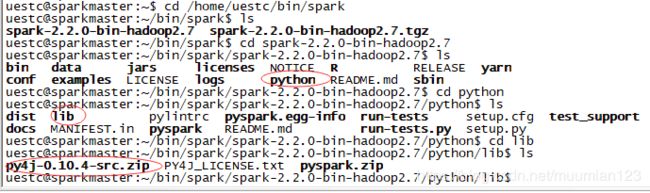
- 查询Python位置
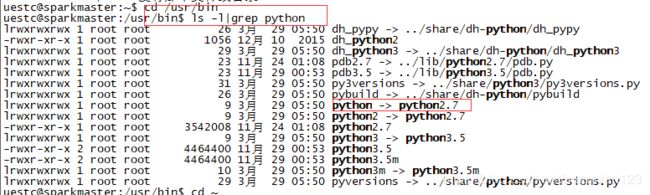
在sparkmaster的/user/bin下查找到自带的python,并使用ls -l|grep python进入(该语句为列出子目录下的详细信息。注意,此处的python是一个链接而不是目录,故不能通过cd进入)
- 配置环境变量
如果配置环境变量中误删了/usr/bin之类文件夹导致sudo、ls等基本命令不能使用,可以使用添加临时环境变量的方式,即在控制台直接输入:export PATH="/usr/sbin:/usr/bin:/usr/local/bin:/usr/local/sbin:/bin:/sbin",能够正常使用之后务必找到之前配置错的环境变量将其进行更改,否则 sudo 等命令只是暂时可以正常使用。
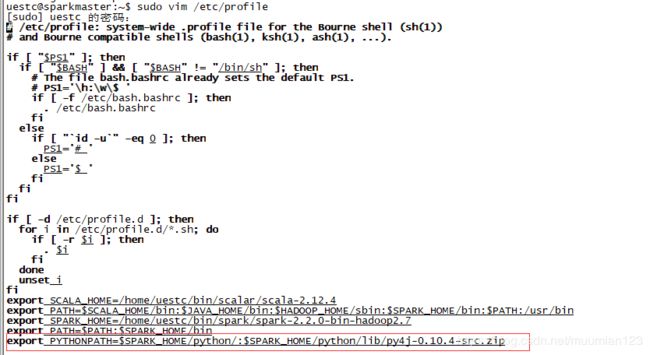
vim /etc/profile
export PYTHONPATH=$SPARK_HOME/python/:$SPARK_HOME/python/lib/py4j-0.10.4-src.zip
source /etc/profile
- 安装pip
wget https://bootstrap.pypa.io/get-pip.py --no-check-certificate
python get-pip.py
如遇权限问题,在指令前加入sudo。
- 安装py4j:
pip install py4j - 本地PyCharm配置
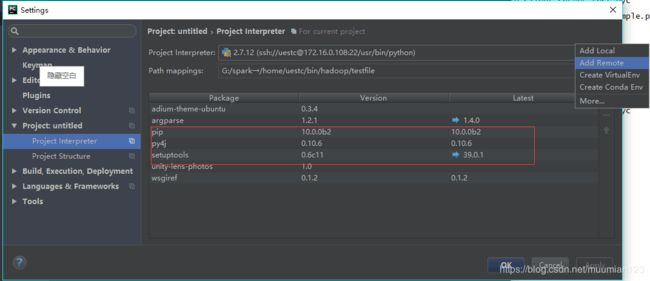
- File > Settings > Project Interpreter> Add remote:
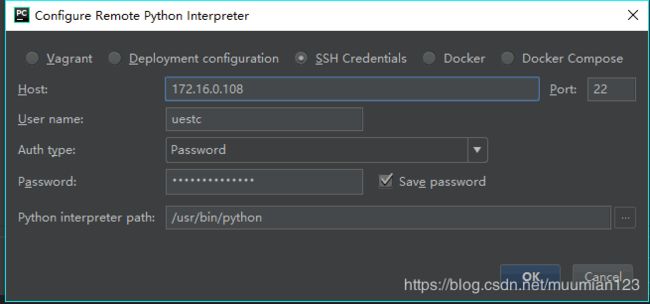
- Run > Edit Configuration
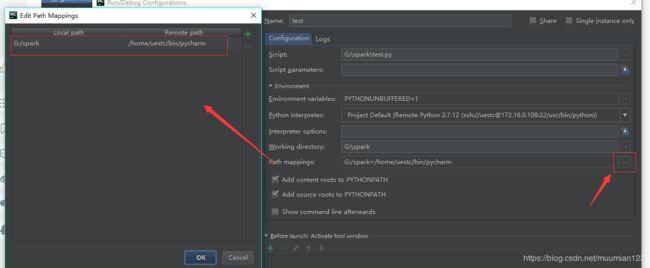
- Tools > Dployment > Configuration
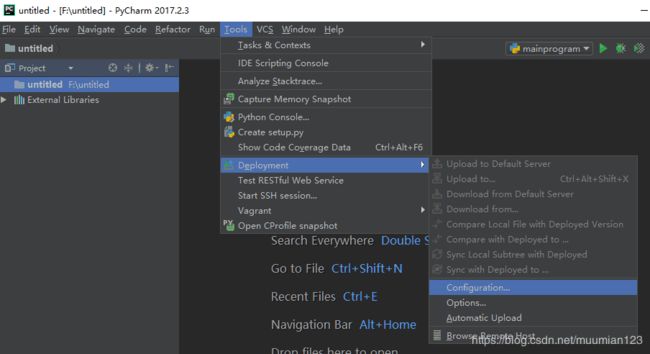
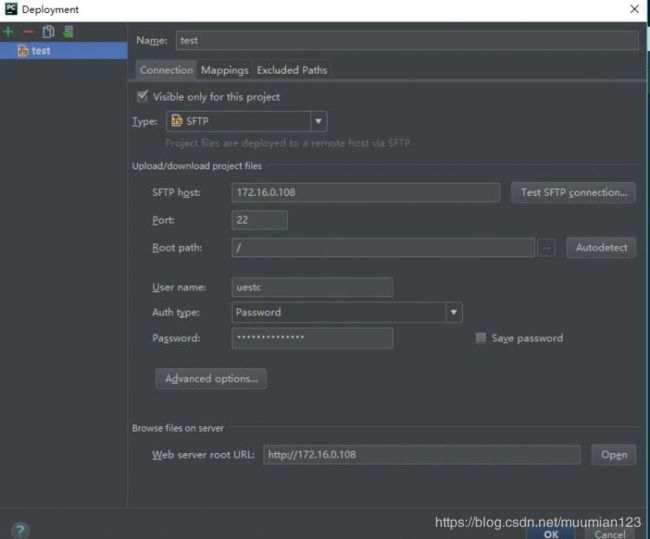
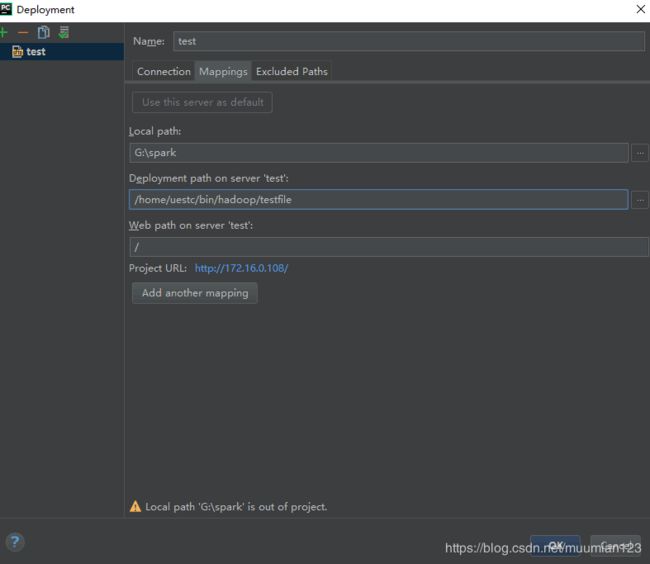
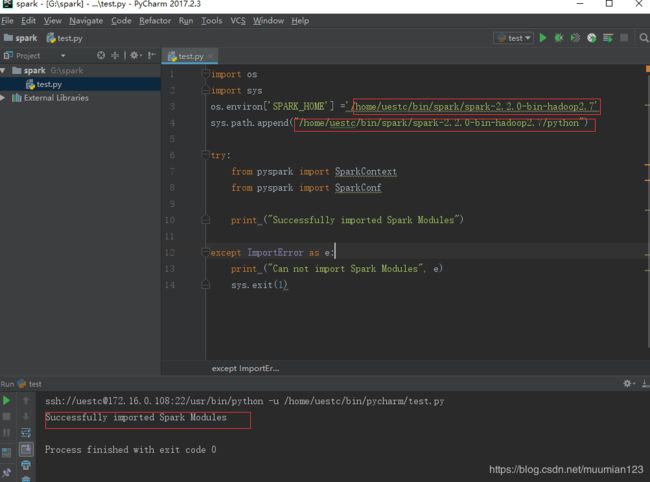
- 测试验证
在刚才建立的test.py中输入以下代码:
- File > Settings > Project Interpreter> Add remote:
import os
import sys
os.environ['SPARK_HOME'] ='/home/uestc/bin/spark/spark-2.2.0-bin-hadoop2.7'
sys.path.append("/home/uestc/bin/spark/spark-2.2.0-bin-hadoop2.7/python")
try:
from pyspark import SparkContext
from pyspark import SparkConf
print ("Successfully imported Spark Modules")
except ImportError as e:
print ("Can not import Spark Modules", e)
sys.exit(1)