ES(elasticsearch)搜索引擎安装和使用
大数据时代,搜索无处不在。搜索技术是全栈工程师必备技术之一,如今是开源时代,数不尽的资源供我们利用,如果要自己写一套搜索引擎无疑是浪费绳命。本节主要介绍搜索引擎开源项目elasticSearch的安装和使用
请尊重原创,转载请注明来源网站www.shareditor.com以及原始链接地址
为什么需要搜索引擎
首先想一下:在一篇文章里找一个关键词怎么找?字符串匹配是最佳答案。
然后再想一下:找到100篇文章里包含某个关键词的文章列表怎么找?依然是关键词匹配
再继续想:找到100000000000(一千亿)篇文章里包含某个关键词的文章怎么找?如果用关键词匹配,以现在的电脑处理速度,从远古时代到人类灭绝这么长时间都处理不完,这时候搜索引擎要发挥作用了
搜索引擎技术有多么高深?
搜索引擎这种技术实际上从古代就有了。想象一个国家存储各类编撰资料的部门,有几个屋子的书,如果想找到某一本书的时候会怎么找呢?对了,有分类目录,先确定要找的书籍是哪个类别的,然后从目录里面找到想要找的书籍位于屋子的什么位置,然后再去拿。搜索引擎其实就是做了生成目录(也就是索引)的事情。那么如今的搜索引擎是怎么生成索引的呢?
要把互联网上的资料生成索引,拢共分三步:第一步,把资料编号;第二步,把每篇资料内容切成词;第三步,把词和资料编号的对应关系处理成“词=》编号列表”的形式
这时候你就可以迅速的找到一千亿篇文章里包含某个关键词的文章了,告诉我关键词是什么,我直接就从索引里找到了这个词对应的文章编号列表了,搞定!把需要数万年才能做完的工作用了不到一秒钟就搞定了,这就是搜索引擎的魅力!
当然,上面说的搜索引擎技术很简单,但百度数万工程师也不都是白吃饭的,如果想做好一个搜索引擎产品需要解决的问题就有很多了:收集网页时要考虑全、快、稳、新、优的问题,建索引时要考虑质量、效率、赋权、周期、时效性、资源消耗等问题,搜索的时候要考虑query分析、排序、筛选、展示、性能、广告、推荐、个性化、统计等问题,整体上要考虑地域性、容灾、国际化、当地法律、反作弊、垂直需求、移动互联网等诸多问题,所以百度大厦彻夜通明也是可以理解的。
开源搜索引擎
既然搜索引擎技术这么复杂,那么我们何必自寻烦恼了,开源社区为我们提供了很多资源,世界很美好。
说到开源搜索引擎一定要用的开源项目就是lucene,它不是搜索引擎产品,而是一个类库,而且是至今开源搜索引擎的最好的类库没有之一,因为只有它一个。lucene是用Java语言开发,基本上涵盖了搜索引擎中索引和检索两个核心部分的全部功能,而且抽象的非常好,我后面会单独写数篇文章专门讲lucene的使用。最后强调一遍,它是一个类库,不是搜索引擎,你可以比较容易的基于lucene写一个搜索引擎。
然后要说的一个开源项目是solr,这是一个完整的搜索引擎产品,当然它底层一定是基于lucene的,毫无疑问,因为lucene是最好且唯一的搜索引擎类库。solr使用方法请看我的另一篇文章《教你一步步搭建和运行完整的开源搜索引擎》
最后要说的就是elasticSearch,这个开源项目也可以说是一个产品级别的开源项目,当然它底层一定是基于lucene的,毫无疑问,因为lucene是最好且唯一的搜索引擎类库,我承认我是唐僧。它是一种提供了RESTful api的服务,RESTful就是直接通过HTTP协议收发请求和响应,接口比较清晰简单,是一种架构规则。话不多说,下面我就说下安装方法和简单使用方法,这样更容易理解,之后我会单独讲解怎么让你的网站利用elasticSearch实现搜索功能
Elasticsearch(简称ES)是一个基于Apache Lucene(TM)的开源搜索引擎,无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
Elasticsearch简介
Elasticsearch是什么
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎,无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
但是,Lucene只是一个库。想要发挥其强大的作用,你需使用Java并要将其集成到你的应用中。Lucene非常复杂,你需要深入的了解检索相关知识来理解它是如何工作的。
Elasticsearch也是使用Java编写并使用Lucene来建立索引并实现搜索功能,但是它的目的是通过简单连贯的RESTful API让全文搜索变得简单并隐藏Lucene的复杂性。
不过,Elasticsearch不仅仅是Lucene和全文搜索引擎,它还提供:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 实时分析的分布式搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
而且,所有的这些功能被集成到一台服务器,你的应用可以通过简单的RESTful API、各种语言的客户端甚至命令行与之交互。上手Elasticsearch非常简单,它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。它开箱即用(安装即可使用),只需很少的学习既可在生产环境中使用。Elasticsearch在Apache 2 license下许可使用,可以免费下载、使用和修改。
随着知识的积累,你可以根据不同的问题领域定制Elasticsearch的高级特性,这一切都是可配置的,并且配置非常灵活。
以上内容来自 [百度百科]
Elasticsearch中涉及到的重要概念
Elasticsearch有几个核心概念。从一开始理解这些概念会对整个学习过程有莫大的帮助。
(1) 接近实时(NRT)
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒)。
(2) 集群(cluster)
一个集群就是由一个或多个节点组织在一起,它们共同持有你整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。在产品环境中显式地设定这个名字是一个好习惯,但是使用默认值来进行测试/开发也是不错的。
(3) 节点(node)
一个节点是你集群中的一个服务器,作为集群的一部分,它存储你的数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
(4) 索引(index)
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。索引类似于关系型数据库中Database的概念。在一个集群中,如果你想,可以定义任意多的索引。
(5) 类型(type)
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。类型类似于关系型数据库中Table的概念。
(6)文档(document)
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(JavaScript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。
在一个index/type里面,只要你想,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。文档类似于关系型数据库中Record的概念。实际上一个文档除了用户定义的数据外,还包括_index、_type和_id字段。
(7) 分片和复制(shards & replicas)
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。
为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片之所以重要,主要有两方面的原因:
- 允许你水平分割/扩展你的内容容量
- 允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了。这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。复制之所以重要,主要有两方面的原因:
- 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。
- 扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行
总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制数量,但是不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。一个索引的多个分片可以存放在集群中的一台主机上,也可以存放在多台主机上,这取决于你的集群机器数量。主分片和复制分片的具体位置是由ES内在的策略所决定的。
以上部分内容转自Elasticsearch基础教程,并对其进行了补充。
elasticSearch安装
从github下载1.7版tag并编译(选择1.7版是因为当前我们的网站的symfony2版本还不支持2.x版本,但请放心的用,1.7版是经过无数人验证过的最稳定版本)
wget https://codeload.github.com/elastic/elasticsearch/tar.gz/v1.7.5
解压后进入目录执行
mvn package -DskipTests
这会花费你很长一段时间,你可以去喝喝茶了
编译完成后会在target/releases中生成编译好的压缩包(类似于elasticsearch-1.7.5.zip这样的文件),把这个压缩包解压放到任意目录就安装好了
安装ik插件
ik是一个中文切词插件,elasticSearch自带的中文切词很不专业,ik对中文切词支持的比较好。
在https://github.com/medcl/elasticsearch-analysis-ik上找到我们elasticSearch对应的版本,1.7.5对应的ik版本是1.4.1,所以下载https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v1.4.1
解压出的目录是:
elasticsearch-analysis-ik-1.4.1
进入目录后执行
mvn clean package
编译完后依然是在target/releases生成了类似于elasticsearch-analysis-ik-*.zip的压缩包,把里面的内容解压到elasticsearch安装目录的plugins/ik下
再把elasticsearch-analysis-ik-1.4.1/config/ik目录整体拷贝到elasticsearch安装目录的config下
修改elasticsearch安装目录下的config/elasticsearch.yml,添加:
-
index:
-
analysis:
-
analyzer:
-
ik:
-
alias:
[ik_analyzer]
-
type: org.elasticsearch.index.analysis.IkAnalyzerProvider
-
ik_max_word:
-
type: ik
-
use_smart: false
-
ik_smart:
-
type: ik
-
use_smart: true
这样ik就安装好了
启动并试用
直接进入elasticsearch安装目录,执行
./bin/elasticsearch -d
后台启动完成
elasticSearch是通过HTTP协议收发数据的,所以我们用curl命令来给它发命令,elasticSearch默认监听9200端口
写入一篇文章:
-
curl -XPUT 'http://localhost:
9200/myappname/myblog/
1?pretty' -d '
-
{
-
"
title":
"我的标题",
-
"
content":
"我的内容"
-
}'
会收到返回信息:
-
{
-
"
_index" :
"myappname",
-
"
_type" :
"myblog",
-
"
_id" :
"1",
-
"
_version" :
1,
-
"
created" :
true
-
}
这说明我们成功把一篇文章发给了elasticSearch,它底层会利用lucene自动帮我们建好搜索用的索引
再写一篇文章:
-
curl -XPUT 'http://localhost:
9200/myappname/myblog/
2?pretty' -d '
-
{
-
"
title":
"这是第二篇标题",
-
"
content":
"这是第二篇内容"
-
}'
会收到返回信息:
-
{
-
"
_index" :
"myappname",
-
"
_type" :
"myblog",
-
"
_id" :
"2",
-
"
_version" :
1,
-
"
created" :
true
-
}
请尊重原创,转载请注明来源网站www.shareditor.com以及原始链接地址
这时我们找到elasticsearch安装目录的data目录下会生成这样的目录和文件:
-
ls data
/nodes/0/indices/myappname/
-
0
1
2
3
4 _state
不同环境会稍有不同,但是都会生成myappname目录就对了
查看所有文章:
-
curl -XGET 'http://localhost:
9200/myappname/myblog/_search?pretty=
true' -d '
-
{
-
"
query" :
{
-
"match_all" : {}
-
}
-
}'
这时会把我们刚才添加的两篇文章都列出来
搜索关键词“我的”:
-
curl -XGET 'http://localhost:
9200/myappname/myblog/_search?pretty=
true' -d '
-
{
-
"
query":
{
-
"query_string":{"query":"我的"}
-
}
-
}'
会返回:
-
{
-
"
took" :
2,
-
"
timed_out" :
false,
-
"
_shards" :
{
-
"total" : 5,
-
"successful" : 5,
-
"failed" : 0
-
},
-
"
hits" :
{
-
"total" : 1,
-
"max_score" : 0.191783,
-
"hits" : [ {
-
"_index" : "myappname",
-
"_type" : "myblog",
-
"_id" : "1",
-
"_score" : 0.191783,
-
"_source":
-
{
-
"title": "我的标题",
-
"content": "我的内容"
-
}
-
} ]
-
}
-
}
搜索关键词“第二篇”:
-
curl -XGET 'http://localhost:
9200/myappname/myblog/_search?pretty=
true' -d '
-
{
-
"
query":
{
-
"query_string":{"query":"第二篇"}
-
}
-
}'
会返回:
-
{
-
"
took" :
2,
-
"
timed_out" :
false,
-
"
_shards" :
{
-
"total" : 5,
-
"successful" : 5,
-
"failed" : 0
-
},
-
"
hits" :
{
-
"total" : 1,
-
"max_score" : 0.1879082,
-
"hits" : [ {
-
"_index" : "myappname",
-
"_type" : "myblog",
-
"_id" : "2",
-
"_score" : 0.1879082,
-
"_source":
-
{
-
"title": "这是第二篇标题",
-
"content": "这是第二篇内容"
-
}
-
} ]
-
}
-
}
如果想检查ik的切词效果,可以执行:
-
curl 'http://localhost:
9200/myappname/_analyze?analyzer=ik_max_word&pretty=
true' -d'
-
{
-
"
text":
"中华人民共和国国歌"
-
}'
通过返回结果可以看出,ik_max_word切词把中华人民共和国国歌切成了“中华人民共和国”、“中华人民”、“中华”、“华人”、“人民共和国”、“人民”、“共和国”、“共和”、“国”、“国歌”
也就是说我们搜索这些词中的任意一个都能把这句话搜到,如果不安装ik插件的话,那只会切成:“中”、“华”、“人”、“民”、“共”、“和”、“国”、“国”、“歌”,不够智能,搜索也不好进行了
讲解一下
上面几条命令都是json形式,elasticSearch就是这么人性化,没治了。
这里面的myappname是你自己可以改成自己应用的名字,这在elasticSearch数据存储中是完全隔离的,而myblog是我们在同一个app中想要维护的不同的数据,就是你的不同数据,比如文章、用户、评论,他们最好都分开,这样搜索的时候也不会混
pretty参数就是让返回的json有换行和缩进,容易阅读,调试时可以加上,开发到程序里就可以去掉了
analyzer就是切词器,我们指定的ik_max_word在前面配置文件里遇到过,表示最大程度切词,各种切,360度切
返回结果里的hits就是“命中”,total是命中了几条,took是花了几毫秒,_score就是相关性程度,可以用来做排序的依据
elasticSearch有什么用
上面都是json的接口,那么我们怎么用呢?其实你想怎么用就怎么用,煎着吃、炒着吃、炖着吃都行。比如我们的博客网站,当你创建一篇博客的时候可以发送“添加”的json命令,然后你开发一个搜索页面,当你输入关键词点搜索的时候,可以发送查询的命令,这样返回的结果就是你的搜索结果,只不过需要你自己润色一下,让展现更美观。感觉复杂吗?下一节告诉你怎么用symfony2的扩展来实现博客网站的搜索功能
————————————————————————————————————————————————————
linux下elasticsearch 安装、配置及示例
简介
开始学es,我习惯边学边记,总结出现的问题和解决方法。本文是在两台Linux虚拟机下,安装了三个节点。本次搭建es同时实践了两种模式——单机模式和分布式模式。条件允许的话,可以在多台机器上配置es节点,如果你机器性能有限,那么可以在一台虚拟机上完成多节点的配置。
如图,是本次3个节点的分布。
| 虚拟机主机名 | IP | es节点 |
|---|---|---|
| master | 192.168.137.100 | node1、node3 |
| slave | 192.168.137.101 | node2 |
一、下载及配置
1.几个基本名词
index: es里的index相当于一个数据库。
type: 相当于数据库里的一个表。
id: 唯一,相当于主键。
node:节点是es实例,一台机器可以运行多个实例,但是同一台机器上的实例在配置文件中要确保http和tcp端口不同(下面有讲)。
cluster:代表一个集群,集群中有多个节点,其中有一个会被选为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。
shards:代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上,构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
replicas:代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当个某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
2.下载
| 名称 | 版本 | 下载地址 |
|---|---|---|
| elasticsearch | 1.7.3 | elasticsearch-1.7.3.tar.gz |
下载后,放到你的目录下并解压. 因为我们要配置包含三个节点的集群,可以先将其重命名为elasticsearch-node1。比如我的是 /home/zkpk/elasticsearch-node1。
3.修改配置文件
(1) 初步修改
打开/home/zkpk/elasticsearch-node1/config目录下的elasticsearch.yml 文件 ,修改以下属性值并取消该行的注释:
-
cluster
.name:
elasticsearch
-
#这是集群名字,我们 起名为 elasticsearch。es启动后会将具有相同集群名字的节点放到一个集群下。
-
-
node
.name:
"es-node1"
-
#节点名字。
-
-
covery
.zen
.minimum_master_nodes:
2
-
#指定集群中的节点中有几个有master资格的节点。对于大集群可以写3个以上。
-
-
discovery
.zen
.ping
.timeout:
40
s
-
-
#默认是3s,这是设置集群中自动发现其它节点时ping连接超时时间,为避免因为网络差而导致启动报错,我设成了40s。
-
-
discovery
.zen
.ping
.multicast
.enabled:
false
-
#设置是否打开多播发现节点,默认是true。
-
-
network
.bind_host:
192.168
.137
.100
-
#设置绑定的ip地址,这是我的master虚拟机的IP。
-
-
network
.publish_host:
192.168
.137
.100
-
#设置其它节点和该节点交互的ip地址。
-
-
network
.host:
192.168
.137
.100
-
#同时设置bind_host和publish_host上面两个参数。
-
-
discovery
.zen
.ping
.unicast
.hosts:
[
"192.168.137.100"
,
"192.168.137.101"
,
"192.168.137.100:9301"
]
-
#discovery.zen.ping.unicast.hosts:["节点1的 ip","节点2 的ip","节点3的ip"]
-
指明集群中其它可能为
master的节点
ip,以防
es启动后发现不了集群中的其他节点。第一对引号里是
node1,默认端口是
9300。第二个是
node2 ,在另外一台机器上。第三个引号里是
node3,因为它和
node1在一台机器上,所以指定了
9301端口。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
(2) 进一步修改
拷贝 elasticsearch-node1 整个文件夹,两份,一份elasticsearch-node2,一份elasticsearch-node3.
将elasticsearch-node2 文件夹copy到另外一台IP为192.168.137.101的机器上。而在 192.168.137.100 机器上有 node1和node3.
对于node3: node3和node1在一台机器上,node1的配置文件里端口默认分别是9300和9200,所以要改一下node3配置文件里的端口,elasticsearch.yml 文件修改如下:
-
node.name:
"es-node3"
-
transport.tcp.port:
9301
-
http.port:
9201
- 1
- 2
- 3
- 1
- 2
- 3
对于node2: 对 elasticsearch.yml 修改如下
-
node.name:
"es-node2"
-
network.bind_host:
192.168.137.101
-
network.publish_host:
192.168.137.101
-
network.host:
192.168.137.101
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
注意:
1.对于单机多节点的es集群,一定要注意修改 transport.tcp.port 和http.port 的默认值保证节点间不冲突。
2. 出现找不到同一集群中的其他节点的情况,检查下 discovery.zen.ping.unicast.hosts 是否已设置。
二、运行 & 关闭 elasticsearch
1.运行elasticsearch :
编辑 /home/zkpk/elasticsearch-1.7.3/bin/elasticsearch.in.sh, 设置 ES_MIN_MEM和ES_MAX_MEM,确保二者数值一致,或者可以在启动es时指定,
-
[zkpk
@master ~]
$ cd ~
/elasticsearch-node1/bin
-
[zkpk
@master bin]
$ ./elasticsearch -
Xms512m -
Xmx512m
- 1
- 2
- 1
- 2
若想让es后台运行,则
[zkpk@master bin]$ ./elasticsearch -d -Xms512m -Xmx512m
- 1
- 1
2.关闭elasticsearch:
前台运行:可以通过”CTRL+C”组合键来停止运行
后台运行,可以通过”kill -9 进程号”停止.也可以通过REST API接口:
curl -XPOST http://主机IP:9200/_cluster/nodes/_shutdown
- 1
- 1
来关闭整个集群,通过:
curl -XPOST http://主机IP:9200/_cluster/nodes/节点标示符(如es-node1)/_shutdown
- 1
- 1
来关闭单个节点.
三、插件及其安装
BigDesk Plugin : 对集群中es状态进行监控。
Elasticsearch Head Plugin: 对ES进行各种操作,如查询、删除、浏览索引等。
1.安装head插件
进入到节点elasticsearch-node1/bin路径,并安装插件。
[zkpk@master bin]$ ./plugin -install mobz/elasticsearch-head
- 1
- 1
2. 安装bigdesk
[zkpk@master bin]$ ./plugin -install lukas-vlcek/bigdesk
让我们看下es页面吧~~
打开head浏览,浏览器输入http://192.168.137.100:9200/_plugin/head/ ,如图,

每个小方块就是索引分片,可以看到每个索引被分成几个分片,每个分片还有它的备份分片,然后存储在三个节点上。粗框的是主分片,细框的是备份分片。
四、添加索引
现在我们来添加一个索引记录吧~
1.可以在命令窗口通过命令来添加
curl -XPUT 'http://主机IP:9200/dept/employee/32' -d '{ "empname": "emp32"}'
- 1
- 1
见 http://www.oschina.net/translate/elasticsearch-getting-started?cmp
2.我们可以在页面上通过JSON添加
(1)点击 复合查询[+] ,我们可以在 megacorp 索引 (相当于数据库名)的 employee 类型(相当于表名)下新增一个id为2的人的信息。
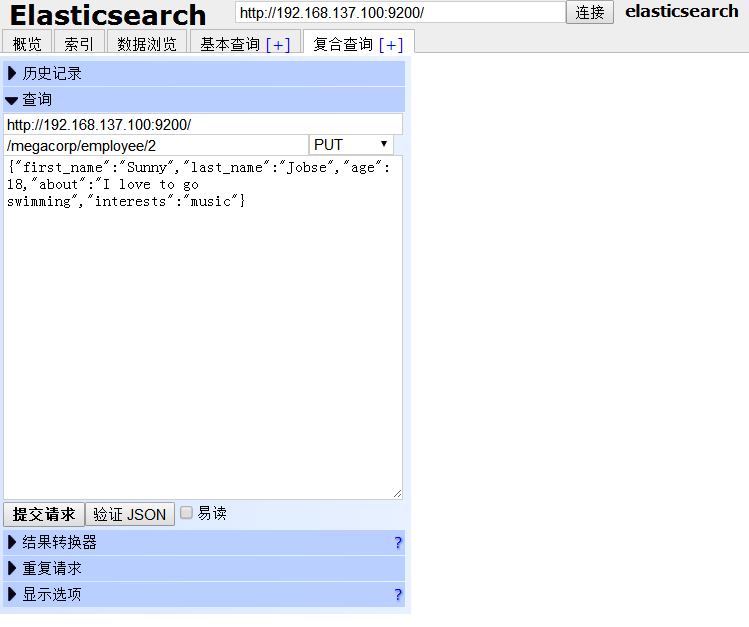
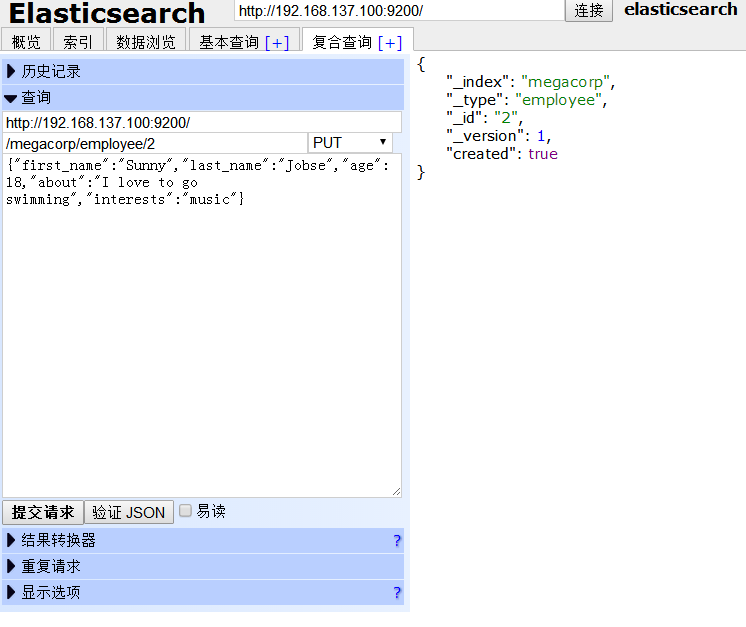
点击下方的 提交请求 按钮,页面右方有回馈信息,“created”代表是否为新建。添加成功。
点击 浏览数据 ,在左侧 索引 下选择 megacorp,如图,
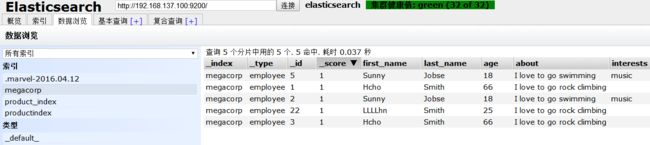
可以看到,一条id为2的记录被添加了。
(2)下面我们修改id为2 的人的年龄为15,把about 信息去掉,并且加一项兴趣。
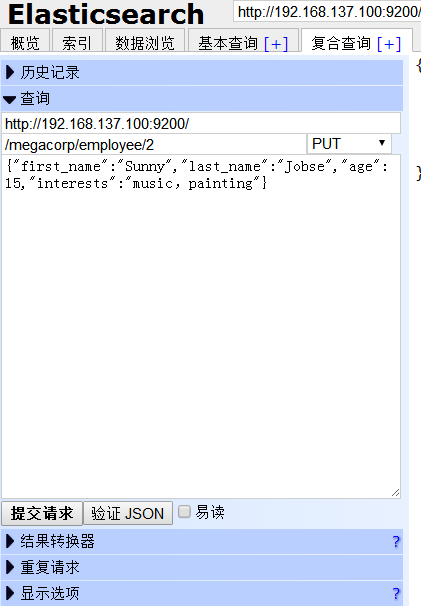
提交后,右侧有反馈信息,“created”为 false,因为我们这次不是新建而是修改。
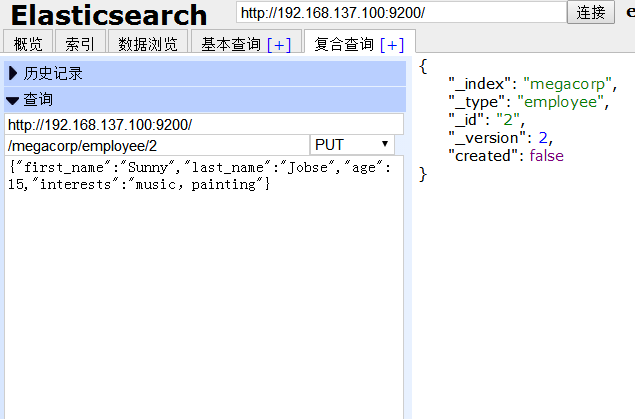
返回浏览数据,id为2 的记录,年龄、兴趣等均已发生变化。

参考:
http://www.cnblogs.com/huangfox/p/3543351.html
http://www.linuxidc.com/Linux/2015-02/114243.htm
http://my.oschina.net/u/579033/blog/394845?fromerr=Kt60ej6x
文档总结不易,希望能帮到各位,和各位一起进步,另,转载请标明出处。