1.注册中国大学MOOC
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
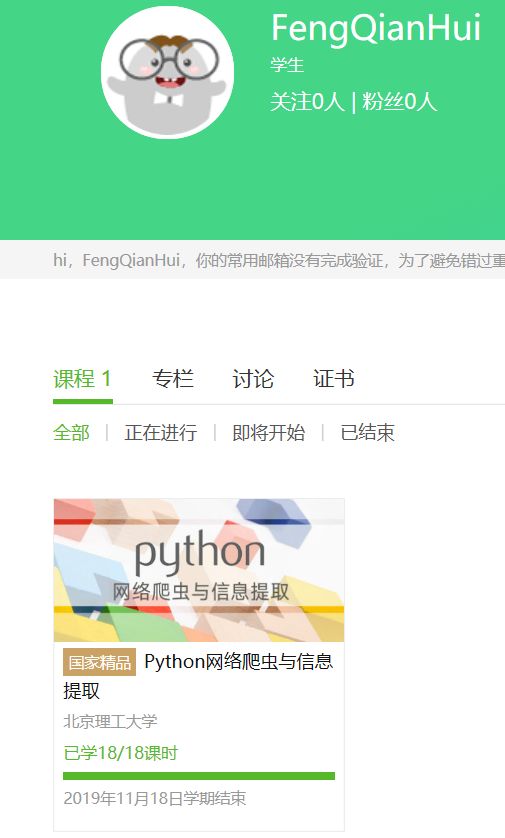
4.提供图片或网站显示的学习进度,证明学习的过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获
通过一段时间的对北京理工大学嵩天老师在MOOC上的关于《Python网络爬虫与信息提取》这门课的学习,虽然在学习过程中存在一定的困难,但是对于一些基础的学习,让我更加了解Python的强大。
在本次课程中,老师主要讲解了Requests库、Beautiful Soup库、Robots协议、Re正则表达式、Scrapy库和信息标记的知识点。在每个知识点讲解前,老师都会教授如何安装第三方库,并在内容讲解完后通过实例来加深对知识点的理解。
首先,Requests库的入门,它主要是用来获取页面的信息的,但是并不能对页面的信息进行提取和解析。Requests包含了7个方法,其中的request()方法是用来支撑其他六个方法的基础方法,而六个方法中最常用的就是get()方法,因为它就是根据提供的url链接来获取页面的信息。但是在获取信息的过程中可能会遇到Requests库异的各种情况,这种时候,我们就可以用try-except代码块来防止因出现异常而无法继续的情况,在后期自己编写代码时也应养成熟练使用该代码块的习惯。
Beautiful Soup库(bs4)主要是用来解析、遍历和维护“标签树”的功能库。通过三种遍历的方式来获取各个节点的信息。而信息的标记有利于程序的理解和运用,信息的标记主要有三种方式:XML是最早的方式,可以对标签对进行缩写和添加注释,如
Re(正则表达式)是用来提取页面的关键信息的,同上面的bs4一样都可以用来解析页面的内容。而Re最大的优势就是简洁,“一行胜千行”。在这里需要重点了解正则表达式的一些常用操作符,只有了解后才能知道一行Re表达的是什么样的一串字符串。正则表达式有两种表达方式:一种是直接通过re.方法()调用;一种是通过regex=re.compile()将re的字符串编译成regex对象,在通过对象.方法()来调用。
Robots协议是网络爬虫排除的标准,是网站告知网络爬虫哪些页面可以抓取,哪些不行。我们可以在网站根目录下的robots.txt文件来查看一个网站的协议。我们在爬虫的过程中应遵守“盗亦有道”的原则。
Scrapy库是专业爬虫的框架,包括“5+2”结构和三个数据流,其中Engine、Scheduler、Downloader已有框架,不需要自己再进行修改,我们只需对Spiders和Item Pipelines配置代码。通过对股票爬虫的实例可知,我们在用Scrapy爬虫时,大多可以采用以下步骤:1、建立工程和Spider模块;2、编写Spider 3、编写Item Pipelines。Scrapy采用的是命令行模式,更容易自动化,适合脚本控制。
以上是我通过这门课学到的一些关于网络爬虫的基础知识,学的并不是很深,但总是在不断的学习中进步。