kubeadm部署kubernetes v1.14.1高可用集群
高可用简介
kubernetes高可用部署参考:
https://kubernetes.io/docs/setup/independent/high-availability/
https://github.com/kubernetes-sigs/kubespray
https://github.com/wise2c-devops/breeze
https://github.com/cookeem/kubeadm-ha
拓扑选择
配置高可用(HA)Kubernetes集群,有以下两种可选的etcd拓扑:
- 集群master节点与etcd节点共存,etcd也运行在控制平面节点上
- 使用外部etcd节点,etcd节点与master在不同节点上运行
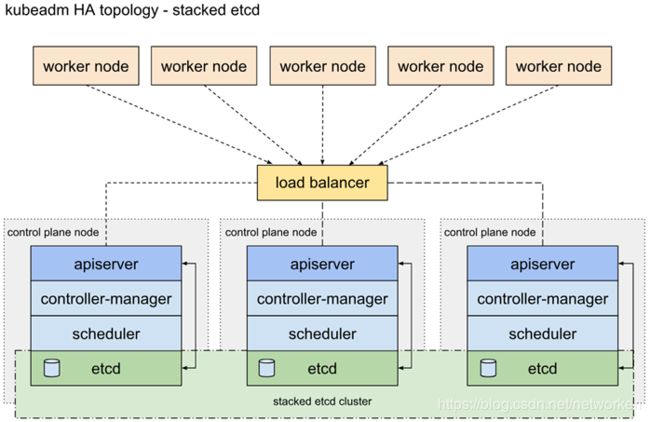
堆叠的etcd拓扑
堆叠HA集群是这样的拓扑,其中etcd提供的分布式数据存储集群与由kubeamd管理的运行master组件的集群节点堆叠部署。
每个master节点运行kube-apiserver,kube-scheduler和kube-controller-manager的一个实例。kube-apiserver使用负载平衡器暴露给工作节点。
每个master节点创建一个本地etcd成员,该etcd成员仅与本节点kube-apiserver通信。这同样适用于本地kube-controller-manager 和kube-scheduler实例。
该拓扑将master和etcd成员耦合在相同节点上。比设置具有外部etcd节点的集群更简单,并且更易于管理复制。
但是,堆叠集群存在耦合失败的风险。如果一个节点发生故障,则etcd成员和master实例都将丢失,并且冗余会受到影响。您可以通过添加更多master节点来降低此风险。
因此,您应该为HA群集运行至少三个堆叠的master节点。
这是kubeadm中的默认拓扑。使用kubeadm init和kubeadm join --experimental-control-plane命令时,在master节点上自动创建本地etcd成员。
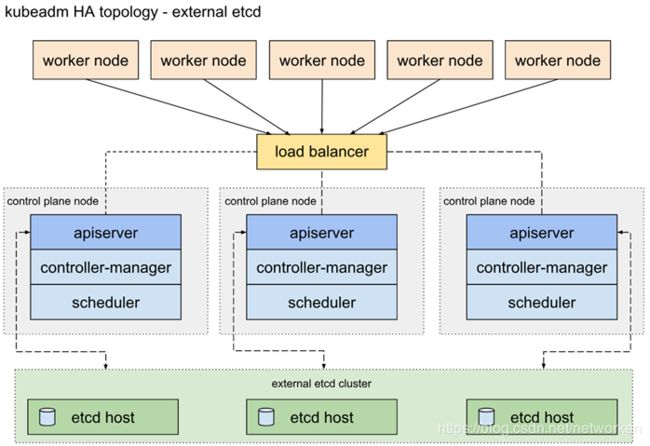
外部etcd拓扑
具有外部etcd的HA集群是这样的拓扑,其中由etcd提供的分布式数据存储集群部署在运行master组件的节点形成的集群外部。
像堆叠ETCD拓扑结构,在外部ETCD拓扑中的每个master节点运行一个kube-apiserver,kube-scheduler和kube-controller-manager实例。并且kube-apiserver使用负载平衡器暴露给工作节点。但是,etcd成员在不同的主机上运行,每个etcd主机与kube-apiserver每个master节点进行通信。
此拓扑将master节点和etcd成员分离。因此,它提供了HA设置,其中丢失master实例或etcd成员具有较小的影响并且不像堆叠的HA拓扑那样影响集群冗余。
但是,此拓扑需要两倍于堆叠HA拓扑的主机数。具有此拓扑的HA群集至少需要三个用于master节点的主机和三个用于etcd节点的主机。
部署要求
使用kubeadm部署高可用性Kubernetes集群的两种不同方法:
- 使用堆叠master节点。这种方法需要较少的基础设施,etcd成员和master节点位于同一位置。
- 使用外部etcd集群。这种方法需要更多的基础设施, master节点和etcd成员是分开的。
在继续之前,您应该仔细考虑哪种方法最能满足您的应用程序和环境的需求。
部署要求
- 至少3个master节点
- 至少3个worker节点
- 所有节点网络全部互通(公共或私有网络)
- 所有机器都有sudo权限
- 从一个设备到系统中所有节点的SSH访问
- 所有节点安装kubeadm和kubelet,kubectl是可选的。
- 针对外部etcd集群,你需要为etcd成员额外提供3个节点
负载均衡
部署集群前首选需要为kube-apiserver创建负载均衡器。
注意:负载平衡器有许多中配置方式。可以根据你的集群要求选择不同的配置方案。在云环境中,您应将master节点作为负载平衡器TCP转发的后端。此负载平衡器将流量分配到其目标列表中的所有健康master节点。apiserver的运行状况检查是对kube-apiserver侦听的端口的TCP检查(默认值:6443)。
负载均衡器必须能够与apiserver端口上的所有master节点通信。它还必须允许其侦听端口上的传入流量。另外确保负载均衡器的地址始终与kubeadm的ControlPlaneEndpoint地址匹配。
haproxy/nignx+keepalived是其中可选的负载均衡方案,针对公有云环境可以直接使用运营商提供的负载均衡产品。
部署时首先将第一个master节点添加到负载均衡器并使用以下命令测试连接:
# nc -v LOAD_BALANCER_IP PORT
由于apiserver尚未运行,因此预计会出现连接拒绝错误。但是,超时意味着负载均衡器无法与master节点通信。如果发生超时,请重新配置负载平衡器以与master节点通信。将剩余的master节点添加到负载平衡器目标组。
第2章 部署集群
本次使用kubeadm部署kubernetes v1.14.1高可用集群,包含3个master节点和1个node节点,部署步骤以官方文档为基础,负载均衡部分采用haproxy+keepalived容器方式实现。所有组件版本以kubernetes v1.14.1为准,其他组件以当前最新版本为准。
基本配置
节点信息:
| 主机名 | IP地址 | 角色 | OS | CPU/MEM | 磁盘 | 网卡 |
|---|---|---|---|---|---|---|
| k8s-master01 | 192.168.92.10 | master | CentOS7.6 | 2C2G | 60G | x1 |
| k8s-master02 | 192.168.92.11 | master | CentOS7.6 | 2C2G | 60G | x1 |
| k8s-master03 | 192.168.92.12 | master | CentOS7.6 | 2C2G | 60G | x1 |
| k8s-node01 | 192.168.92.13 | node | CentOS7.6 | 2C2G | 60G | x1 |
| K8S VIP | 192.168.92.30 | – | – | – | - | - |
以下操作在所有节点执行。
#配置主机名
hostnamectl set-hostname k8s-master01
hostnamectl set-hostname k8s-master02
hostnamectl set-hostname k8s-master03
hostnamectl set-hostname k8s-node01
#修改/etc/hosts
cat >> /etc/hosts << EOF
192.168.92.10 k8s-master01
192.168.92.11 k8s-master02
192.168.92.12 k8s-master03
192.168.92.13 k8s-node01
EOF
# 开启firewalld防火墙并允许所有流量
systemctl start firewalld && systemctl enable firewalld
firewall-cmd --set-default-zone=trusted
firewall-cmd --complete-reload
# 关闭selinux
sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config && setenforce 0
#关闭swap
swapoff -a
yes | cp /etc/fstab /etc/fstab_bak
cat /etc/fstab_bak | grep -v swap > /etc/fstab
配置时间同步
使用chrony同步时间,centos7默认已安装,这里修改时钟源,所有节点与网络时钟源同步:
# 安装chrony:
yum install -y chrony
cp /etc/chrony.conf{,.bak}
# 注释默认ntp服务器
sed -i 's/^server/#&/' /etc/chrony.conf
# 指定上游公共 ntp 服务器
cat >> /etc/chrony.conf << EOF
server 0.asia.pool.ntp.org iburst
server 1.asia.pool.ntp.org iburst
server 2.asia.pool.ntp.org iburst
server 3.asia.pool.ntp.org iburst
EOF
# 设置时区
timedatectl set-timezone Asia/Shanghai
# 重启chronyd服务并设为开机启动:
systemctl enable chronyd && systemctl restart chronyd
#验证,查看当前时间以及存在带*的行
timedatectl && chronyc sources
加载IPVS模块
在所有的Kubernetes节点执行以下脚本(若内核大于4.19替换nf_conntrack_ipv4为nf_conntrack):
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
#执行脚本
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
#安装相关管理工具
yum install ipset ipvsadm -y
配置内核参数
cat > /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_nonlocal_bind = 1
net.ipv4.ip_forward = 1
vm.swappiness=0
EOF
sysctl --system
安装docker
CRI安装参考:https://kubernetes.io/docs/setup/cri/
要在Pod中运行容器,Kubernetes使用容器运行时。以下是可选的容器运行时。
- Docker
- CRI-O
- Containerd
- Other CRI runtimes: frakti
Cgroup驱动程序简介
当systemd被选为Linux发行版的init系统时,init进程会生成并使用根控制组(cgroup)并充当cgroup管理器。Systemd与cgroup紧密集成,并将为每个进程分配cgroup。可以配置容器运行时和要使用的kubelet cgroupfs。cgroupfs与systemd一起使用意味着将有两个不同的cgroup管理器。
Control groups用于约束分配给进程的资源。单个cgroup管理器将简化正在分配的资源的视图,并且默认情况下将具有更可靠的可用和使用资源视图。
当我们有两个managers时,我们最终会得到两个这些资源的视图。我们已经看到了现场的情况,其中配置cgroupfs用于kubelet和Docker systemd 的节点以及在节点上运行的其余进程在资源压力下变得不稳定。
更改设置,使容器运行时和kubelet systemd用作cgroup驱动程序,从而使系统稳定。请注意native.cgroupdriver=systemd下面Docker设置中的选项。
安装并配置docker
以下操作在所有节点执行。
# 安装依赖软件包
yum install -y yum-utils device-mapper-persistent-data lvm2
# 添加Docker repository,这里改为国内阿里云yum源
yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装docker-ce
yum update -y && yum install -y docker-ce
## 创建 /etc/docker 目录
mkdir /etc/docker
# 配置 daemon.
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
],
"registry-mirrors": ["https://uyah70su.mirror.aliyuncs.com"]
}
EOF
#注意,由于国内拉取镜像较慢,配置文件最后追加了阿里云镜像加速配置。
mkdir -p /etc/systemd/system/docker.service.d
# 重启docker服务
systemctl daemon-reload && systemctl restart docker && systemctl enable docker
安装负载均衡
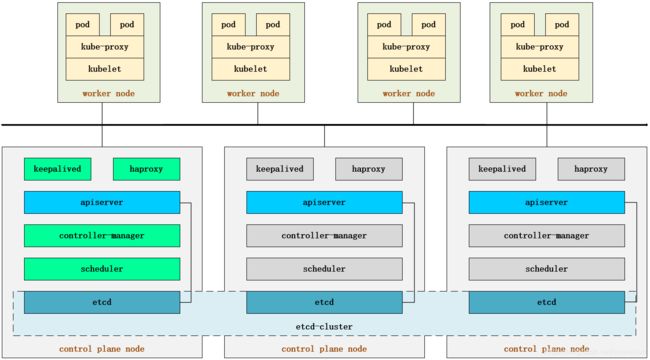
kubernetes master 节点运行如下组件:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
kube-scheduler 和 kube-controller-manager 可以以集群模式运行,通过 leader 选举产生一个工作进程,其它进程处于阻塞模式。
kube-apiserver可以运行多个实例,但对其它组件需要提供统一的访问地址,该地址需要高可用。本次部署使用 keepalived+haproxy 实现 kube-apiserver VIP 高可用和负载均衡。
haproxy+keepalived配置vip,实现了api唯一的访问地址和负载均衡。keepalived 提供 kube-apiserver 对外服务的 VIP。haproxy 监听 VIP,后端连接所有 kube-apiserver 实例,提供健康检查和负载均衡功能。
运行 keepalived 和 haproxy 的节点称为 LB 节点。由于 keepalived 是一主多备运行模式,故至少两个 LB 节点。
本次部署复用 master 节点的三台机器,在所有3个master节点部署haproxy和keepalived组件,以达到更高的可用性,haproxy 监听的端口(6444) 需要与 kube-apiserver的端口 6443 不同,避免冲突。
keepalived 在运行过程中周期检查本机的 haproxy 进程状态,如果检测到 haproxy 进程异常,则触发重新选主的过程,VIP 将飘移到新选出来的主节点,从而实现 VIP 的高可用。
所有组件(如 kubeclt、apiserver、controller-manager、scheduler 等)都通过 VIP +haproxy 监听的6444端口访问 kube-apiserver 服务。
负载均衡架构图如下:
运行HA容器
使用的容器镜像为睿云智合开源项目breeze相关镜像,具体使用方法请访问:
https://github.com/wise2c-devops
其他选择:haproxy镜像也可以使用dockerhub官方镜像,但keepalived未提供官方镜像,可自行构建或使用dockerhub他人已构建好的镜像,本次部署全部使用breeze提供的镜像。
在3个master节点以容器方式部署haproxy,容器暴露6444端口,负载均衡到后端3个apiserver的6443端口,3个节点haproxy配置文件相同。
以下操作在master01节点执行。
创建haproxy启动脚本
编辑start-haproxy.sh文件,修改Kubernetes Master节点IP地址为实际Kubernetes集群所使用的值(Master Port默认为6443不用修改):
mkdir -p /data/lb
cat > /data/lb/start-haproxy.sh << "EOF"
#!/bin/bash
MasterIP1=192.168.92.10
MasterIP2=192.168.92.11
MasterIP3=192.168.92.12
MasterPort=6443
docker run -d --restart=always --name HAProxy-K8S -p 6444:6444 \
-e MasterIP1=$MasterIP1 \
-e MasterIP2=$MasterIP2 \
-e MasterIP3=$MasterIP3 \
-e MasterPort=$MasterPort \
wise2c/haproxy-k8s
EOF
创建keepalived启动脚本
编辑start-keepalived.sh文件,修改虚拟IP地址VIRTUAL_IP、虚拟网卡设备名INTERFACE、虚拟网卡的子网掩码NETMASK_BIT、路由标识符RID、虚拟路由标识符VRID的值为实际Kubernetes集群所使用的值。(CHECK_PORT的值6444一般不用修改,它是HAProxy的暴露端口,内部指向Kubernetes Master Server的6443端口)
cat > /data/lb/start-keepalived.sh << "EOF"
#!/bin/bash
VIRTUAL_IP=192.168.92.30
INTERFACE=ens33
NETMASK_BIT=24
CHECK_PORT=6444
RID=10
VRID=160
MCAST_GROUP=224.0.0.18
docker run -itd --restart=always --name=Keepalived-K8S \
--net=host --cap-add=NET_ADMIN \
-e VIRTUAL_IP=$VIRTUAL_IP \
-e INTERFACE=$INTERFACE \
-e CHECK_PORT=$CHECK_PORT \
-e RID=$RID \
-e VRID=$VRID \
-e NETMASK_BIT=$NETMASK_BIT \
-e MCAST_GROUP=$MCAST_GROUP \
wise2c/keepalived-k8s
EOF
复制启动脚本到其他2个master节点
[root@k8s-master02 ~]# mkdir -p /data/lb
[root@k8s-master03 ~]# mkdir -p /data/lb
[root@k8s-master01 ~]# scp start-haproxy.sh start-keepalived.sh 192.168.92.11:/data/lb/
[root@k8s-master01 ~]# scp start-haproxy.sh start-keepalived.sh 192.168.92.12:/data/lb/
分别在3个master节点运行脚本启动haproxy和keepalived容器:
sh /data/lb/start-haproxy.sh && sh /data/lb/start-keepalived.sh
验证HA状态
查看容器运行状态
[root@k8s-master01 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c1d1901a7201 wise2c/haproxy-k8s "/docker-entrypoint.…" 5 days ago Up 3 hours 0.0.0.0:6444->6444/tcp HAProxy-K8S
2f02a9fde0be wise2c/keepalived-k8s "/usr/bin/keepalived…" 5 days ago Up 3 hours Keepalived-K8S
查看网卡绑定的vip 为192.168.92.30
[root@k8s-master01 ~]# ip a | grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.92.10/24 brd 192.168.92.255 scope global noprefixroute ens33
inet 192.168.92.30/24 scope global secondary ens33
查看监听端口为6444
[root@k8s-master01 ~]# netstat -tnlp | grep 6444
tcp6 0 0 :::6444 :::* LISTEN 11695/docker-proxy
keepalived配置文件中配置了vrrp_script脚本,使用nc命令对haproxy监听的6444端口进行检测,如果检测失败即认定本机haproxy进程异常,将vip漂移到其他节点。
所以无论本机keepalived容器异常或haproxy容器异常都会导致vip漂移到其他节点,可以停掉vip所在节点任意容器进行测试。
[root@k8s-master01 ~]# docker stop HAProxy-K8S
HAProxy-K8S
#可以看到vip漂移到k8s-master02节点
[root@k8s-master02 ~]# ip a | grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.92.11/24 brd 192.168.92.255 scope global noprefixroute ens33
inet 192.168.92.30/24 scope global secondary ens33
也可以在本地执行该nc命令查看结果
[root@k8s-master02 ~]# yum install -y nc
[root@k8s-master02 ~]# nc -v -w 2 -z 127.0.0.1 6444 2>&1 | grep 'Connected to' | grep 6444
Ncat: Connected to 127.0.0.1:6444.
关于haproxy和keepalived配置文件可以在github源文件中参考Dockerfile,或使用docker exec -it xxx sh命令进入容器查看,容器中的具体路径:
- /etc/keepalived/keepalived.conf
- /usr/local/etc/haproxy/haproxy.cfg
负载均衡部分配置完成后即可开始部署kubernetes集群。
安装kubeadm
以下操作在所有节点执行。
#由于官方源国内无法访问,这里使用阿里云yum源进行替换:
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
#安装kubeadm、kubelet、kubectl,注意这里默认安装当前最新版本v1.14.1:
yum install -y kubeadm kubelet kubectl
systemctl enable kubelet && systemctl start kubelet
初始化master节点
初始化参考:
https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-init/
https://godoc.org/k8s.io/kubernetes/cmd/kubeadm/app/apis/kubeadm/v1beta1
创建初始化配置文件
可以使用如下命令生成初始化配置文件
kubeadm config print init-defaults > kubeadm-config.yaml
根据实际部署环境修改信息:
[root@k8s-master01 kubernetes]# vim kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta1
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.92.10
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: k8s-master01
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta1
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: "192.168.92.30:6444"
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.14.1
networking:
dnsDomain: cluster.local
podSubnet: "10.244.0.0/16"
serviceSubnet: 10.96.0.0/12
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
featureGates:
SupportIPVSProxyMode: true
mode: ipvs
配置说明:
- controlPlaneEndpoint:为vip地址和haproxy监听端口6444
- imageRepository:由于国内无法访问google镜像仓库k8s.gcr.io,这里指定为阿里云镜像仓库registry.aliyuncs.com/google_containers
- podSubnet:指定的IP地址段与后续部署的网络插件相匹配,这里需要部署flannel插件,所以配置为10.244.0.0/16
- mode: ipvs:最后追加的配置为开启ipvs模式。
在集群搭建完成后可以使用如下命令查看生效的配置文件:
kubectl -n kube-system get cm kubeadm-config -oyaml
初始化Master01节点
这里追加tee命令将初始化日志输出到kubeadm-init.log中以备用(可选)。
kubeadm init --config=kubeadm-config.yaml --experimental-upload-certs | tee kubeadm-init.log
该命令指定了初始化时需要使用的配置文件,其中添加–experimental-upload-certs参数可以在后续执行加入节点时自动分发证书文件。
初始化示例
[root@k8s-master01 ~]# kubeadm init --config=kubeadm-config.yaml --experimental-upload-certs | tee kubeadm-init.log
[init] Using Kubernetes version: v1.14.1
[preflight] Running pre-flight checks
[WARNING Firewalld]: firewalld is active, please ensure ports [6443 10250] are open or your cluster may not function correctly
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Activating the kubelet service
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [k8s-master01 localhost] and IPs [192.168.92.10 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [k8s-master01 localhost] and IPs [192.168.92.10 127.0.0.1 ::1]
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [k8s-master01 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.92.10 192.168.92.30]
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "admin.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 19.020444 seconds
[upload-config] storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.14" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Storing the certificates in ConfigMap "kubeadm-certs" in the "kube-system" Namespace
[upload-certs] Using certificate key:
11def25d624a2150b57715e21b0c393695bc6a70d932e472f75d24f747eb657e
[mark-control-plane] Marking the node k8s-master01 as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node k8s-master01 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: abcdef.0123456789abcdef
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] creating the "cluster-info" ConfigMap in the "kube-public" namespace
[addons] Applied essential addon: CoreDNS
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 192.168.92.30:6444 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:7b232b343577bd5fac312996b9fffb3c88f8f8bb39f46bf865ac9f9f52982b82 \
--experimental-control-plane --certificate-key 11def25d624a2150b57715e21b0c393695bc6a70d932e472f75d24f747eb657e
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --experimental-upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.92.30:6444 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:7b232b343577bd5fac312996b9fffb3c88f8f8bb39f46bf865ac9f9f52982b82
kubeadm init主要执行了以下操作:
- [init]:指定版本进行初始化操作
- [preflight] :初始化前的检查和下载所需要的Docker镜像文件
- [kubelet-start]:生成kubelet的配置文件”/var/lib/kubelet/config.yaml”,没有这个文件kubelet无法启动,所以初始化之前的kubelet实际上启动失败。
- [certificates]:生成Kubernetes使用的证书,存放在/etc/kubernetes/pki目录中。
- [kubeconfig] :生成 KubeConfig 文件,存放在/etc/kubernetes目录中,组件之间通信需要使用对应文件。
- [control-plane]:使用/etc/kubernetes/manifest目录下的YAML文件,安装 Master 组件。
- [etcd]:使用/etc/kubernetes/manifest/etcd.yaml安装Etcd服务。
- [wait-control-plane]:等待control-plan部署的Master组件启动。
- [apiclient]:检查Master组件服务状态。
- [uploadconfig]:更新配置
- [kubelet]:使用configMap配置kubelet。
- [patchnode]:更新CNI信息到Node上,通过注释的方式记录。
- [mark-control-plane]:为当前节点打标签,打了角色Master,和不可调度标签,这样默认就不会使用Master节点来运行Pod。
- [bootstrap-token]:生成token记录下来,后边使用kubeadm join往集群中添加节点时会用到
- [addons]:安装附加组件CoreDNS和kube-proxy
说明:无论是初始化失败或者集群已经完全搭建成功,你都可以直接执行kubeadm reset命令清理集群或节点,然后重新执行kubeadm init或kubeadm join相关操作即可。
配置kubectl命令
无论在master节点或node节点,要能够执行kubectl命令必须进行以下配置:
root用户执行以下命令
cat << EOF >> ~/.bashrc
export KUBECONFIG=/etc/kubernetes/admin.conf
EOF
source ~/.bashrc
普通用户执行以下命令(参考init时的输出结果)
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
等集群配置完成后,可以在所有master节点和node节点进行以上配置,以支持kubectl命令。针对node节点复制任意master节点/etc/kubernetes/admin.conf到本地。
查看当前状态
[root@k8s-master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 NotReady master 81s v1.14.1
[root@k8s-master01 ~]# kubectl -n kube-system get pod
NAME READY STATUS RESTARTS AGE
coredns-8686dcc4fd-cbrc5 0/1 Pending 0 64s
coredns-8686dcc4fd-wqpwr 0/1 Pending 0 64s
etcd-k8s-master01 1/1 Running 0 16s
kube-apiserver-k8s-master01 1/1 Running 0 13s
kube-controller-manager-k8s-master01 1/1 Running 0 25s
kube-proxy-4vwbb 1/1 Running 0 65s
kube-scheduler-k8s-master01 1/1 Running 0 4s
[root@k8s-master01 ~]# kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}
由于未安装网络插件,coredns处于pending状态,node处于notready状态。
安装网络插件
kubernetes支持多种网络方案,这里简单介绍常用的flannel和calico安装方法,选择其中一种方案进行部署即可。
以下操作在master01节点执行即可。
安装flannel网络插件:
由于kube-flannel.yml文件指定的镜像从coreos镜像仓库拉取,可能拉取失败,可以从dockerhub搜索相关镜像进行替换,另外可以看到yml文件中定义的网段地址段为10.244.0.0/16。
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
cat kube-flannel.yml | grep image
cat kube-flannel.yml | grep 10.244
sed -i 's#quay.io/coreos/flannel:v0.11.0-amd64#willdockerhub/flannel:v0.11.0-amd64#g' kube-flannel.yml
kubectl apply -f kube-flannel.yml
再次查看node和 Pod状态,全部为Running
[root@k8s-master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready master 9m8s v1.14.1
[root@k8s-master01 ~]# kubectl -n kube-system get pod
NAME READY STATUS RESTARTS AGE
coredns-8686dcc4fd-cbrc5 1/1 Running 0 8m53s
coredns-8686dcc4fd-wqpwr 1/1 Running 0 8m53s
etcd-k8s-master01 1/1 Running 0 8m5s
kube-apiserver-k8s-master01 1/1 Running 0 8m2s
kube-controller-manager-k8s-master01 1/1 Running 0 8m14s
kube-flannel-ds-amd64-vtppf 1/1 Running 0 115s
kube-proxy-4vwbb 1/1 Running 0 8m54s
kube-scheduler-k8s-master01 1/1 Running 0 7m53s
安装calico网络插件(可选):
安装参考:https://docs.projectcalico.org/v3.6/getting-started/kubernetes/
kubectl apply -f \
https://docs.projectcalico.org/v3.6/getting-started/kubernetes/installation/hosted/kubernetes-datastore/calico-networking/1.7/calico.yaml
注意该yaml文件中默认CIDR为192.168.0.0/16,需要与初始化时kube-config.yaml中的配置一致,如果不同请下载该yaml修改后运行。
加入master节点
从初始化输出或kubeadm-init.log中获取命令
kubeadm join 192.168.92.30:6444 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:c0a1021e5d63f509a0153724270985cdc22e46dc76e8e7b84d1fbb5e83566ea8 \
--experimental-control-plane --certificate-key 52f64a834454c3043fe7a0940f928611b6970205459fa19cb1193b33a288e7cc
依次将k8s-master02和k8s-master03加入到集群中,示例
[root@k8s-master02 ~]# kubeadm join 192.168.92.30:6444 --token abcdef.0123456789abcdef \
> --discovery-token-ca-cert-hash sha256:7b232b343577bd5fac312996b9fffb3c88f8f8bb39f46bf865ac9f9f52982b82 \
> --experimental-control-plane --certificate-key 11def25d624a2150b57715e21b0c393695bc6a70d932e472f75d24f747eb657e
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[preflight] Running pre-flight checks before initializing the new control plane instance
[WARNING Firewalld]: firewalld is active, please ensure ports [6443 10250] are open or your cluster may not function correctly
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[download-certs] Downloading the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [k8s-master02 localhost] and IPs [192.168.92.11 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [k8s-master02 localhost] and IPs [192.168.92.11 127.0.0.1 ::1]
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [k8s-master02 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.92.11 192.168.92.30]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Valid certificates and keys now exist in "/etc/kubernetes/pki"
[certs] Using the existing "sa" key
[kubeconfig] Generating kubeconfig files
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[check-etcd] Checking that the etcd cluster is healthy
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.14" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Activating the kubelet service
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
[etcd] Announced new etcd member joining to the existing etcd cluster
[etcd] Wrote Static Pod manifest for a local etcd member to "/etc/kubernetes/manifests/etcd.yaml"
[etcd] Waiting for the new etcd member to join the cluster. This can take up to 40s
[upload-config] storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[mark-control-plane] Marking the node k8s-master02 as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node k8s-master02 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
This node has joined the cluster and a new control plane instance was created:
* Certificate signing request was sent to apiserver and approval was received.
* The Kubelet was informed of the new secure connection details.
* Control plane (master) label and taint were applied to the new node.
* The Kubernetes control plane instances scaled up.
* A new etcd member was added to the local/stacked etcd cluster.
To start administering your cluster from this node, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Run 'kubectl get nodes' to see this node join the cluster.
加入node节点
从kubeadm-init.log中获取命令
kubeadm join 192.168.92.30:6444 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:c0a1021e5d63f509a0153724270985cdc22e46dc76e8e7b84d1fbb5e83566ea8
示例
[root@k8s-node01 ~]# kubeadm join 192.168.92.30:6444 --token abcdef.0123456789abcdef \
> --discovery-token-ca-cert-hash sha256:7b232b343577bd5fac312996b9fffb3c88f8f8bb39f46bf865ac9f9f52982b82
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.14" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Activating the kubelet service
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
验证集群状态
查看nodes运行情况
[root@k8s-master01 ~]# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-master01 Ready master 10h v1.14.1 192.168.92.10 <none> CentOS Linux 7 (Core) 3.10.0-957.10.1.el7.x86_64 docker://18.9.5
k8s-master02 Ready master 10h v1.14.1 192.168.92.11 <none> CentOS Linux 7 (Core) 3.10.0-957.10.1.el7.x86_64 docker://18.9.5
k8s-master03 Ready master 10h v1.14.1 192.168.92.12 <none> CentOS Linux 7 (Core) 3.10.0-957.10.1.el7.x86_64 docker://18.9.5
k8s-node01 Ready <none> 10h v1.14.1 192.168.92.13 <none> CentOS Linux 7 (Core) 3.10.0-957.10.1.el7.x86_64 docker://18.9.5
查看pod运行情况
[root@k8s-master03 ~]# kubectl -n kube-system get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-8686dcc4fd-6ttgv 1/1 Running 1 22m 10.244.2.3 k8s-master03 <none> <none>
coredns-8686dcc4fd-dzvsx 1/1 Running 0 22m 10.244.3.3 k8s-node01 <none> <none>
etcd-k8s-master01 1/1 Running 1 6m23s 192.168.92.10 k8s-master01 <none> <none>
etcd-k8s-master02 1/1 Running 0 37m 192.168.92.11 k8s-master02 <none> <none>
etcd-k8s-master03 1/1 Running 1 36m 192.168.92.12 k8s-master03 <none> <none>
kube-apiserver-k8s-master01 1/1 Running 1 48m 192.168.92.10 k8s-master01 <none> <none>
kube-apiserver-k8s-master02 1/1 Running 0 37m 192.168.92.11 k8s-master02 <none> <none>
kube-apiserver-k8s-master03 1/1 Running 2 36m 192.168.92.12 k8s-master03 <none> <none>
kube-controller-manager-k8s-master01 1/1 Running 2 48m 192.168.92.10 k8s-master01 <none> <none>
kube-controller-manager-k8s-master02 1/1 Running 1 37m 192.168.92.11 k8s-master02 <none> <none>
kube-controller-manager-k8s-master03 1/1 Running 1 35m 192.168.92.12 k8s-master03 <none> <none>
kube-flannel-ds-amd64-d86ct 1/1 Running 0 37m 192.168.92.11 k8s-master02 <none> <none>
kube-flannel-ds-amd64-l8clz 1/1 Running 0 36m 192.168.92.13 k8s-node01 <none> <none>
kube-flannel-ds-amd64-vtppf 1/1 Running 1 42m 192.168.92.10 k8s-master01 <none> <none>
kube-flannel-ds-amd64-zg4z5 1/1 Running 1 37m 192.168.92.12 k8s-master03 <none> <none>
kube-proxy-4vwbb 1/1 Running 1 49m 192.168.92.10 k8s-master01 <none> <none>
kube-proxy-gnk2v 1/1 Running 0 37m 192.168.92.11 k8s-master02 <none> <none>
kube-proxy-kqm87 1/1 Running 0 36m 192.168.92.13 k8s-node01 <none> <none>
kube-proxy-n5mdh 1/1 Running 2 37m 192.168.92.12 k8s-master03 <none> <none>
kube-scheduler-k8s-master01 1/1 Running 2 48m 192.168.92.10 k8s-master01 <none> <none>
kube-scheduler-k8s-master02 1/1 Running 1 37m 192.168.92.11 k8s-master02 <none> <none>
kube-scheduler-k8s-master03 1/1 Running 2 36m 192.168.92.12 k8s-master03 <none> <none>
查看service
[root@k8s-master03 ~]# kubectl -n kube-system get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 51m
验证IPVS
查看kube-proxy日志,第一行输出Using ipvs Proxier.
[root@k8s-master01 ~]# kubectl -n kube-system logs -f kube-proxy-4vwbb
I0426 16:05:03.156092 1 server_others.go:177] Using ipvs Proxier.
W0426 16:05:03.156501 1 proxier.go:381] IPVS scheduler not specified, use rr by default
I0426 16:05:03.156788 1 server.go:555] Version: v1.14.1
I0426 16:05:03.166269 1 conntrack.go:52] Setting nf_conntrack_max to 131072
I0426 16:05:03.169022 1 config.go:202] Starting service config controller
I0426 16:05:03.169103 1 controller_utils.go:1027] Waiting for caches to sync for service config controller
I0426 16:05:03.169182 1 config.go:102] Starting endpoints config controller
I0426 16:05:03.169200 1 controller_utils.go:1027] Waiting for caches to sync for endpoints config controller
I0426 16:05:03.269760 1 controller_utils.go:1034] Caches are synced for endpoints config controller
I0426 16:05:03.270123 1 controller_utils.go:1034] Caches are synced for service config controller
I0426 16:05:03.352400 1 graceful_termination.go:160] Trying to delete rs: 10.96.0.1:443/TCP/192.168.92.11:6443
I0426 16:05:03.352478 1 graceful_termination.go:174] Deleting rs: 10.96.0.1:443/TCP/192.168.92.11:6443
......
查看代理规则
[root@k8s-master01 ~]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.96.0.1:443 rr
-> 192.168.92.10:6443 Masq 1 3 0
-> 192.168.92.11:6443 Masq 1 0 0
-> 192.168.92.12:6443 Masq 1 0 0
TCP 10.96.0.10:53 rr
-> 10.244.0.5:53 Masq 1 0 0
-> 10.244.0.6:53 Masq 1 0 0
TCP 10.96.0.10:9153 rr
-> 10.244.0.5:9153 Masq 1 0 0
-> 10.244.0.6:9153 Masq 1 0 0
UDP 10.96.0.10:53 rr
-> 10.244.0.5:53 Masq 1 0 0
-> 10.244.0.6:53 Masq 1 0 0
etcd集群
执行以下命令查看etcd集群状态
kubectl -n kube-system exec etcd-k8s-master01 -- etcdctl \
--endpoints=https://192.168.92.10:2379 \
--ca-file=/etc/kubernetes/pki/etcd/ca.crt \
--cert-file=/etc/kubernetes/pki/etcd/server.crt \
--key-file=/etc/kubernetes/pki/etcd/server.key cluster-health
示例
[root@k8s-master01 ~]# kubectl -n kube-system exec etcd-k8s-master01 -- etcdctl \
> --endpoints=https://192.168.92.10:2379 \
> --ca-file=/etc/kubernetes/pki/etcd/ca.crt \
> --cert-file=/etc/kubernetes/pki/etcd/server.crt \
> --key-file=/etc/kubernetes/pki/etcd/server.key cluster-health
member a94c223ced298a9 is healthy: got healthy result from https://192.168.92.12:2379
member 1db71d0384327b96 is healthy: got healthy result from https://192.168.92.11:2379
member e86955402ac20700 is healthy: got healthy result from https://192.168.92.10:2379
cluster is healthy
验证HA
在master01上执行关机操作,建议提前在其他节点配置kubectl命令支持。
[root@k8s-master01 ~]# shutdown -h now
在任意运行节点验证集群状态,master01节点NotReady,集群可正常访问:
[root@k8s-master02 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 NotReady master 19m v1.14.1
k8s-master02 Ready master 11m v1.14.1
k8s-master03 Ready master 10m v1.14.1
k8s-node01 Ready <none> 9m21s v1.14.1
查看网卡,vip自动漂移到master03节点
[root@k8s-master03 ~]# ip a |grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.92.12/24 brd 192.168.92.255 scope global noprefixroute ens33
inet 192.168.92.30/24 scope global secondary ens33