云计算基础(二):Hadoop单机、伪分布、集群配置
Linux机器分布式配置、SSH配置、公用/私有密钥配置;
Hadoop单机配置;
Hadoop伪分布式集群配置;
Hadoop集群配置;
基准程序评估Hadoop集群性能
1、掌握Linux机器分布式配置、SSH配置、公用/私有密钥配置;
在完成虚拟机的免密钥登陆之前,先安装SSH服务
sudo apt-get update
sudo apt install openssh-server
然后通过/usr/sbin/sshd 打开SSH服务
ifconfig
分别查看虚拟机ip地址

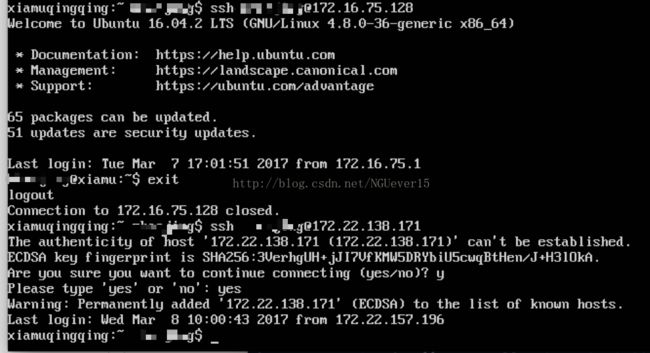
选定master(mac)和slave(两台ubuntu虚拟机) ,这次实现循环双向登陆。
在master和slave 上分别执行下面的命令
ssh-keygen -t rsa -P '' -f/home/username/.ssh/id_dsa
在master的/home/username/.ssh目录下,执行 :
cat id_rsa.pub> authorized_keys
将master上的authorized_keys拷贝到其中一个slave的相同目录下。命令:
scp /Users/username/.ssh/authorized_keys [email protected]:/home/username/.ssh/
把ip地址为172.16.75.128的slave的信息加入到authorized_keys:
cat id_rsa.pub >> authorized_keys
把ip地址为172.16.75.128的slave的authorized_keys拷贝到ip地址为172.22.140.244的slave的信息加入authorized_keys:
scp /home/ username /.ssh/authorized_keys username @172.22.140.244:/home/username /.ssh/
cat id_rsa.pub >> authorized_keys
此时authorized_keys拥有所有机器的id_rsa.pub,那么把他scp到其他节点上即可:
scp /Users/ username /.ssh/authorized_keys username @172.22.138.171:/home/username /.ssh/
scp /home/ username /.ssh/authorized_keys username @172.16.75.128:/home/username /.ssh/
此时,所有节点的id_dsa.pub 都必须加入到authorized_keys中,所以,所配置的三台机器都可以免密钥登陆了。

2、hadoop的单机、伪分布、分布式集群配置;
按照实验要求下载java 环境和 Hadoop 版本
配置java环境变量
sudo gedit /etc/profile
加入下面的内容
export JAVA_HOME=/usr/lib/jdk1.8.0_121/
export JRE_HOME=$JAVA_HOME/jre
exportCLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
执行下面的命令让更改生效
source /etc/profile
查看安装好的java 版本
java –version

Hadoop单机配置
接下来执行命令:sudo gedit /etc/sudoers
在root ALL=(ALL:ALL)ALL 下一行增加以下内容
zhaojing ALL=(ALL:ALL) ALL
保存并关闭文档
接下来解压hadoop-2.6.4
tar -zxvf hadoop-2.6.4.tar.gz
sudo mv hadoop-2.6.4 /usr/local/hadoop-2.6.4
设置hadoop环境变量
sudo gedit /etc/profile
加入下面的内容
export HADOOP_HOME=/usr/local/hadoop-2.6.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
exportHADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
执行下面的命令让更改生效
source /etc/profile
查看安装好的hadoop 版本
hadoop version

Hadoop 伪分布配置
sudo vi/usr/local/hadoop-2.6.4/etc/hadoop/core-site.xml
插入下面的内容
sudo vi/usr/local/hadoop-2.6.4/etc/hadoop/yarn-site.xml
插入下面的内容
cd /usr/local/hadoop-2.6.4/etc/hadoop
cp mapred-site.xml.template mapred-site.xml
sudo vi mapred-site.xml
插入下面的内容
sudo vi hdfs-site.xml
插入下面的内容
接着执行格式化hdfs
hdfs namenode -format



显示格式化成功。
接着通过sbin/start-dfs.sh和sbin/start-yarn.sh启动管理
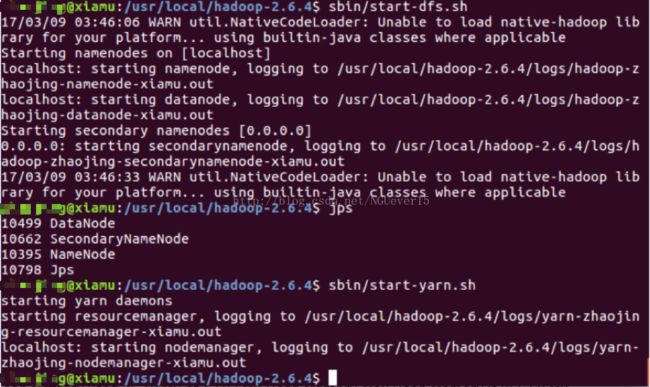
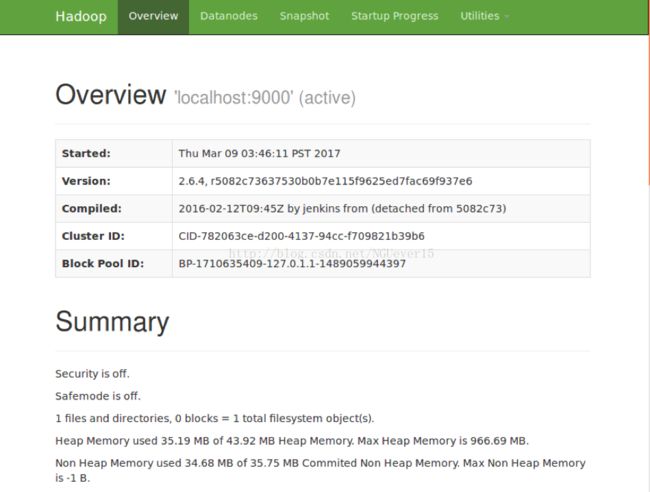
接下来就可以在网页中查看安装好的hadoop伪分布了。
3、以及用基准程序评估Hadoop集群性能。
测试内容
cd /usr/local/hadoop-2.6.4/
bin/hadoop fs -mkdir -p input
hadoop fs -copyFromLocal README.txt input
hadoop jarshare/hadoop/mapreduce/sources/hadoop-mapreduce- examples-2.6.4-sources.jarorg.apache.hadoop.examples.WordCount inputoutput

hadoop fs -cat output/*

测试完成之后,通过sbin/stop-dfs.sh 对hadoop进行关闭。