多任务模型在推荐算法中应用
1.ESMM: Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate
CVR是指从点击到购买的转化,传统的CVR预估会存在两个问题:样本选择偏差和稀疏数据。
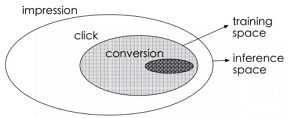
样本选择偏差是指模型用用户点击的样本来训练,但是预测却是用的整个样本空间。数据稀疏问题是指用户点击到购买的样本太少。因此阿里提出了ESMM模型来解决上述两个问题:主要借鉴多任务学习的思路,引入两个辅助的学习任务,分别用来拟合pCTR和pCTCVR。

ESMM模型由两个子网络组成,左边的子网络用来拟合pCVR,右边的子网络用来拟合pCTR,同时,两个子网络的输出相乘之后可以得到pCTCVR。因此,该网络结构共有三个子任务,分别用于输出pCTR、pCVR和pCTCVR。
假设用x表示feature(即impression),y表示点击,z表示转化,那么根据pCTCVR = pCTR * pCVR,可以得到:
![]()
则pCVR的计算为:
![]()
由上面的式子可知,pCVR可通过pCTR和pCTCVR推导出来,那么我们只需要关注pCTR和pCTCVR两个任务即可,并且pCTR和pCTCVR都可以从整个样本空间进行训练?因为对于pCTR来说可将有点击行为的曝光事件作为正样本,没有点击行为的曝光事件作为负样本,对于PCTCVR来说,将同时有点击行为和购买行为的曝光事件作为正样本,其他作为负样本。模型的loss函数:
![]()
另外两个子网络的embedding层是共享的,由于CTR任务的训练样本量要远超过CVR任务的训练样本量,ESMM模型中embedding层共享的机制能够使得CVR子任务也能够从只有展现没有点击的样本中学习,从而能够极缓解训练数据稀疏性问题。
2.DUPN:Perceive Your Users in Depth: Learning Universal User Representations from Multiple E-commerce Tasks
多任务学习的优势:可共享一部分网络结构,比如多个任务共享一份embedding参数。学习的用户、商品向量表示可方便迁移到其它任务中。本文提出了一种多任务模型DUPN:

模型分为行为序列层、Embedding层、LSTM层、Attention层、下游多任务层。
- 行为序列层:输入用户的行为序列x = {x1,x2,…,xN},其中每个行为都有两部分组成,分别是item和property项。item包括商品id和一些side-information比如店铺id、brand等(好多场景下都要带side-information,这样更容易学习出商品的embedding表示)。property项表示此次行为的属性,比如场景(搜索、推荐等场景)时间、类型(点击、购买、加购等)。
- Embedding层:主要多item和property的特征做处理。
- LSTM层:得到每一个行为的Embedding表示之后,首先通过一个LSTM层,把序列信息考虑进来。
- Attention层:区分不同用户行为的重要程度,经过attention层得到128维向量,拼接上128维的用户向量,最终得到一个256维向量作为用户的表达。
- 下游多任务层:CTR、L2R(Learning to Rank)、用户达人偏好FIFP、用户购买力度量PPP等。
另外,文中也提到了两点多任务模型的使用技巧:
天级更新模型:随着时间和用户兴趣的变化,ID特征的Embedding需要不断更新,但每次都全量训练模型的话,需要耗费很长的时间。通常的做法是每天使用前一天的数据做增量学习,这样一方面能使训练时间大幅下降;另一方面可以让模型更贴近近期数据。
模型拆分:由于CTR任务是point-wise的,如果有1w个物品的话,需要计算1w次结果,如果每次都调用整个模型的话,其耗费是十分巨大的。其实user Reprentation只需要计算一次就好。因此我们会将模型进行一个拆解,使得红色部分只计算一次,而蓝色部分可以反复调用红色部分的结果进行多次计算。
3. “猜你喜欢”深度学习排序模型
根据业务目标,将点击率和下单率拆分出来,形成两个独立的训练目标,分别建立各自的Loss Function,作为对模型训练的监督和指导。DNN网络的前几层作为共享层,点击任务和下单任务共享其表达,并在BP阶段根据两个任务算出的梯度共同进行参数更新。网络在最后一个全连接层进行拆分,单独学习对应Loss的参数,从而更好地专注于拟合各自Label的分布。
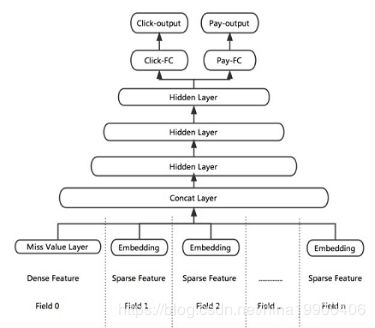
这里有两个技巧可借鉴下:
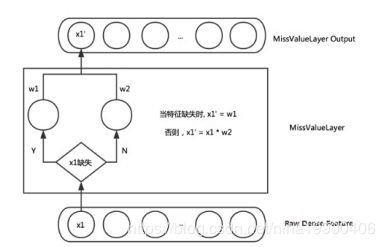
Missing Value Layer:缺失的特征可根据对应特征的分布去自适应的学习出一个合理的取值。
KL-divergence Bound:通过物理意义将有关系的Label关联起来,比如p(点击) * p(转化) = p(下单)。加入一个KL散度的Bound,使得预测出来的p(点击) * p(转化)更接近于p(下单)。但由于KL散度是非对称的,即KL(p||q) != KL(q||p),因此真正使用的时候,优化的是KL(p||q) + KL(q||p)。

参考文献:
1.Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate,
地址:https://arxiv.org/pdf/1804.07931.pdf
2.推荐系统遇上深度学习(十九)–探秘阿里之完整空间多任务模型ESMM,
地址:https://arxiv.org/abs/1804.07931
3.Perceive Your Users in Depth: Learning Universal User Representations from Multiple E-commerce Tasks,
地址:https://arxiv.org/pdf/1805.10727.pdf