DIPRE - Dual Iterative Pattern Relation Expansion
One seed containing two data points of a known relationship are entered into the algorithm. The algorithm searches the internet (or any other sufficiently large body of string data) looking for a page containing both data points. When a resource is found, the algorithm builds a regular expression based on the relationship and then uses the resulting pattern to extract similar data points from the same page/domain.
Sergey Brin, of Google.com, has a patent on the idea, so no need rushing to patent office. However, his thesis had plenty of room for improvement (see Stanford.edu for his thesis); if I recall, he wanted to use the pattern from a page only to extract data from the same page. I have expanded the idea by generating the pattern and testing the pattern at the domain level for a frequency test to determine if the pattern represents a database generated pattern.
So, now to the meat. Einstein commented that if it can't be explained simply, then it probably isn't true. So I've used some color coding and a vertical flow map to explain the algorithm. After you review the algorithm map, I have included a sample link below so that you can see an actual output from the test seed used in the flow diagram
(
but if you can't wait, http://www.alexmayers.com/q/?q=85a4c8671be552e72bc8388eddda2b5d,0,0,0,80,,, ). (note the map does not contain the entire database design; I've only included tables essential to understanding how the algorithm works)
The seed for our example is: 1. Of Mice and Men; and 2. Steinbeck, John
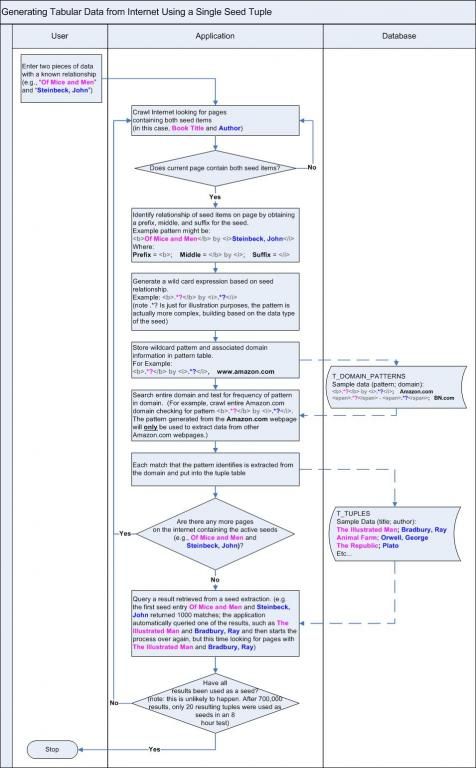
I'm posting some best practices for this type of extraction because I wasted a lot of time trying to get clean results from a single seed match for a large scale data set.
1. Use statistical data in your algorithm to choose the next seed tuple. To attain this, I stored every match, even if it coincided with a previous match from a different domain. By doing this you can use a query that selects the highest reoccurring tuples for your next seed, which ensures you are feeding a valid seed back into the algorithm. Without statistical data analysis, your algorithm will fail.
2. If your algorithm is analyzing HTML strings, make sure your regular expressions replace ID attributes in tags. What I did was to take any ID="XYZ" pattern and replace it with a wildcard like ID=".*?", which ensures you compensate for dynamically loaded data. I nearly doubled my data capture by replacing the inner ID attribute values.
3. For crawling, use statistics to bubble sites that return more data to the top of the crawl list. BUT, make sure you have a mechanism to randomize the crawl pattern to ensure you don't hit the same site consecutively (you don't want waste your target site's network resources). I attained this by adding a T_LAST_VISITED table, which logged every domain visited by the crawler for a 20 second period which ensured the same domain wasn't hit more than 1 time every 20 seconds using a simple join. This, in combination with my "bubble" query that pushed the highest tuple returners to the top, enabled a few dozen high-quality data return sites to populate my tuple tables.
Data was returned from more than a thousand domains, but the top 10 data contributors were:
antiqbook.com
rainydaypaperback.com
berwynlibrary.net
overbooked.org
aliensandalibis.com
charlise.com
worcpublib.org
tripod.com
lecom.edu
webrary.org
Regarding the pattern to extract data, although I did remove distinct attribute information, such as ID=".*?", I didn't remove intermediate data. For example, in the following situation, a match would have returned false for my algorithm:
[td]Of Mice and Men[/td] [td]ISBN:0142000671[/td] [td]by Steinbeck, John[/td]
The reason is that the ISBN number in the middle section is unique, so the pattern generated by this match wouldn't have matched any other values on the domain. I ran into this problem when I tried a test for baseball cards and the related sequence card number. I noticed a lot of patterns with unique intermediate data. One solution to this problem is to identify the data type of between the > < symbols and have the algorithm generate a wildcard, and then have the algorithm run a frequency test across the domain for the intermediate pattern before plugging it into the master pattern. For example, create a wildcard pattern for the intermediate value "ISBN:0142000671" in the example above, generate a wildcard based on the data pattern "[A-Z]{4}/:[0-9]{10}". This would successfully account for database generated pages with distinct intermediate values.
The bottom line is that this type of extraction will produce distortion. The only way to reduce distortion is to use statistical crawling and statistically chosen seeds in your algorithms. By doing so, you can essentially query off the top "clean" percentile with high confidence of data accuracy. After saying that, however, in the "Of Mice and Men" / "Steinbeck, John" seed, I found almost no distortion. I did a query looking for fields containing numbers in the author tuple column (which is an easy test for finding bad data in a tuple where only letters are expected) and only found 20-30 records out of 700,000 with numbers (besides dates in periodicals and volume numbers for anonymously authored volumes). If I had the computer resources to let the crawler continue, it would have built a full resource of every author and title. Because the statistical crawl pattern and statistical seed pattern were successful, most of the CPU time was spent during the regular expression process. For every page it hit, it was extracting 50-100 authors and titles per page. So if a statistically based algorithm is successful, you should notice that as time progresses, the crawl time should decrease and regular expression CPU time should conversely increase.
I think I have this algorithm dialed. My primary project for now is to build an application that successfully identifies grammatical usages based on large data source, being the internet. A result of this will be to use the grammatical rules to extract tabular data (just like the DIPRE algorithm). Initially, I set about using open-source grammars, dictionaries, and thesauri to generate the algorithm, but found this to be shortsighted. Knowing what I know about linguistics, language and idiom develops so rapidly that to keep up with it would be impossible using a static rule set; the rule set needs to change in real as the language evolves. So, I decided the best course of action would be to create an algorithm that crawls the internet and generates the rules based on the actual language use. I won't describe my algorithm in detail here; but I will say it involves entering a single seed verb, noun, adjective, and adverb in order to identify every part of speech for every word. I am not adding articles or prepositions initially since they tend to be more static than verbs, nouns, adjectives, and adverbs. I've been performing some experiments with success and am looking forward to generating a large-scale test, which will undoubtedly consumer more resources than have... but that's the fun.