Redis2.2.2源码学习——dict中的hashtable扩容和rehash
Redis2.2.2
dict是Redis的hash数据结构,所有类型的元素都可以依据key值计算hashkey,然后将元素插入到dict的某个hash链上(采用拉链法解决hash冲突)。其中,dict的中的hashtable(dictht)的扩容是dict很重要的部分。Redis的“管家”函数serverCron会依据一定的算法(dict中的used与size的比值)判定是否开始进行hashtable的扩容。dict中的ht[1]是作为扩容的临时数据,扩容之后,hashtalbe的长度将变长,那么hashtalbe的masksize与原来的makssize就不同了,那么计算出的hashkey也将不同。所以就需要Rehash对ht[0]中的元素重新计算hashkey。
在Rehash阶段,首先将原来的ht[0]中的元素重新rehash到ht[1]中,故而要耗费大量的力气从新计算原来的ht[0]表中元素的在ht[1]表总的hashkey,并将元素转移到ht[1]的表中。由于这样Rehash会耗费大量的系统资源,如果一次性完成一个dict的Rehash工作,那么将会对系统中的其他任务造成延迟? 作者的处理方式是:同样在serverCron中调用rehash相关函数,1ms的时间限定内,调用rehash()函数,每次仅处理少量的转移任务(100个元素)。这样有点类似于操作系统的时间片轮转的调度算法。
下图是Dict相关数据结构(引用: Redis源码剖析(经典版).docx )
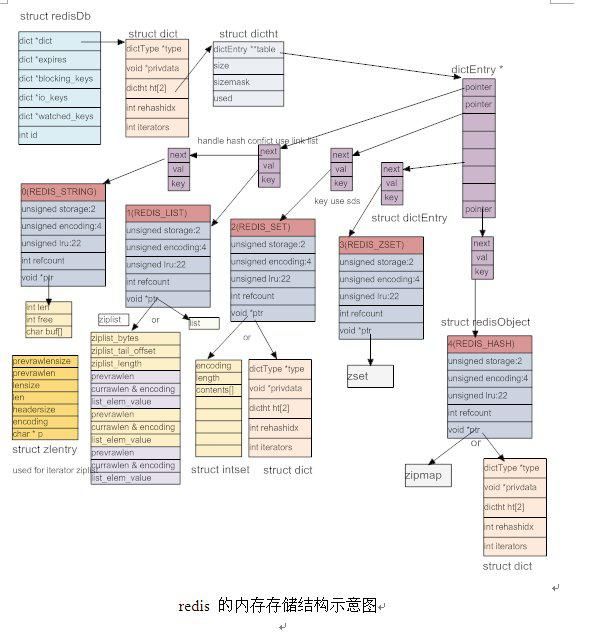
代码分析如下:
-----------------------Data Sturcter----------------------------------------
typedef struct dictEntry {
void *key;
void *val; //空类型,redis的类型主要有sds,list,set等,val指针指向其中的结构
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;//hash表,每个table[i]链表存储着一个hashkey相等的dictEntry指针
unsigned long size;//table[]的大小
unsigned long sizemask;// = size-1
unsigned long used;//当前table中存储的dictEntry指针的个数
} dictht;
typedef struct dict {
dictType *type;//hash相关的操作hander
void *privdata;
dictht ht[2];//ht[0]作为dict的实际hash结构,ht[1]做为扩容阶段的转储结构
int rehashidx; //标志dict是否处于rehash阶段,如果值为-1,表示不处于rehash。否则,在rehash中所谓hashtalbe的索引下标
int iterators; /* number of iterators currently running */
} dict;
------------------------Redis's main----------------------------------------
main() >
initServerConfig()
server.activerehashing = 1;
initServer()
//设置定时事件,1ms调用一次serverCron()
aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL);
//进入事件轮询,详见:http://blog.csdn.net/ordeder/article/details/12791359
aeMain(server.el)
------------------------serverCron-----------------------------------------
/*serverCron是Redis的协调员,其中就包括:1.检查是否有hashtalbe需要扩容,并执行必要的扩容2.执行incrementRehash执行固定时间的Rehash任务*/
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData)
/*记录sever调用serverCron的总次数
*对于需要协调的不同的任务,可以依据loops%n的方式设置不同的频率 */
int loops = server.cronloops
。。。
/* We don't want to resize the hash tables while a bacground saving
* is in progress: the saving child is created using fork() that is
* implemented with a copy-on-write semantic in most modern systems, so
* if we resize the HT while there is the saving child at work actually
* a lot of memory movements in the parent will cause a lot of pages
* copied. 后台没有对数据进行操作的程序...*/
if (server.bgsavechildpid == -1 && server.bgrewritechildpid == -1) {
/*loops % 10 :
serverCron没循环10次,进行一次tryResizeHashTables检查*/
if (!(loops % 10)) tryResizeHashTables();
//下面的for是tryResizeHashTables源码
>for (j = 0; j < server.dbnum; j++) {
//htNeedsResize:检查used*100/size < REDIS_HT_MINFILL(设定的阈值)
if (htNeedsResize(server.db[j].dict))
dictResize(server.db[j].dict);//见下文分析 扩容Resize
if (htNeedsResize(server.db[j].expires))
dictResize(server.db[j].expires);
>}
if (server.activerehashing)
incrementallyRehash();//见下文分析 Rehash
}
------------------------扩容Resize------------------------------------------
/* Resize the table to the minimal size that contains all the elements,
* but with the invariant of a USER/BUCKETS ratio near to <= 1 */
int dictResize(dict *d)
{
int minimal;
if (!dict_can_resize || dictIsRehashing(d)/*rehashidx ?= -1*/) return DICT_ERR;
minimal = d->ht[0].used;
if (minimal < DICT_HT_INITIAL_SIZE)
minimal = DICT_HT_INITIAL_SIZE;
//minimal = Max(d->ht[0].used,DICT_HT_INITIAL_SIZE)
//原来的容量为size,现要扩充到used或DICT_HT_INITIAL_SIZE
return dictExpand(d, minimal);
}
/* Expand or create the hashtable */
int dictExpand(dict *d, unsigned long size)
{
dictht n; /* the new hashtable */
//将size扩展到2^n : while(1) { if (i >= size) return i; i *= 2; }
unsigned long realsize = _dictNextPower(size);
/* the size is invalid if it is smaller than the number of
* elements already inside the hashtable */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
/* Allocate the new hashtable and initialize all pointers to NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* 如果是在dict的第一次申请空间?那么就直接将n赋给d->ht[0],而且不需要rehash */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n;
d->rehashidx = 0; // rehashidx! = -1; 表示d进入了rehash阶段
return DICT_OK;
}
-------------------------Rehash-----------------------------------------
/*记得前文:serverCron作为一个定时器事件的处理函数,定时的时间为1ms
在serverCron会调用incrementallyRehash()函数去不断的完成rehash任务。
这里说“不断的"的意思是,rehash的任务不是一次性的函数调用完成的,可能需要
serverCron调用多次incrementallyRehash()来完成。
下文就是incrementallyRehash()函数和子函数的额调用关系,incrementallyRehash()
的执行限时为1ms,在这时间内,dictRehash()会以一定量任务(100)为单元进行d->ht的
转移。
*/
incrementallyRehash(void)
遍历server.db[],对db中的dict进行rehash,每个dict的限定时间为1ms
dictRehashMilliseconds(server.db[j].dict,1)
while(dictRehash的执行时间<1ms)
dictRehash(d,100)//详见下文源码
将dict->ht[1]取出100个元素(dictEntry) Rehash到dict->ht[0]
/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
* Note that a rehashing step consists in moving a bucket (that may have more
* thank one key as we use chaining) from the old to the new hash table. */
/*将依次将d->ht[1].table[]中的元素搬到d->ht[0].table[],修改相关的used。
d->rehashidx:记录着当前的hashtable中搬了那一条链表的索引下标
d->ht[0].table[d->rehashidx] => d->ht[0].table[d->rehashidx]
完成一个dict的Rehash后,重置d->rehashidx = -1 */
int dictRehash(dict *d, int n) {
if (!dictIsRehashing(d)) return 0;
while(n--) {
dictEntry *de, *nextde;
/* Check if we already rehashed the whole table... */
//d->ht[0].used == 0 : 说明d->ht[0] 已经全部搬到 d->ht[1]
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1; //该dict的Rehash结束 设置为 -1
return 0;
}
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
while(d->ht[0].table[d->rehashidx] == NULL) d->rehashidx++;
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
unsigned int h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--; ////////
d->ht[1].used++; ////////
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
return 1;
}