基于iOS平台的OCR识别技术的分析与研究
最近老大要求是通过使用Tesseract OCR iOS来 对货柜的货柜号进行识别,然后去深入研究了下这方面的东西。
以下引自百度百科:
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。如何除错或利用辅助信息提高识别正确率,是OCR最重要的课题,ICR(Intelligent Character Recognition)的名词也因此而产生。衡量一个OCR系统性能好坏的主要指标有:拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。
看上去很高大上有木有!
后来查了下资料,在iOS端的OCR-SDK还是挺多的,国内的有汉王,云脉等等,国外的话有ABBYY,Tesseract 等等,本菜鸟这次的研究就是基于Tesseract的。
根据官方提供的API我的Demo很快就做出来了,下面为识别图片:

然后这是识别结果:

- -....SHEN ME GUI!!!!!!!
好吧,识别失败了。
于是- -,老大叫我退而求其次的只识别货柜的货柜号

然后,我用PhotoShop(- -||)p了下:

结果:
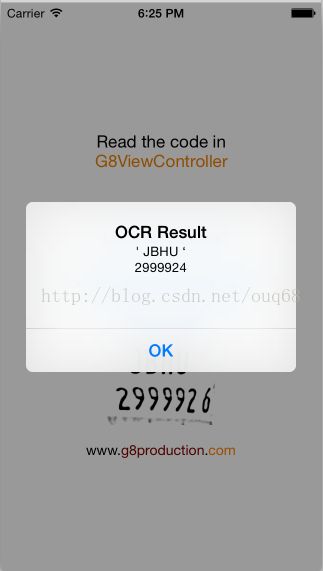
哟,识别率还挺高的。
以下是我分析出来的原因:
Tesseract OCR iOS提供了一个很强大的识别图片中文字的功能,只要你导入了相应的语言包,然后提供一个识别度很高的图片的话(注意这里!是识别度很高的图片- -),那么他的识别率是相当高的。
然而,这个lib给我们提供的对图片进行处理的api是很少的,只有两个:
-(UIImage *)blackAndWhite;
-(UIImage *)grayScale;只是简单的将图片变成黑白及增加灰度。
再看看我们强大的百度百科额- -,
看上去又很高大上对不- -
其实就是说,这个lib是用来识别一个处理好了的识别率很高的图片的lib.
所以,我决定用一个图片处理的lib先对图片进行处理然后再用Tesseract对他进行识别- -。
于是,我找到了OpenCV..
OpenCV的全称是:Open Source Computer Vision Library。OpenCV是一个基于(开源)发行的跨平台计算机视觉库,可以运行在Linux、Windows和Mac OS操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
- -(也是百度百科的)
我这种菜鸟当然不可能在短时间内学会OpenCV的所有知识的- -,所以,在简单的了解后我就去万能的Git上找东西了,万幸的我找到一个基于OpenCV的对图片进行倾斜校正及滤镜优化的lib,MAImagePickerController
于是,我试着将这个lib与OCR进行结合,效果杠杠滴,一口气识别五个,不费劲,哈哈,不过因为太懒所以只做了识别英文的。
Demo在此:http://download.csdn.net/detail/ouq68/8465893
十分抱歉,之前资源上传错了,,,现在补上新的地址,之前没下载到的请发邮箱给我,,我补发给您。。。
http://download.csdn.net/detail/ouq68/8528749
转载请注明出处,哈哈哈~