ACID理论
CAP理论 Consistency,Availability,Partition tolerance
BASE理论 Basically Available基本可用,Soft state软状态,Eventually consistent最终一致性
两阶段提交(存在中心节点同步阻塞,单点问题,脑裂,太过保守)
三阶段提交
Paxos算法,拜占庭将军问题
Paxos使用场合
Chubby,Hypertable
zookeeper的ZAB协议
zookeeper客户端 ZkClient,Curator
Zookeeper的使用场景
1.数据发布/订阅
2.负载均衡
3.命名服务
4.分布式协调/通知
5.集群管理
6.Master选举
7.分布式锁(注意羊群效应)
8.分布式队列
Zookeeper在实际中的应用
1.Hadoop的HA
2.HBase
3.Kafka
4.阿里的消息中间件 Metamorphosis
5.阿里的RPC框架 Dubbo
6.基于mysql的增量订阅和消费组件 canal
7.分布式数据库同步系统 Otter
8.轻量级分布式通用搜索平台 终搜
9.实时计算引擎 JStorm
Zookeeper运维
JMX和Jconsole连接
四字命令
基本配置和高级配置
Zookeeper的四字命令
| ZooKeeper 四字命令 |
功能描述 |
| conf |
输出相关服务配置的详细信息。 |
| cons |
列出所有连接到服务器的客户端的完全的连接 / 会话的详细信息。包括“接受 / 发送”的包数量、会话 id 、操作延迟、最后的操作执行等等信息。 |
| dump |
列出未经处理的会话和临时节点。 |
| envi |
输出关于服务环境的详细信息(区别于 conf 命令)。 |
| reqs |
列出未经处理的请求 |
| ruok |
测试服务是否处于正确状态。如果确实如此,那么服务返回“ imok ”,否则不做任何相应。 |
| stat |
输出关于性能和连接的客户端的列表。 |
| wchs |
列出服务器 watch 的详细信息。 |
| wchc |
通过 session 列出服务器 watch 的详细信息,它的输出是一个与 watch 相关的会话的列表。 |
| wchp |
通过路径列出服务器 watch 的详细信息。它输出一个与 session 相关的路径。 |
Zookeeper的序列化组件Jute
Jute是zookeeper中的序列化组件,
其前身是Hadoop record I/O 默认的序列化组件,等Apache Avro出现后,hadoop就用其替代了Jute
而zookeeper从第一个版本开始就一直用jute,后期官方也一直想找到其替代品,如用Avro,thrift,谷歌的protobuf等,因为jute也能满足需求,而且也要考虑对老版本的兼容性所以就一直使用jute了
Jute传输的格式

Jute请求头数据包格式

Jute响应头数据包格式
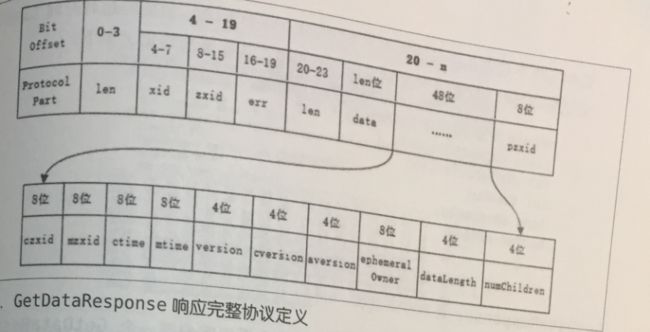
Zookeeper客户端
客户端和服务端的交互逻辑如下
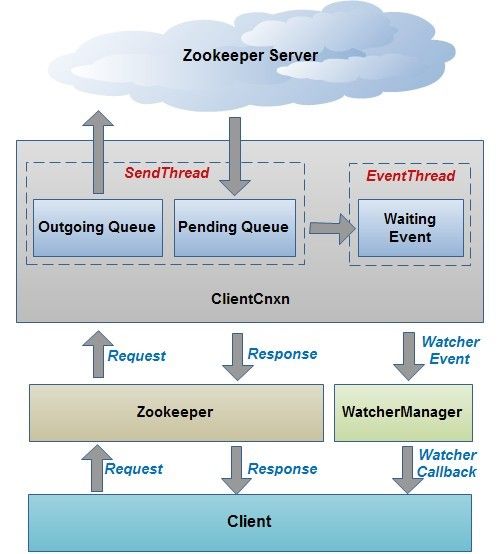
(1) Client端发送Request(封装成Packet)请求到Zookeeper
(2) Zookeeper处理Request并将该请求放入Outgoing Queue(顾名思义,外出队列,就是让Zookeeper服务器处理的队列),
(3) Zookeeper端处理Outgoing Queue,并将该事件移到Pending Queue中
(4) Zookeeper端消费Pending Queue,并调用finishPacket(),生成Event
(5) EventThread线程消费Event事件,并且处理Watcher.
Zookeeper实例 客户端的入口类
ClientWatchManager 客户端Watcher管理器
HostProvider 客户端地址列联表管理器
ClientCnxn 客户端核心现场,包括SendThread和EventThread
初始化过程
1.初始化Zookeeper对象
2.设置会话默认Watcher
3.构造Zookeeper服务器地址列表管理器HostProvider
4.创建并初始化客户端网络连接器ClientCnxn
5.初始化SendThread和EventThread
6.启动SendThread和EventThread
7.获取一个服务器地址
8.创建TCP连接
9.构造ConnectRequest请求,放到请求队列outgoingQueue队列中
10.发送请求ClientCnxnSocket从outgoingQueue中出去一个Package对象并序列化发送
11.接受服务端响应,ClientCnxnSocket接受服务端的响应
12.ClientCnxnSocket反序列化对象
13.连接成功后,处理readTimeout和connectTimeout等,通知HostProvider当前连接成功
14.生成时间
15.查询Watcher,event线程接受到事件后去ClientWatchManager中查询对应的watcher
16.处理事件
HostProvider接口
public interface HostProvider {
public int size();
public InetSocketAddress next(long spinDelay);
public void onConnected();
}默认实现StaticHostProvider,使用的是环形列表结构
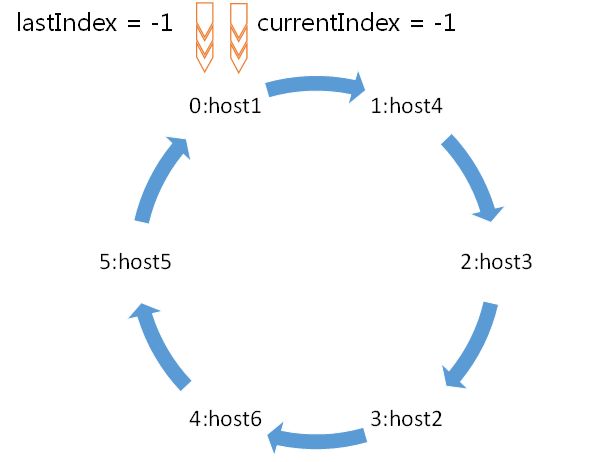
可以实现自己的HostProvider类,完成
1.动态变更的地址列表管理器
2.实现同机房优先策略
Zookeeper中的版本
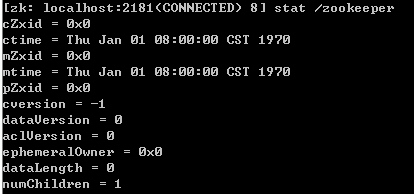
在ZooKeeper的每个znode节点的数据结构由以下几个字段组成:
1)czxid-znode节点创建时间所对应的zxid
2)mzxid-znode节点修改时间所对应的zxid
3)ctime-znode节点创建时从epoch过来的时间戳
4)mtime-znode节点修改时从epoch过来的时间戳
5)version-znode节点的版本号
6)cversion-znode子节点的版本号
7)aversion-znode节点的权限(ACL)版本号
8)ephemeralOwner-如果znode节点是临时节点,表示所属会话的id,如果不是临时节点则为0
9)dataLength-znode节点数据字段的长度
10)numChildren-znode节点的子节点数量
Zookeeper的ACL
zookeeper提供了如下几种机制(scheme):
- world: 它下面只有一个id, 叫anyone, world:anyone代表任何人,zookeeper中对所有人有权限的结点就是属于world:anyone的
- auth: 它不需要id, 只要是通过authentication的user都有权限(zookeeper支持通过kerberos来进行authencation, 也支持username/password形式的authentication)
- digest: 它对应的id为username:BASE64(SHA1(password)),它需要先通过username:password形式的authentication
- ip: 它对应的id为客户机的IP地址,设置的时候可以设置一个ip段,比如ip:192.168.1.0/16, 表示匹配前16个bit的IP段
- super: 在这种scheme情况下,对应的id拥有超级权限,可以做任何事情(cdrwa)
ZK的节点有5种操作权限:
CREATE
READ
WRITE
DELETE
ADMIN
也就是 增、删、改、查、管理权限,这5种权限简写为
crwda(即:每个单词的首字符缩写)
注:这5种权限中,delete是指对子节点的删除权限,其它4种权限指对自身节点的操作权限
创建auth,执行auth列子如下
[zk: localhost:2181(CONNECTED) 7] create /my_node 0 Created /my_node [zk: localhost:2181(CONNECTED) 8] setAcl /my_node digest:nima:ACFm5rWnnKn9K9RN/O c8qEYGYDs=:w cZxid = 0x43ee ctime = Wed Jan 31 18:13:33 CST 2018 mZxid = 0x43ee mtime = Wed Jan 31 18:13:33 CST 2018 pZxid = 0x43ee cversion = 0 dataVersion = 0 aclVersion = 1 ephemeralOwner = 0x0 dataLength = 1 numChildren = 0 [zk: localhost:2181(CONNECTED) 9] getAcl /my_node 'digest,'nima:ACFm5rWnnKn9K9RN/Oc8qEYGYDs= : w [zk: localhost:2181(CONNECTED) 10] get /my_node Authentication is not valid : /my_node
zookeeper会话
创建sessionID,TickTime,TimeOut
SessionTracker的分桶策略,按固定时间段一次性处理若干会话检查是否超时
会话自动重连机制
服务端整体架构
单机版zookeeper启动流程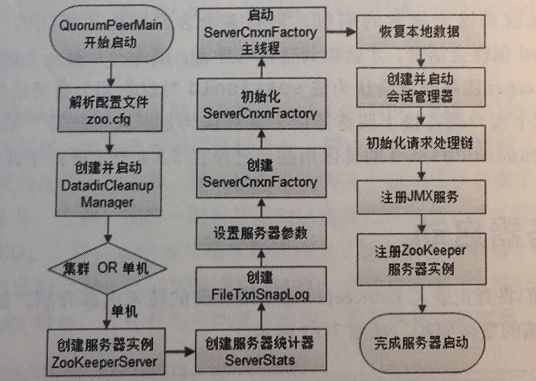
启动流程
1.统一由QuorumPeerMain作为启动类,集群和单机都是
2.解析配置文件zoo.cfg
3.创建并启动历史文件清理器DatadirCleanupManager
4.判断当前是集群模式还是单机模式
5.再次进行配置文件zoo.cfg的解析
6.创建服务器实例ZookeeperServer
初始化过程
1.初始化创建服务器统计器ServerStats
2.创建ZooKeeper数据管理器FileTxnSnapLog
3.设置服务器tickTime和会话超时时间限制
4.创建ServerCnxnFactory
5.初始化ServerCnxnFactory
6.启动ServerCnxnFactory主线程
7.恢复本地数据
8.创建并启动会话管理器
9.吃时候ZooKeeper的请求处理器
10.注册JMX服务
11.注册ZooKeeper服务器实例
集群版本启动流程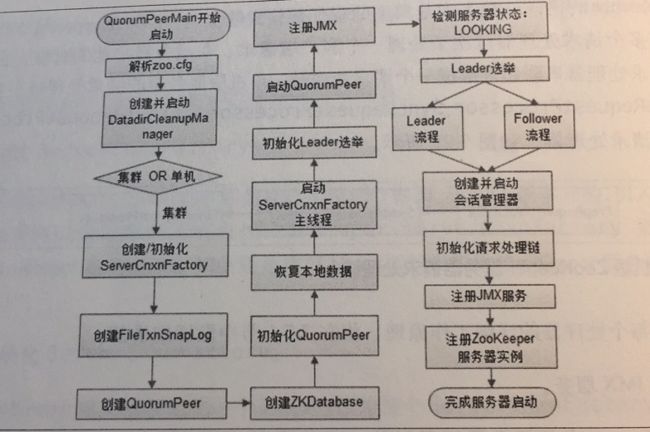
启动流程
1.统一由QuorumPeerMain作为启动类
2.解析配置文件zoo.cfg
3.创建并启动历史文件清理器DatadirCleanupManager
初始化
1.创建ServerCnxnFactory
2.初始化ServerCnxnFactory
3.创建Zookeeper数据管理器FileTxnSnapLog
4.创建QuorumPeer实例
5.创建内存数据库ZKDatabase
6.初始化QuorumPeer
7.恢复本地数据
8.启动ServerCnxnFactory主线程
Leader选举
1.初始化Leader
2.注册JMX
3.检测当前服务器状态
4.Leader选举
Leader选举
SID 服务器ID
ZXID 事务ID
每个服务器都发送 (SID,ZXID),然后投票
如果收到的ZXID比自身的大,则将投票更新为对方的再广播投票出去
ZXID一样则比较SID,最终能生成一个最大的投票也就是leader
服务端会话处理流程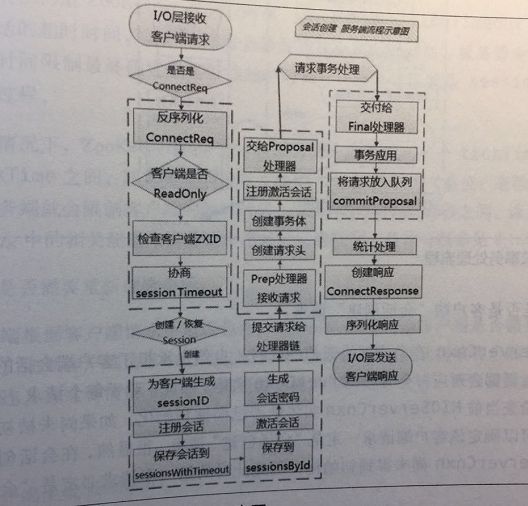
处理流程
1.IO层接受来自客户端的请求
2.判断是否客户端 会话创建 请求
3.反序列化ConnectRequest请求
4.判断是否是ReadOnly客户端
5.检查客户端ZXID
6.协商sessionTimeout
7.判断是否需要重新创建会话
会话创建流程
8.为会话创建sessionID
9.注册会话
10.激活会话
11.生产会话密码
12.将请求交给Zookeeper的PrepRequestProcessor处理器进行处理
13.创建请求事务头
14.创建请求事务体
15.注册与激活会话
事务处理流程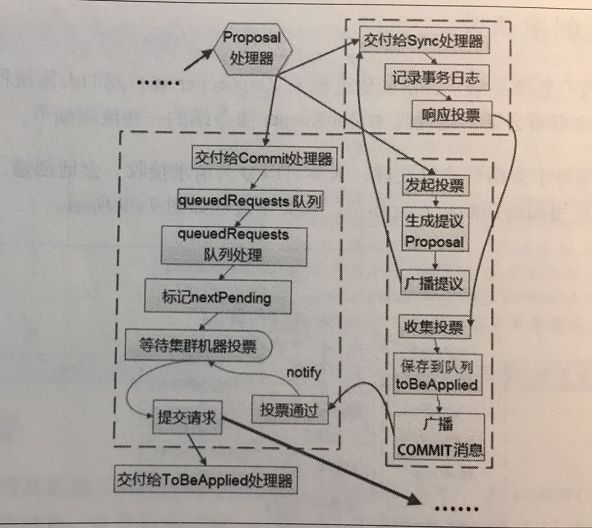
16.将请求交给ProposalRequestProcessor处理器
Proposal流程
1.发起投票
2.生成提议Proposal
3.广播提议
4.收集投票
5.将请求放入toBeApplied队列
6.广播COMMIT消息
Commit流程
1.将请求交给CommitProcessor处理器
2.处理queuedRequest队列处理
3.标记nextPending
4.等待Proposal投票
5.投票过程
6.提交请求
事务应用
17.交付给FinalRequestProcessor处理器
18.事务应用
19.将事务请求放入队列commitProposal
20.统计处理
21.创建响应ConnectResponse
22.序列化ConnectResponse
23. IO层发送响应给客户端
事务日志文件
snapshot数据快照文件
这两个目录应该独立开
DataTree数据结构 Map
leader和fellower同步
1.直接差异化同步 DIFF同步
2.先回滚再差异化同步 TRUNC+DIFF同步
3.仅回滚同步 TRUNC同步
4.全量同步 SNAP同步
参考
Zookeeper服务器配置项详解
ZooKeeper源码分析-Jute-第一部分
读《从Paxos到Zookeeper 分布式一致性原理与实践》笔记之客户端
Zookeeper 客户端源码吐血总结
分布式服务管理框架-Zookeeper节点ACL
zookeeper curator处理会话过期session expired
https://www.cnblogs.com/kangoroo/p/7538314.html