Spark 2.4.4在CentOS 7.6开启运行单机版,并Java客户端连接单机版-成功版(二)
大家运行spark-shell并不是Spark真正运行,需要运行spark-all.sh,在运行之前,还要运行下面几个步骤:
配置Spark
进入 ${SPARK_HOME}/conf 目录
查看
![]()
拷贝 spark-env.sh.template 为 spark-env.sh
拷贝 slaves.template 为 slaves
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
![]()
slaves文件内容就是localhost
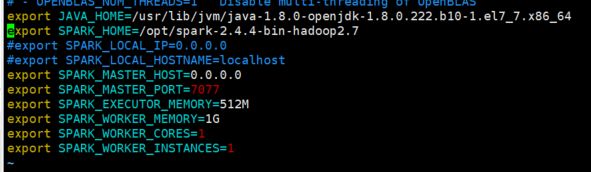
用 vim 编辑 spark-env.sh,在末尾添加
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-1.el7_7.x86_64
export SPARK_HOME=/opt/spark-2.4.4-bin-hadoop2.7
#export SPARK_LOCAL_IP=0.0.0.0
#export SPARK_LOCAL_HOSTNAME=localhost
export SPARK_MASTER_HOST=0.0.0.0
export SPARK_MASTER_PORT=7077
export SPARK_EXECUTOR_MEMORY=512M
export SPARK_WORKER_MEMORY=1G
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
如下图所示:
运行spark
进入spark-2.4.4-bin-hadoop2.7/sbin目录,运行spark-all.sh
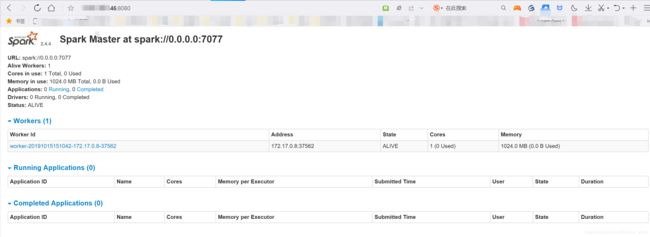
通过运行jps,可以看到worker和master已经运行起来了

通过8080端口,可以看到spark已经运行起来
运行Java客户端程序,这个Java客户端程序仅仅是统计字数,并且要上传到服务端运行,如果你的服务端是linux,而这个客户端跑在windows端,没有什么用。
具体统计结果生成路径:cd /usr/local/data1 查看我的统计结果:cat part-00000
Maven项目中的Java客户端代码(下面是摘抄https://blog.csdn.net/youbitch1的代码),具体Maven项目自己使用Eclipse搞定
package web;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.*;
import java.util.regex.Pattern;
/**
* Created by 張燿峰
* wordcount案例测试
* @author 孤
* @date 2019/3/11
* @Varsion 1.0
*/
public class SparkApplication {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("sparkBoot").setMaster("spark://122.51.56.146:7077");
JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);
//在Linux服务端运行改成/opt/***
JavaRDD
lines.map(new Function
@Override
public Object call(String s) {
return s;
}
});
JavaRDD
@Override
public Iterator
return Arrays.asList(SPACE.split(s)).iterator();
}
});
JavaPairRDD
@Override
public Tuple2
return new Tuple2
}
});
JavaPairRDD
@Override
public Integer call(Integer value, Integer toValue) {
return value + toValue;
}
});
//在Linux服务端运行改成/opt/***
wordsCounts.saveAsTextFile("D:\\spark\\spark-2.4.4-bin-hadoop2.7\\READX.md");
}
}
pom.xml必须如下表示:
FAQ:如果不按照上面的操作,会有下面两个问题:
1.java.io.InvalidClassException: org.apache.spark.rpc.netty.NettyRpcEndpointRef; local class incompatible: stream classdesc serialVersionUID = -4186747031772874359, local class serialVersionUID = 6257082371135760434
这个异常是版本不对,具体查看pom.xml文档配置,必须是core_2.1.1
2.必须设置export SPARK_MASTER_HOST=0.0.0.0参数,否则运行start-all.sh会报
org.apache.spark.SparkException: Invalid master URL: spark://VM_0_8_centos:7077