此作业的要求参见[https://edu.cnblogs.com/campus/nenu/2019fall/homework/6583]
代码地址[https://e.coding.net/gitli/cihuitongji1.git]
词频统计 SPEC
一、项目的重难点
(1)功能1文件的读取
我使用的c语言进行编写,之前没做过读入文件的题目,在网上查了一些相关资料以及一些语句的编写,使用的fopen方法。
主要代码:
in = fopen("book.txt","r");
(2)功能2主要代码
FILE *in,*out; int i,l,j,z; in = fopen("book.txt","r"); out = fopen("books.txt","w"); l = fread(s,1,7000010,in); for (i = 0; i < l; ++i) s[i] = tolower(s[i])-'a'; tot = i = 0;
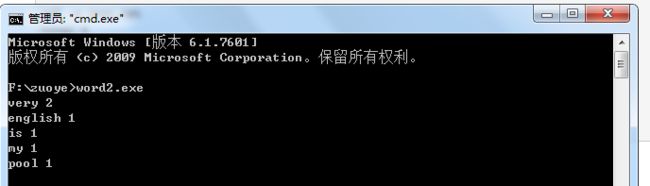
(3)功能3主要代码
FILE *in,*out; int i,l,j,z; in = fopen("book.txt","r"); out = fopen("books.txt","w"); l = fread(s,1,7000010,in); for (i = 0; i < l; ++i) s[i] = tolower(s[i])-'a'; tot = i = 0; while (i < l) { p = 0 ; while (find(s[i])) { if (!b[p][s[i]]) b[p][s[i]] = (++tot); p = b[p][s[i]]; i++; } num[p]++; i++; } n = 0; num[0] = 0; dfs(0,0);//深度搜索函数 for (i = 60000; i >= 1; --i) for (j = first[i]; j != 0; j = next[j]) fprintf(out,"%s %d\n",x[j],i); z = 0; for (i = 60000; i >= 1; --i) for (j = first[i]; j != 0 && z < 100; j = next[j]) { printf("%s %d\n",x[j],i); z++; }

(4)功能4主要代码
int main(int argc, const char * argv[]) { FILE *in,*out; int i,l,j,z; in = fopen("book123.txt","r"); out = fopen("books.txt","w"); l = fread(s,1,7000010,in); for (i = 0; i < l; ++i) s[i] = tolower(s[i])-'a'; tot = i = 0; while (i < l) { p = 0 ; while (find(s[i])) { if (!b[p][s[i]]) b[p][s[i]] = (++tot); p = b[p][s[i]]; i++; } num[p]++; i++; } n = 0; num[0] = 0; dfs(0,0);//深度搜索函数 for (i = 60000; i >= 1; --i) for (j = first[i]; j != 0; j = next[j]) fprintf(out,"%s %d\n",x[j],i); z = 0; for (i = 60000; i >= 1; --i) for (j = first[i]; j != 0 && z < 100; j = next[j]) { printf("%s %d\n",x[j],i); z++; }
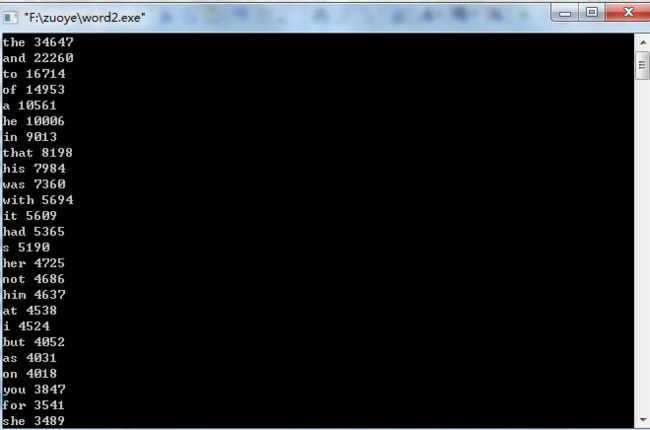
总结:
之前没有做过类似的题目,本来想用Python写的,但是现学一门语言感觉会做不完作业,所以选择了C语言。对于文本的读入我想到的是直接用fopen方法,可以直接进行文本的读取。统计每个词汇出现的次数时要把存放词汇的数组设置的足够大,要不很容易运行不出结果。但是功能中所说的在命令行输入存储有英文作品文件的目录名,批量统计还有不重复的统计出单词的数量,我在网上查找了相关知识以及博客,实在没有看懂,对我来说太难了。在编写的过程中出现了很多的错误,也看出自己的编程基础是十分薄弱,有难度的题目就无从下手,接下来要一步一步的学习Python这门语言,希望能在这门语言中找到这道题目的答案。
二、PSP
| PSP阶段 | 预计花费时间(min) | 实际花费时间(min) |
分析时差原因 |
| 功能一实现 |
60 | 170 | 对于文本读入方法,词汇统计的方法不熟悉,不知道如何运用。 |
| 功能一测试 | 30 | 60 | 文本的存放路径不对,存放词汇的数组大不准确,语法上的问题 |
| 功能二实现 | 80 | 160 | 词汇量增多,需要统计不重复词汇数量,命令行输入英文作品的文件名没有实现,尝试了很多办法都没有成功 |
| 功能二测试 | 30 | 40 | 能实现词汇出现次数的统计,但是有些功能实现不了 |
| 功能三实现 | 90 | 75 | 命令行输入英文作品的文件名没有实现,导致命令行输入存储有英文作品文件的目录名,批量统计也没有实现查阅的博客还是没弄懂 |
| 功能四实现 | 100 | 120 | 根据理解编写的程序只能直接打开文件进行词汇的统计,无法从命令行存储作品名 |