PostgreSQL V10 分区表特性
分区表特性是PG10新加的一个很重要的特性。
之前的版本也能实现分区表功能,但基本是根据“继承表+约束+规则或触发器”实现。
相对于之前的分区实现方式,PG10的分区特性有以下优势:
1)管理分区方便
2)数据插入效率高
事实上,PG10的分区特性也是在内置继承表的基础上实现的,所以创建的分区实质上也是普通的表结构。
目前PG10支持范围分区和列表分区,哈希分区还不支持。
范围分区:
PG10的分区表在建表语法上,主表和分区是单独创建的。下面的列表分区也是一样。
创建主表语法:
CREATE TABLE 表名 ( [{ 列名称 数据_类型} [, … ] ] )
PARTITION BY RANGE ( [{ 列名称 } [, …] ] );
范围分区的KEY值可由多个字段组成(最多32个字段)。
创建分区语法:
CREATE TABLE 表名 PARTITION OF 主表 FOR VALUES
FROM{ ( 表达式 [, …] ) | MINVALUE } [, …]
TO { ( 表达式 [, …] ) | MAXVALUE } [, …] [ TABLESPACE 表空间名 ];
参数说明:
// FROM … TO 表示分区的起始值和结束值。
// MINVALUE / MAXVALUE 表示无限小值和无限大值。
// 默认FROM后面的值是包括值分区的约束内,TO后面的值不包括。
示例:
postgres=# create table test(n int) partition by range(n);
CREATE TABLE
postgres=# create table test_1 partition of test for values from (MINVALUE) to (10);
CREATE TABLE
postgres=# create table test_2 partition of test for values from (10) to (100);
CREATE TABLE
postgres=# create table test_3 partition of test for values from (100) to (1000);
CREATE TABLE
postgres=# create table test_4 partition of test for values from (1000) to (10000);
CREATE TABLE
postgres=# \d+ test
Table "public.test"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Descrip
tion
--------+---------+-----------+----------+---------+---------+--------------+--------
-----
n | integer | | | | plain | |
Partition key: RANGE (n)
Partitions: test_1 FOR VALUES FROM (MINVALUE) TO (10),
test_2 FOR VALUES FROM (10) TO (100),
test_3 FOR VALUES FROM (100) TO (1000),
test_4 FOR VALUES FROM (1000) TO (10000)
postgres=# \d+ test_2
Table "public.test_2"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Descrip
tion
--------+---------+-----------+----------+---------+---------+--------------+--------
-----
n | integer | | | | plain | |
Partition of: test FOR VALUES FROM (10) TO (100)
Partition constraint: ((n IS NOT NULL) AND (n >= 10) AND (n < 100))
postgres=# insert into test select generate_series(0, 9999);INSERT 0 10000
postgres=# explain analyze select * from test;
QUERY PLAN
-------------------------------------------------------------------------------------
--------------------------
Append (cost=0.00..248.50 rows=17850 width=4) (actual time=0.010..11.248 rows=10000
loops=1)
-> Seq Scan on test_1 (cost=0.00..35.50 rows=2550 width=4) (actual time=0.009..0
.014 rows=10 loops=1)
-> Seq Scan on test_2 (cost=0.00..35.50 rows=2550 width=4) (actual time=0.012..0
.044 rows=90 loops=1)
-> Seq Scan on test_3 (cost=0.00..35.50 rows=2550 width=4) (actual time=0.025..0
.441 rows=900 loops=1)
-> Seq Scan on test_4 (cost=0.00..142.00 rows=10200 width=4) (actual time=0.026.
.4.317 rows=9000 loops=1)
Planning time: 0.248 ms
Execution time: 14.503 ms
(7 rows)列表分区:
列表的KEY只支持一个字段。
创建主表语法:
CREATE TABLE 表名 ( [{ 列名称 数据_类型} [, … ] ] )
PARTITION BY LIST( { 列名称 } );
创建分区语法:
CREATE TABLE 表名 PARTITION OF 主表 FOR VALUES
IN ( 表达式 [, …] ) [ TABLESPACE 表空间名 ];
示例:
postgres=# CREATE TABLE sales (product_id int, saleroom int, province text) PARTITION BY LIST(province);
CREATE TABLE
postgres=# CREATE TABLE sales_east PARTITION OF sales FOR VALUES IN ('山东','江苏',' 上海');
CREATE TABLE
postgres=# CREATE TABLE sales_west PARTITION OF sales FOR VALUES IN ('山西','陕西',' 四川');
CREATE TABLE
postgres=# CREATE TABLE sales_north PARTITION OF sales FOR VALUES IN ('北京','河北','辽宁');
CREATE TABLE
postgres=# CREATE TABLE sales_south PARTITION OF sales FOR VALUES IN ('广东','福建');CREATE TABLE
postgres=# \d+ sales
Table "public.sales"
Column | Type | Collation | Nullable | Default | Storage | Stats target | De
scription
------------+---------+-----------+----------+---------+----------+--------------+---
----------
product_id | integer | | | | plain | |
saleroom | integer | | | | plain | |
province | text | | | | extended | |
Partition key: LIST (province)
Partitions: sales_east FOR VALUES IN ('山东', '江苏', '上海'),
sales_north FOR VALUES IN ('北京', '河北', '辽宁'),
sales_south FOR VALUES IN ('广东', '福建'),
sales_west FOR VALUES IN ('山西', '陕西', '四川')
postgres=# \d+ sales_east
Table "public.sales_east"
Column | Type | Collation | Nullable | Default | Storage | Stats target | De
scription
------------+---------+-----------+----------+---------+----------+--------------+---
----------
product_id | integer | | | | plain | |
saleroom | integer | | | | plain | |
province | text | | | | extended | |
Partition of: sales FOR VALUES IN ('山东', '江苏', '上海')
Partition constraint: ((province IS NOT NULL) AND (province = ANY (ARRAY['山东'::text, '江苏'::text, '上海'::text])))
postgres=# insert into sales values (1001, 2345234, '山东');
INSERT 0 1
postgres=# insert into sales values (1002, 23233, '河北');
INSERT 0 1
postgres=# insert into sales values (1001, 4357233, '广东');
INSERT 0 1
postgres=# insert into sales values (1002, 67233, '陕西');
INSERT 0 1
postgres=# explain analyze select * from sales;
QUERY PLAN
-------------------------------------------------------------------------------------
---------------------------
Append (cost=0.00..88.00 rows=4800 width=40) (actual time=0.009..0.023 rows=4 loops
=1)
-> Seq Scan on sales_east (cost=0.00..22.00 rows=1200 width=40) (actual time=0.0
08..0.009 rows=1 loops=1)
-> Seq Scan on sales_west (cost=0.00..22.00 rows=1200 width=40) (actual time=0.0
03..0.003 rows=1 loops=1)
-> Seq Scan on sales_north (cost=0.00..22.00 rows=1200 width=40) (actual time=0.
003..0.003 rows=1 loops=1)
-> Seq Scan on sales_south (cost=0.00..22.00 rows=1200 width=40) (actual time=0.
002..0.003 rows=1 loops=1)
Planning time: 0.305 ms
Execution time: 0.054 ms
(7 rows)获取系统信息(系统表):
pg_partitioned_table 记录主表信息的系统表:
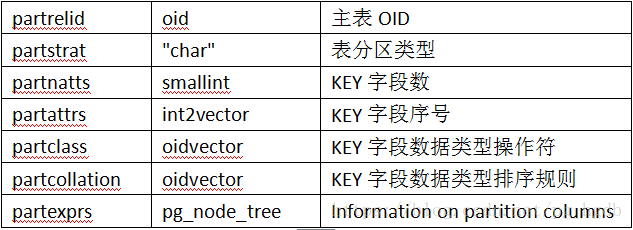
分区的信息记录在pg_class相关的字段中:

获取系统信息(分区函数):
pg_get_partkeydef (Oid relid) – 根据主表OID返回分区类型及KEY:
postgres=# select pg_get_partkeydef('test'::regclass);
pg_get_partkeydef
-------------------
RANGE (n)
(1 row)
pg_get_partition_constraintdef (Oid relid) -- 根据分区OID获取分区约束条件:
postgres=# select pg_get_partition_constraintdef('test_1'::regclass);
pg_get_partition_constraintdef
--------------------------------
((n IS NOT NULL) AND (n < 10))
(1 row)其他操作—ATTACH操作:
ATTACH操作是把和主表有相同表结构的主表变成该主表的一个分区:
范围分区:
ALTER TABLE 主表名 ATTACH PARTITION 表名 FOR VALUES
FROM{ ( 表达式 [, …] ) | MINVALUE } [, …]
TO { ( 表达式 [, …] ) | MAXVALUE } [, …];
列表分区:
ALTER TABLE 主表名 ATTACH PARTITION 表名 FOR VALUES
IN ( 表达式 [, …] );
示例:
范围分区:
postgres=# create table test_attach(like test);
CREATE TABLE
postgres=# alter table test attach partition test_attach for values from (10000) to (MAXVALUE);
ALTER TABLE
\d+ test
列表分区:
postgres=# CREATE TABLE sales_foreign (like sales) ;
CREATE TABLE
postgres=# ALTER TABLE sales ATTACH PARTITION sales_foreign FOR VALUES IN('美国','日本');
ALTER TABLE在对普通表进行ATTACH操作时,如果该普通表中有数据,则表中的数据会进行校验是否符合约束条件。
其他操作—DETACH操作:
DETACH操作是把主表的分区变成普通表,是ATTACH的反操作:
语法:
ALTER TABLE 主表名 DETACH PARTITION 分区名;
示例:
范围分区:
postgres=# alter table test detach partition test_attach;
ALTER TABLE
列表分区:
postgres=# alter table sales detach partition sales_foreign;
ALTER TABLE分区和约束排除:
约束排除(Constraint exclusive)是一种查询优化技术,在应用在分区特性中,可以提高分区表检索性能,这也是使用分区特性关键的一点。
排除约束在系统中可以设置开启或关闭,使用参数constraint_exclusion进行设置。
注:constraint_exclusion的默认值是partition,是介于off和on之间的一个中间值,用来只对继承表和分区表做检查约束,on是对所有的表做检查约束,off是不做检查约束。
在PG10中,使用分区表一定不要禁用constraint_exclusion,否则分区将失去其意义。
以上内容由瀚高研发中心 王好燕 提供,在此表示感谢!
by boluo