- Kubernetes集群版本升级
程序员Realeo
Java后端kubernetes容器云原生
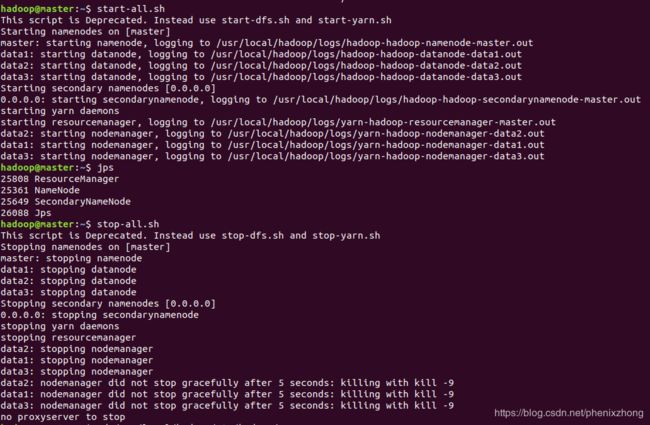
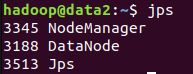
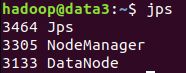
集群升级注意事项升级集群版本建议逐步升级,比如v1.20.1–>v1.21.1–>v1.22.1–>v1.23.1–>v1.24.1,不能跨度过大,否则会报错。升级步骤查看集群版本[root@hadoop102~]#kubectlgetnodesNAMESTATUSROLESAGEVERSIONhadoop102Ready,SchedulingDisabledcontrol-plane,maste
- Kubernetes集群版本升级
后端java
集群升级注意事项升级集群版本建议逐步升级,比如v1.20.1–>v1.21.1–>v1.22.1–>v1.23.1–>v1.24.1,不能跨度过大,否则会报错。升级步骤查看集群版本[root@hadoop102~]#kubectlgetnodesNAMESTATUSROLESAGEVERSIONhadoop102Ready,SchedulingDisabledcontrol-plane,maste
- Hive高级SQL技巧及实际应用场景
小技工丨
大数据随笔sqlhive数据仓库大数据
Hive高级SQL技巧及实际应用场景引言ApacheHive是一个建立在Hadoop之上的数据仓库基础设施,它提供了一个用于查询和管理分布式存储中的大型数据集的机制。通过使用类似于SQL(称为HiveQL)的语言,Hive使得数据分析变得更加简单和高效。本文将详细探讨一些Hive高级SQL技巧,并结合实际的应用场景进行说明。HiveSQL的高级使用技巧1.窗口函数描述:窗口函数允许我们在不使用GR
- hive 数字转换字符串_Hive架构及Hive SQL的执行流程解读
weixin_39756416
hive数字转换字符串
1、Hive产生背景MapReduce编程的不便性HDFS上的文件缺少Schema(表名,名称,ID等,为数据库对象的集合)2、Hive是什么Hive的使用场景是什么?基于Hadoop做一些数据清洗啊(ETL)、报表啊、数据分析可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。Hive是SQL解析引擎,它将SQL语句转译成M/RJob然后在Hadoop执行。由Facebook开源,
- 在hadoop上运行python_hadoop上运行python程序
廷哥带你小路超车
数据来源:http://www.nber.org/patents/acite75_99.zip首先上传测试数据到hdfs:[root@localhost:/usr/local/hadoop/hadoop-0.19.2]#bin/hadoopfs-ls/user/root/test-inFound5items-rw-r--r--1rootsupergroup1012010-10-2414:39/us
- ranger集成starrock报错
蘑菇丁
大数据+机器学习+oracle大数据
org.apache.ranger.plugin.client.HadoopException:initConnection:UnabletoconnecttoStarRocksinstance,pleaseprovidevalidvalueoffield:{jdbc.driverClassName}..com.mysql.cj.jdbc.Driver.可能的原因JDBC驱动缺失:运行环境中没有安
- 深入大数据世界:Kontext.TECH的Hadoop之旅
钱桦实Emery
深入大数据世界:Kontext.TECH的Hadoop之旅winutils项目地址:https://gitcode.com/gh_mirrors/winut/winutils在大数据的浩瀚宇宙中,Hadoop作为一颗璀璨的星辰,一直扮演着至关重要的角色。对于渴望探索这一领域的开发者和学习者而言,Kontext.TECH提供了一扇独特而便捷的大门,让你的学习之旅更加顺畅。项目介绍Kontext.Ha
- 大数据学习(61)-Impala与Hive计算引擎
viperrrrrrr
学习impalahiveyarnhadoop
&&大数据学习&&系列专栏:哲学语录:承认自己的无知,乃是开启智慧的大门如果觉得博主的文章还不错的话,请点赞+收藏⭐️+留言支持一下博主哦一、impala与yarn资源管理YARN是ApacheHadoop生态系统中的一个资源管理器,它采用了master/slave的架构,使得多个处理框架能够在同一集群上共享资源。Impala作为Hadoop生态系统中的一个组件,可以与YARN集成,以便更好地管理
- 大数据学习(62)- Hadoop-yarn
viperrrrrrr
大数据yarn
&&大数据学习&&系列专栏:哲学语录:承认自己的无知,乃是开启智慧的大门如果觉得博主的文章还不错的话,请点赞+收藏⭐️+留言支持一下博主哦一、YARN概述1.YARN简介Hadoop-YARN是ApacheHadoop生态系统中的一个集群资源管理器。它作为Hadoop的第二代资源管理框架,负责管理和分配集群中的计算资源。YARN的设计目标是提供一个通用的资源管理框架,使得Hadoop集群可以同时运
- HBase2.6.1部署文档
CXH728
zookeeperhbase
1、HBase概述ApacheHBase是基于Hadoop分布式文件系统(HDFS)之上的分布式、列存储、NoSQL数据库。它适合处理结构化和半结构化数据,能够存储数十亿行和数百万列的数据,并支持实时读写操作。HBase通常应用于需要快速随机读写、低延迟访问以及高吞吐量的场景,例如大规模日志处理、社交网络数据存储等。HBase特性列存储模型:HBase的数据是按列族存储的,适合高稀疏数据。行键分区
- Hive-4.0.1版本部署文档
CXH728
hivehadoop数据仓库
1.前置要求操作系统:建议使用CentOS7或Ubuntu20.04(本试验使用的是CentOSLinuxrelease7.9.2009(Core))Java环境:建议安装Java8或更高版本。Hadoop:Hive需要依赖Hadoop进行分布式存储,建议安装Hadoop3.x版本(本实验采用的是hadoop3.3.6)。数据库:HiveMetastore需要数据库支持,建议使用MySQL、Pos
- hive-3.1.3部署文档
CXH728
hivehadoop数据仓库
提前准备一个正常运行的hadoop集群java环境hive安装包下载地址:https://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gzmysql安装包1、内嵌模式由于内嵌模式使用场景太少(基本不用),所以仅练习安装查看基础功能[root@master~]#tarxfapache-hive-3.1.3-bin
- mySQL和Hive的区别
iijik55
面试学习路线阿里巴巴hivemysql大数据tomcat面试
SQL和HQL的区别整体1、存储位置:Hive在Hadoop上;Mysql将数据存储在设备或本地系统中;2、数据更新:Hive不支持数据的改写和添加,是在加载的时候就已经确定好了;数据库可以CRUD;3、索引:Hive无索引,每次扫描所有数据,底层是MR,并行计算,适用于大数据量;MySQL有索引,适合在线查询数据;4、执行:Hive底层是MapReduce;MySQL底层是执行引擎;5、可扩展性
- flink-cdc实时增量同步mysql数据到elasticsearch
大数据技术派
#Flinkelasticsearchflinkmysql
什么是CDC?CDC是(ChangeDataCapture变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入INSERT、更新UPDATE、删除DELETE等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。1.环境准备mysqlelasticsearchflinkonyarn说明:如果没有安装hadoop,那么可以不用yarn,直
- 搭建分布式Hive集群
逸曦玥泱
大数据运维分布式hivehadoop
title:搭建分布式Hive集群date:2024-11-2923:39:00categories:-服务器tags:-Hive-大数据搭建分布式Hive集群本次实验环境:Centos7-2009、Hadoop-3.1.4、JDK8、Zookeeper-3.6.3、Mysql-5.7.38、Hive-3.1.2功能规划方案一(本地运行模式)Master主节点(Mysql+Hive)192.168
- Hadoop、Spark和 Hive 的详细关系
夜行容忍
hadoopsparkhive
Hadoop、Spark和Hive的详细关系1.ApacheHadoopHadoop是一个开源框架,用于分布式存储和处理大规模数据集。核心组件:HDFS(HadoopDistributedFileSystem):分布式文件系统,提供高吞吐量的数据访问。YARN(YetAnotherResourceNegotiator):集群资源管理和作业调度系统。MapReduce:基于YARN的并行处理框架,用
- Windows系统下解压".tar"文件出错,提示:无法创建符号链接,可能需要以管理器身份运行winrar
ruangaoyan
1、解压文件出错,如下信息:D:\tools\hadoop-3.1.2.tar.gz:无法创建符号链接D:\tools\hadoop-3.1.2\hadoop-3.1.2\lib\native\libhadoop.so您可能需要以管理器身份运行WinRAR!客户端没有所需的特权。2、解决方式如下:WIN+R快捷的打开命令窗口,输入CMD输入:cd/dD:\tools\hadoop-3.1.2这是我
- 大数据技术生态圈:Hadoop、Hive、Spark的区别和关系
雨中徜徉的思绪漫溢
大数据hadoophive
大数据技术生态圈:Hadoop、Hive、Spark的区别和关系在大数据领域中,Hadoop、Hive和Spark是三个常用的开源技术,它们在大数据处理和分析方面发挥着重要作用。虽然它们都是为了处理大规模数据集而设计的,但它们在功能和使用方式上存在一些区别。本文将详细介绍Hadoop、Hive和Spark的区别和关系,并提供相应的源代码示例。Hadoop:Hadoop是一个用于分布式存储和处理大规
- ZooKeeper学习总结(1)——ZooKeeper入门介绍
一杯甜酒
ZooKeeper学习总结Zookeeper
1.概述Zookeeper是Hadoop的一个子项目,它是分布式系统中的协调系统,可提供的服务主要有:配置服务、名字服务、分布式同步、组服务等。它有如下的一些特点:简单Zookeeper的核心是一个精简的文件系统,它支持一些简单的操作和一些抽象操作,例如,排序和通知。丰富Zookeeper的原语操作是很丰富的,可实现一些协调数据结构和协议。例如,分布式队列、分布式锁和一组同级别节点中的“领导者选举
- Zookeeper+kafka学习笔记
CHR_YTU
Zookeeper
Zookeeper是Apache的一个java项目,属于Hadoop系统,扮演管理员的角色。配置管理分布式系统都有好多机器,比如我在搭建hadoop的HDFS的时候,需要在一个主机器上(Master节点)配置好HDFS需要的各种配置文件,然后通过scp命令把这些配置文件拷贝到其他节点上,这样各个机器拿到的配置信息是一致的,才能成功运行起来HDFS服务。Zookeeper提供了这样的一种服务:一种集
- 麒麟arm架构系统_安装nginx-1.27.0_访问500 internal server error nginx解决_13: Permission denied---Linux工作笔记072
添柴程序猿
javanginx-1.27.0nginx最新版安装麒麟v10arm架构麒麟v10安装nginx
[
[email protected]]#wget-chttp://nginx.org/download/nginx-1.27.0.tar.gz--2024-07-0509:47:00--http://nginx.org/download/nginx-1.27.0.tar.gzResolvingnginx.org(nginx.org)...3.125.197.172,52.58.19
- Zookeeper与Kafka学习笔记
上海研博数据
zookeeperkafka学习
一、Zookeeper核心要点1.核心特性分布式协调服务,用于维护配置/命名/同步等元数据采用层次化数据模型(Znode树结构),每个节点可存储<1MB数据典型应用场景:HadoopNameNode高可用HBase元数据管理Kafka集群选举与状态管理2.设计限制内存型存储,不适合大数据量场景数据变更通过版本号(Version)控制,实现乐观锁机制采用ZAB协议保证数据一致性二、Kafka核心架构
- phoenix无法连接hbase shell创建表失败_报错_PleaseHoldException: Master is initializing---记录020_大数据工作笔记0180
添柴程序猿
hbase连接报错phoenix连接hbasephoenixPleaseHoldExcep
今天发现,我的phoenix,去连接hbase集群,怎么也连不上了,奇怪了...弄了一晚上org.apache.hadoop.hbase.PleaseHoldException:Masterisinitializing[root@hadoop120bin]#ll总用量184-rwxr-xr-x.1rootroot36371月222020chaos-daemon.sh-rwxr-xr-x.1root
- Hadoop的运行模式
对许
#Hadoophadoop大数据分布式
Hadoop的运行模式1、本地运行模式2、伪分布式运行模式3、完全分布式运行模式4、区别与总结Hadoop有三种可以运行的模式:本地运行模式、伪分布式运行模式和完全分布式运行模式1、本地运行模式本地运行模式无需任何守护进程,单机运行,所有的程序都运行在同一个JVM上执行Hadoop安装后默认为本地模式,数据存储在Linux本地。在本地模式下调试MapReduce程序非常高效方便,一般该模式主要是在
- Hadoop的mapreduce的执行过程
画纸仁
大数据hadoopmapreduce大数据
一、map阶段的执行过程第一阶段:把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。默认Splitsize=Blocksize(128M),每一个切片由一个MapTask处理。(getSplits)第二阶段:对切片中的数据按照一定的规则读取解析返回对。默认是按行读取数据。key是每一行的起始位置偏移量,value是本行的文本内容。(TextInputFormat)第三阶段:调用Mapp
- Hadoop:分布式计算平台初探
dccrtbn6261333
大数据运维java
Hadoop是一个开发和运行处理大规模数据的软件平台,是Apache的一个用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算。Hadoop框架中最核心设计就是:MapReduce和HDFS。MapReduce提供了对数据的计算,HDFS提供了海量数据的存储。MapReduceMapReduce的思想是由Google的一篇论文所提及而被广为流传的,简单的一句话解释M
- 【Hadoop】如何理解MapReduce?
2302_79952574
hadoopmapreduce数据库
MapReduce是一种用于处理大规模数据集的编程模型和计算框架。它的核心思想是将复杂的计算任务分解为两个简单的阶段:Map(映射)和Reduce(归约)。通过这种方式,MapReduce可以高效地并行处理海量数据。一.MapReduce的核心概念1.Map(映射):将输入数据分割成小块,并对每个小块进行初步处理。输出键值对(key-valuepairs),例如。2.Shuffle和Sort(洗牌
- Hadoop:全面深入解析
CloudJourney
hadoop大数据分布式
Hadoop是一个用于大规模数据处理的开源框架,其设计旨在通过集群的方式进行分布式存储和计算。本篇博文将从Hadoop的定义、架构、原理、应用场景以及常见命令等多个方面进行详细探讨,帮助读者全面深入地了解Hadoop。1.Hadoop的定义1.1什么是HadoopHadoop是由Apache软件基金会开发的开源软件框架,用于存储和处理大规模数据。其核心组件包括Hadoop分布式文件系统(HDFS)
- Hadoop介绍:什么是Hadoop?了解Hadoop的应用
Zzzxt007
hadoop大数据分布式
一、认识Hadoop框架Hadoop是一个提供分布式存储和计算的开源软件框架,使用Java语言编写,具有高扩展性、高容错性、无共享和高可用(HA)等特点,非常适合处理海量数据。它基于Google发布的MapReduce论文实现,并且应用了函数式编程的思想。Hadoop框架主要包括HDFS(HadoopDistributedFileSystem,Hadoop分布式文件系统)、MapReduce、YA
- Hbase在hdfs上的archive目录占用空间过大
宝罗Paul
大数据hbase
hbase版本:1.1.2hadoop版本:2.7.3Hbase在hdfs上的目录/apps/hbase/data/archive占用空间过大,导致不停地发出hdfs空间使用率告警。【问题】告警信息alert:datanode_storageistriggered告警信息表明某个或某些datanode的HDFS存储空间使用率已超过阈值(我们设置的是80%),需要清理。[hdfs@master-2r
- 对于规范和实现,你会混淆吗?
yangshangchuan
HotSpot
昨晚和朋友聊天,喝了点咖啡,由于我经常喝茶,很长时间没喝咖啡了,所以失眠了,于是起床读JVM规范,读完后在朋友圈发了一条信息:
JVM Run-Time Data Areas:The Java Virtual Machine defines various run-time data areas that are used during execution of a program. So
- android 网络
百合不是茶
网络
android的网络编程和java的一样没什么好分析的都是一些死的照着写就可以了,所以记录下来 方便查找 , 服务器使用的是TomCat
服务器代码; servlet的使用需要在xml中注册
package servlet;
import java.io.IOException;
import java.util.Arr
- [读书笔记]读法拉第传
comsci
读书笔记
1831年的时候,一年可以赚到1000英镑的人..应该很少的...
要成为一个科学家,没有足够的资金支持,很多实验都无法完成
但是当钱赚够了以后....就不能够一直在商业和市场中徘徊......
- 随机数的产生
沐刃青蛟
随机数
c++中阐述随机数的方法有两种:
一是产生假随机数(不管操作多少次,所产生的数都不会改变)
这类随机数是使用了默认的种子值产生的,所以每次都是一样的。
//默认种子
for (int i = 0; i < 5; i++)
{
cout<<
- PHP检测函数所在的文件名
IT独行者
PHP函数
很简单的功能,用到PHP中的反射机制,具体使用的是ReflectionFunction类,可以获取指定函数所在PHP脚本中的具体位置。 创建引用脚本。
代码:
[php]
view plain
copy
// Filename: functions.php
<?php&nbs
- 银行各系统功能简介
文强chu
金融
银行各系统功能简介 业务系统 核心业务系统 业务功能包括:总账管理、卡系统管理、客户信息管理、额度控管、存款、贷款、资金业务、国际结算、支付结算、对外接口等 清分清算系统 以清算日期为准,将账务类交易、非账务类交易的手续费、代理费、网络服务费等相关费用,按费用类型计算应收、应付金额,经过清算人员确认后上送核心系统完成结算的过程 国际结算系
- Python学习1(pip django 安装以及第一个project)
小桔子
pythondjangopip
最近开始学习python,要安装个pip的工具。听说这个工具很强大,安装了它,在安装第三方工具的话so easy!然后也下载了,按照别人给的教程开始安装,奶奶的怎么也安装不上!
第一步:官方下载pip-1.5.6.tar.gz, https://pypi.python.org/pypi/pip easy!
第二部:解压这个压缩文件,会看到一个setup.p
- php 数组
aichenglong
PHP排序数组循环多维数组
1 php中的创建数组
$product = array('tires','oil','spark');//array()实际上是语言结构而不 是函数
2 如果需要创建一个升序的排列的数字保存在一个数组中,可以使用range()函数来自动创建数组
$numbers=range(1,10)//1 2 3 4 5 6 7 8 9 10
$numbers=range(1,10,
- 安装python2.7
AILIKES
python
安装python2.7
1、下载可从 http://www.python.org/进行下载#wget https://www.python.org/ftp/python/2.7.10/Python-2.7.10.tgz
2、复制解压
#mkdir -p /opt/usr/python
#cp /opt/soft/Python-2
- java异常的处理探讨
百合不是茶
JAVA异常
//java异常
/*
1,了解java 中的异常处理机制,有三种操作
a,声明异常
b,抛出异常
c,捕获异常
2,学会使用try-catch-finally来处理异常
3,学会如何声明异常和抛出异常
4,学会创建自己的异常
*/
//2,学会使用try-catch-finally来处理异常
- getElementsByName实例
bijian1013
element
实例1:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/x
- 探索JUnit4扩展:Runner
bijian1013
java单元测试JUnit
参加敏捷培训时,教练提到Junit4的Runner和Rule,于是特上网查一下,发现很多都讲的太理论,或者是举的例子实在是太牵强。多搜索了几下,搜索到两篇我觉得写的非常好的文章。
文章地址:http://www.blogjava.net/jiangshachina/archive/20
- [MongoDB学习笔记二]MongoDB副本集
bit1129
mongodb
1. 副本集的特性
1)一台主服务器(Primary),多台从服务器(Secondary)
2)Primary挂了之后,从服务器自动完成从它们之中选举一台服务器作为主服务器,继续工作,这就解决了单点故障,因此,在这种情况下,MongoDB集群能够继续工作
3)挂了的主服务器恢复到集群中只能以Secondary服务器的角色加入进来
2
- 【Spark八十一】Hive in the spark assembly
bit1129
assembly
Spark SQL supports most commonly used features of HiveQL. However, different HiveQL statements are executed in different manners:
1. DDL statements (e.g. CREATE TABLE, DROP TABLE, etc.)
- Nginx问题定位之监控进程异常退出
ronin47
nginx在运行过程中是否稳定,是否有异常退出过?这里总结几项平时会用到的小技巧。
1. 在error.log中查看是否有signal项,如果有,看看signal是多少。
比如,这是一个异常退出的情况:
$grep signal error.log
2012/12/24 16:39:56 [alert] 13661#0: worker process 13666 exited on s
- No grammar constraints (DTD or XML schema).....两种解决方法
byalias
xml
方法一:常用方法 关闭XML验证
工具栏:windows => preferences => xml => xml files => validation => Indicate when no grammar is specified:选择Ignore即可。
方法二:(个人推荐)
添加 内容如下
<?xml version=
- Netty源码学习-DefaultChannelPipeline
bylijinnan
netty
package com.ljn.channel;
/**
* ChannelPipeline采用的是Intercepting Filter 模式
* 但由于用到两个双向链表和内部类,这个模式看起来不是那么明显,需要仔细查看调用过程才发现
*
* 下面对ChannelPipeline作一个模拟,只模拟关键代码:
*/
public class Pipeline {
- MYSQL数据库常用备份及恢复语句
chicony
mysql
备份MySQL数据库的命令,可以加选不同的参数选项来实现不同格式的要求。
mysqldump -h主机 -u用户名 -p密码 数据库名 > 文件
备份MySQL数据库为带删除表的格式,能够让该备份覆盖已有数据库而不需要手动删除原有数据库。
mysqldump -–add-drop-table -uusername -ppassword databasename > ba
- 小白谈谈云计算--基于Google三大论文
CrazyMizzz
Google云计算GFS
之前在没有接触到云计算之前,只是对云计算有一点点模糊的概念,觉得这是一个很高大上的东西,似乎离我们大一的还很远。后来有机会上了一节云计算的普及课程吧,并且在之前的一周里拜读了谷歌三大论文。不敢说理解,至少囫囵吞枣啃下了一大堆看不明白的理论。现在就简单聊聊我对于云计算的了解。
我先说说GFS
&n
- hadoop 平衡空间设置方法
daizj
hadoopbalancer
在hdfs-site.xml中增加设置balance的带宽,默认只有1M:
<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>10485760</value>
<description&g
- Eclipse程序员要掌握的常用快捷键
dcj3sjt126com
编程
判断一个人的编程水平,就看他用键盘多,还是鼠标多。用键盘一是为了输入代码(当然了,也包括注释),再有就是熟练使用快捷键。 曾有人在豆瓣评
《卓有成效的程序员》:“人有多大懒,才有多大闲”。之前我整理了一个
程序员图书列表,目的也就是通过读书,让程序员变懒。 程序员作为特殊的群体,有的人可以这么懒,懒到事情都交给机器去做,而有的人又可以那么勤奋,每天都孜孜不倦得
- Android学习之路
dcj3sjt126com
Android学习
转自:http://blog.csdn.net/ryantang03/article/details/6901459
以前有J2EE基础,接触JAVA也有两三年的时间了,上手Android并不困难,思维上稍微转变一下就可以很快适应。以前做的都是WEB项目,现今体验移动终端项目,让我越来越觉得移动互联网应用是未来的主宰。
下面说说我学习Android的感受,我学Android首先是看MARS的视
- java 遍历Map的四种方法
eksliang
javaHashMapjava 遍历Map的四种方法
转载请出自出处:
http://eksliang.iteye.com/blog/2059996
package com.ickes;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
/**
* 遍历Map的四种方式
- 【精典】数据库相关相关
gengzg
数据库
package C3P0;
import java.sql.Connection;
import java.sql.SQLException;
import java.beans.PropertyVetoException;
import com.mchange.v2.c3p0.ComboPooledDataSource;
public class DBPool{
- 自动补全
huyana_town
自动补全
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="http://www.w3.org/1999/xhtml&quo
- jquery在线预览PDF文件,打开PDF文件
天梯梦
jquery
最主要的是使用到了一个jquery的插件jquery.media.js,使用这个插件就很容易实现了。
核心代码
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.
- ViewPager刷新单个页面的方法
lovelease
androidviewpagertag刷新
使用ViewPager做滑动切换图片的效果时,如果图片是从网络下载的,那么再子线程中下载完图片时我们会使用handler通知UI线程,然后UI线程就可以调用mViewPager.getAdapter().notifyDataSetChanged()进行页面的刷新,但是viewpager不同于listview,你会发现单纯的调用notifyDataSetChanged()并不能刷新页面
- 利用按位取反(~)从复合枚举值里清除枚举值
草料场
enum
以 C# 中的 System.Drawing.FontStyle 为例。
如果需要同时有多种效果,
如:“粗体”和“下划线”的效果,可以用按位或(|)
FontStyle style = FontStyle.Bold | FontStyle.Underline;
如果需要去除 style 里的某一种效果,
- Linux系统新手学习的11点建议
刘星宇
编程工作linux脚本
随着Linux应用的扩展许多朋友开始接触Linux,根据学习Windwos的经验往往有一些茫然的感觉:不知从何处开始学起。这里介绍学习Linux的一些建议。
一、从基础开始:常常有些朋友在Linux论坛问一些问题,不过,其中大多数的问题都是很基础的。例如:为什么我使用一个命令的时候,系统告诉我找不到该目录,我要如何限制使用者的权限等问题,这些问题其实都不是很难的,只要了解了 Linu
- hibernate dao层应用之HibernateDaoSupport二次封装
wangzhezichuan
DAOHibernate
/**
* <p>方法描述:sql语句查询 返回List<Class> </p>
* <p>方法备注: Class 只能是自定义类 </p>
* @param calzz
* @param sql
* @return
* <p>创建人:王川</p>
* <p>创建时间:Jul