C++并发编程(C++11)
前言
首先需要说明,本博客的主要内容参考自Forhappy && Haippy博主的分享,本人主要是参照博主的资料进行了学习和总结,并适当的衍生或补充了相关的其他知识内容。
C++11有了std::thread 以后,可以在语言层面编写多线程程序了,直接的好处就是多线程程序的可移植性得到了很大的提高。
C++11 新标准中引入了四个头文件来支持多线程编程,他们分别是,,,和。
:该头文主要声明了两个类, std::atomic 和 std::atomic_flag,另外还声明了一套 C 风格的原子类型和与 C 兼容的原子操作的函数。
:该头文件主要声明了 std::thread 类,另外 std::this_thread 命名空间也在该头文件中。
:该头文件主要声明了与互斥量(mutex)相关的类,包括 std::mutex 系列类,std::lock_guard, std::unique_lock, 以及其他的类型和函数。
:该头文件主要声明了与条件变量相关的类,包括 std::condition_variable 和 std::condition_variable_any。
:该头文件主要声明了 std::promise, std::package_task 两个 Provider 类,以及 std::future 和 std::shared_future 两个 Future 类,另外还有一些与之相关的类型和函数,std::async() 函数就声明在此头文件中。
1. HelloWorld
#include
using namespace std;
void thread_task()
{
cout << "Hello World!" << std::endl;
}
int main(int argc, const char *argv[])
{
thread t(thread_task);
t.join();
system("pause");
return 0;
}
2. Thread Constructor
1)默认构造函数:thread() noexcept,创建一个空的 thread 执行对象。
2)初始化构造函数: template
#include 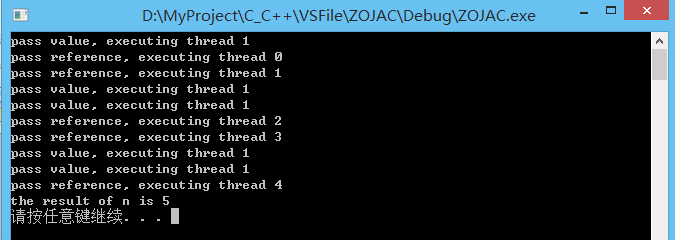
3. 赋值操作
1)move 赋值操作:thread& operator= (thread&& rhs) noexcept,如果当前对象不可 joinable,需要传递一个右值引用(rhs)给 move 赋值操作;如果当前对象可被 joinable,则 terminate() 报错。
2)拷贝赋值操作被禁用:thread& operator= (const thread&) = delete,thread 对象不可被拷贝。
#include
#include
#include
using namespace std;
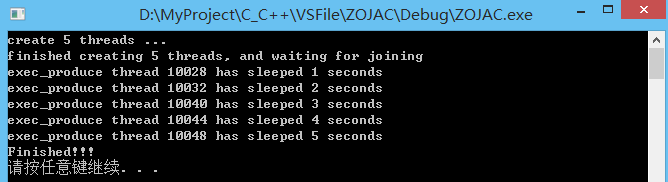
void exec_produce(int duration) {
//阻止线程运行到duration秒
this_thread::sleep_for(chrono::seconds(duration));
//this_thread::get_id()获取当前线程id
cout << "exec_produce thread " << this_thread::get_id()
<< " has sleeped " << duration << " seconds" << endl;
}
int main(int argc, const char *argv[])
{
thread threads[5];
cout << "create 5 threads ..." << endl;
for (int i = 0; i < 5; i++) {
threads[i] = thread(exec_produce, i + 1);
}
cout << "finished creating 5 threads, and waiting for joining" << endl;
//下面代码会报错,原因就是copy操作不可用,相当于是delete操作,所以报错
/*for(auto it : threads) {
it.join();
}*/
for (auto& it: threads) {
it.join();
}
cout << "Finished!!!" << endl;
system("pause");
return 0;
}
其他相关函数作用说明
1)get_id() 获取线程 ID。
2)joinable() 检查线程是否可被 join
3)join() Join 线程。
4)detach() Detach 线程
5)swap() Swap 线程
6)native_handle() 返回 native handle。
7)hardware_concurrency() 检测硬件并发特性
4. std::mutex
mutex 又称互斥量,C++ 11中与 mutex 相关的类(包括锁类型)和函数都声明在 头文件中,所以如果需要使用 std::mutex,就必须包含 头文件,mutex中包含以下:
mutex系列类
std::mutex,最基本的 mutex类
std::recursive_mutex,递归 mutex类
std::time_mutex,定时 mutex类。
std::recursive_timed_mutex,定时递归 mutex类
lock 类
std::lock_guard,与 mutex RAII 相关,方便线程对互斥量上锁
std::unique_lock,与 mutex RAII 相关,方便线程对互斥量上锁,但提供了更好的上锁和解锁控制
其他类型
std::once_flag
std::adopt_lock_t
std::defer_lock_t
std::try_to_lock_t
函数
std::try_lock(),尝试同时对多个互斥量上锁。
std::lock(),可以同时对多个互斥量上锁。
std::call_once(),如果多个线程需要同时调用某个函数,call_once 可以保证多个线程对该函数只调用一次。
(1)std::mutex
std::mutex 是C++11 中最基本的互斥量,std::mutex 对象提供了独占所有权的特性——即不支持递归地对 std::mutex 对象上锁,而 std::recursive_lock 则可以递归地对互斥量对象上锁。
std::mutex 的成员函数
1)构造函数,std::mutex不允许拷贝构造,也不允许 move 拷贝,最初产生的 mutex 对象是处于 unlocked 状态的。
2)lock(),调用线程将锁住该互斥量。线程调用该函数会发生下面 3 种情况:(1). 如果该互斥量当前没有被锁住,则调用线程将该互斥量锁住,直到调用 unlock之前,该线程一直拥有该锁。(2). 如果当前互斥量被其他线程锁住,则当前的调用线程被阻塞住。(3). 如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)。
3)unlock(), 解锁,释放对互斥量的所有权。
4)try_lock(),尝试锁住互斥量,如果互斥量被其他线程占有,则当前线程也不会被阻塞。线程调用该函数也会出现下面 3 种情况,(1). 如果当前互斥量没有被其他线程占有,则该线程锁住互斥量,直到该线程调用 unlock 释放互斥量。(2). 如果当前互斥量被其他线程锁住,则当前调用线程返回 false,而并不会被阻塞掉。(3). 如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)。
#include
#include
#include
using namespace std;
/**
就像大家更熟悉的const一样,volatile是一个类型修饰符(type specifier)。
它是被设计用来修饰被不同线程访问和修改的变量。如果不加入volatile,
基本上会导致这样的结果:要么无法编写多线程程序,要么编译器失去大量优化的机会。
**/
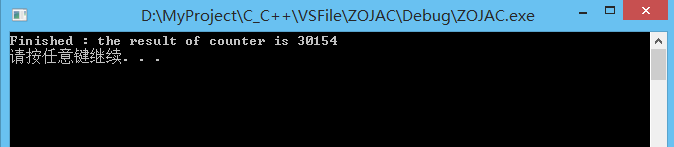
volatile int counter = 0;
const int MAX_TIMES_VALUE = 10000;
mutex my_mutex;
void my_task() {
for (int i = 0; i < MAX_TIMES_VALUE; ++ i) {
//尝试获取锁,try_lock()失败时返回false
if (my_mutex.try_lock()) {
++counter;
my_mutex.unlock();
}
}
}
int main() {
thread threads[10];
for (int i = 0; i < 10; ++ i) {
threads[i] = thread(my_task);
}
for (auto& it : threads) {
it.join();
}
cout << "Finished : the result of counter is " << counter << endl;
system("pause");
return 0;
}
(2)std::recursive_mutex
std::recursive_mutex 与 std::mutex 一样,也是一种可以被上锁的对象,但是和 std::mutex 不同的是,std::recursive_mutex 允许同一个线程对互斥量多次上锁(即递归上锁),来获得对互斥量对象的多层所有权,std::recursive_mutex 释放互斥量时需要调用与该锁层次深度相同次数的 unlock(),可理解为 lock() 次数和 unlock() 次数相同,除此之外,std::recursive_mutex 的特性和 std::mutex 大致相同。
(3)std::time_mutex
std::time_mutex 比 std::mutex 多了两个成员函数,try_lock_for(),try_lock_until()
try_lock_for() 函数接受一个时间范围,表示在这一段时间范围之内线程如果没有获得锁则被阻塞住(与 std::mutex 的 try_lock() 不同,try_lock 如果被调用时没有获得锁则直接返回 false),如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时(即在指定时间内还是没有获得锁),则返回 false。
try_lock_until() 函数则接受一个时间点作为参数,在指定时间点未到来之前线程如果没有获得锁则被阻塞住,如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时(即在指定时间内还是没有获得锁),则返回 false。
#include
#include
#include
#include
using namespace std;
timed_mutex my_mutex;
void my_task(int val, char tag) {
//每200ms尝试获取锁,如果获取到跳出while循环,否则输出一次线程编号
//比如0-200ms,在200ms之前如果获取不到锁,则线程阻塞,时间到了200ms如果取得了锁,
//则加锁,否则返回false
while (!my_mutex.try_lock_for(chrono::milliseconds(200))) {
//int pid = this_thread::get_id().hash();
cout << val;
}
//成功取得锁,然后将线程sleep到1000ms
this_thread::sleep_for(chrono::milliseconds(1000));
cout << tag << endl;
my_mutex.unlock();
}
int main ()
{
thread threads[10];
char end_tag[] = {'!', '@', '#', '$', '%', '^', '&', '*', '(', ')'};
//创建10个线程,分别执行my_task()中的代码
for (int i=0; i<10; ++i) {
threads[i] = thread(my_task, i, end_tag[i]);
}
for (auto& it : threads) {
it.join();
}
system("pause");
return 0;
}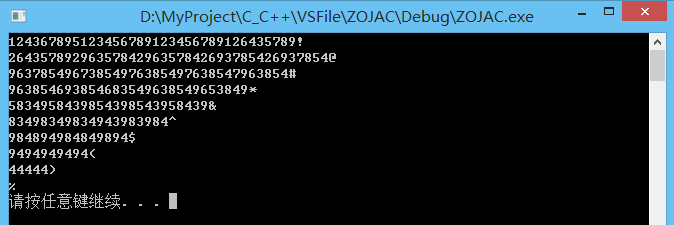
结果分析:
0-9号线程从0ms时刻开始运行,由于线程调度的随机性,假使最开始运行的是0号线程,则0号线程可以在0ms时刻便取得锁,这时候0号线程持锁sleep,这时线程调度会去执行1-9号线程,显然这时是无法取得锁的,所以什么调用try_lock_for()在0-200ms内去尝试取锁,在200ms之前由于取不到锁会分别阻塞,到了200ms这个时刻由于取锁失败,try_lock_for()返回false,所以在200ms这个时刻会在控制台中输出1-9这九个字符,之后类似的,直到到了1000ms这个时刻,0号线程释放了锁,并输出与其对应的tag。
之后的过程便成了9个线程的调度执行的过程了,和上面描述基本类似的过程。
(4)std::recursive_timed_mutex
和 std:recursive_mutex 与 std::mutex 的关系一样,std::recursive_timed_mutex 的特性也可以从 std::timed_mutex 推导出来
(5)std::lock_guard
与 mutex RAII 相关,方便线程对互斥量上锁,是一种自解锁。std::lock_guard是一个局部变量,创建时,对mutex 上锁,析构时对mutex解锁。这个功能在函数体比较长,尤其是存在多个分支的时候很有用
#include
#include
#include
using namespace std;
mutex my_mutex;
void print (int x) {
cout << "value is " << x;
cout << endl;
this_thread::sleep_for(chrono::milliseconds(200));
}
void my_task (int id) {
// lock_guard创建局部变量my_lock,会在lock_guard的构造方法中对my_mutex加锁
lock_guard my_lock (my_mutex);
//由于自解锁的作用,下面的代码相当于临界区,执行过程不会被打断
print(id);
//运行结束时会析构my_lock,然后在析构函数中对my_mutex解锁
}
int main ()
{
thread threads[10];
for (int i=0; i<10; ++i) {
threads[i] = thread(my_task,i+1);
}
for (auto& th : threads) {
th.join();
}
system("pause");
return 0;
} 
(6)std::unique_lock
与 mutex RAII 相关,方便线程对互斥量上锁,但提供了更好的上锁和解锁控制,相对于std::lock_guard来说,std::unique_lock更加灵活,std::unique_lock不拥有与其关联的mutex。构造函数的第二个参数可以指定为std::defer_lock,这样表示在构造unique_lock时,传入的mutex保持unlock状态。然后通过调用std::unique_lock对象的lock()方法或者将将std::unique_lock对象传入std::lock()方法来锁定mutex。
std::unique_lock比std::lock_guard需要更大的空间,因为它需要存储它所关联的mutex是否被锁定,如果被锁定,在析构该std::unique_lock时,就需要unlock它所关联的mutex。std::unique_lock的性能也比std::lock_guard稍差,因为在lock或unlock mutex时,还需要更新mutex是否锁定的标志。大多数情况下,推荐使用std::lock_guard但是如果需要更多的灵活性,比如上面这个例子,或者需要在代码之间传递lock的所有权,这可以使用std::unique_lock,std::unique_lock的灵活性还在于我们可以主动的调用unlock()方法来释放mutex,因为锁的时间越长,越会影响程序的性能,在一些特殊情况下,提前释放mutex可以提高程序执行的效率。
使用std::unique_lock默认构造方法和std::lock_guard类似,多了可以主动unlock,其他相当于一个自解锁,所以类似于unique_lock my_lock(my_mutex)的用法就不再举例。
下面举例使用两个参数构造使用,和锁的所有权传递问题
#include
#include
#include
using namespace std;
mutex my_mutex;
mutex some_mutex;
//使用含两个参数的构造函数
void my_task (int n, char c) {
unique_lock my_lock (my_mutex, defer_lock);
my_lock.lock();
for (int i=0; icout << c;
}
cout << endl;
//会自动unlock
}
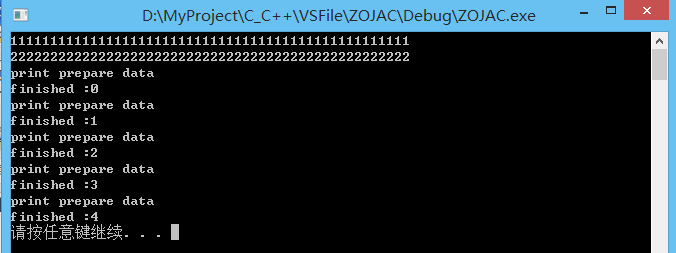
unique_lock prepare_task()
{
unique_lock lock(some_mutex);
cout << "print prepare data" << endl;
//返回对some_mutex的所有权,尚未解锁
return lock;
}
void finish_task(int v)
{
//取得prepare_task创建的锁所有权
unique_lock lk(prepare_task());
cout << "finished :" << v << endl;
//析构,解锁
}
int main ()
{
thread t1 (my_task, 50, '1');
thread t2 (my_task, 50, '2');
t1.join();
t2.join();
thread threads[5];
for(int i = 0; i < 5; ++ i)
{
threads[i] = thread(finish_task, i);
}
for(auto& it : threads) {
it.join();
}
system("pause");
return 0;
} 
其他不同构造函数使用方法简介
1)try-locking :unique_lock(mutex_type& m, try_to_lock_t tag)
新创建的 unique_lock 对象管理 mutex 对象 m,并尝试调用 m.try_lock() 对 mutex 对象进行上锁,但如果上锁不成功,并不会阻塞当前线程。
2)deferred :unique_lock(mutex_type& m, defer_lock_t tag) noexcept
新创建的 unique_lock 对象管理 mutex 对象 m,但是在初始化的时候并不锁住 mutex 对象。m 应该是一个没有当前线程锁住的 mutex 对象。
3)adopting :unique_lock(mutex_type& m, adopt_lock_t tag)
新创建的 unique_lock 对象管理 mutex 对象 m, m 应该是一个已经被当前线程锁住的 mutex 对象。(并且当前新创建的 unique_lock 对象拥有对锁(Lock)的所有权)。
4)locking for:template
#include
#include
#include
#include
using namespace std;
int value;
once_flag value_flag;
void setValue (int x) {
value = x;
}
void my_task (int id) {
this_thread::sleep_for(chrono::milliseconds(1000));
//使setValue函数只被第一次执行的线程执行
call_once (value_flag, setValue, id);
}
int main ()
{
thread threads[10];
for (int i=0; i<10; ++i) {
threads[i] = thread(my_task,i+1);
}
for (auto& it : threads){
it.join();
}
cout << "Finished!! the result of value is : " << value << endl;
system("pause");
return 0;
}
5. std::promise
promise 对象可以保存某一类型 T 的值,该值可被 future 对象读取(可能在另外一个线程中),因此 promise 也提供了一种线程同步的手段。在 promise 对象构造时可以和一个共享状态(通常是std::future)相关联,并可以在相关联的共享状态(std::future)上保存一个类型为 T 的值。
可以通过 get_future 来获取与该 promise 对象相关联的 future 对象,调用该函数之后,两个对象共享相同的共享状态(shared state)
1)promise 对象是异步 Provider,它可以在某一时刻设置共享状态的值。
2)future 对象可以异步返回共享状态的值,或者在必要的情况下阻塞调用者并等待共享状态标志变为 ready,然后才能获取共享状态的值。
入门示例
#include
#include
#include
#include
using namespace std;
//通过std::future获取共享状态的值
void printShareState(future<int>& state) {
// 获取共享状态的值.
int x = state.get();
cout << "share state value : " << x << endl;
}
int main ()
{
// 创建一个 promise 对象,状态值为int类型
promise<int> prom;
// 和 future 关联
future<int> fut = prom.get_future();
// 将 future 交给另外一个线程t.
thread t(printShareState, ref(fut));
// 设置共享状态的值, 此处和线程t保持同步.
prom.set_value(10);
t.join();
system("pause");
return 0;
}
(1)构造函数
1)默认构造函数promise(),初始化一个空的共享状态。
2)带自定义内存分配器的构造函数template promise (allocator_arg_t aa, const Alloc& alloc),与默认构造函数类似,但是使用自定义分配器来分配共享状态。
3)拷贝构造函数promise (const promise&) = delete,被禁用。
4)移动构造函数promise (promise&& x) noexcept。
另外,std::promise 的 operator= 没有拷贝语义,即 std::promise 普通的赋值操作被禁用,operator= 只有 move 语义,所以 std::promise 对象是禁止拷贝的
#include
#include
#include
using namespace std;
//使用默认构造函数构造一个空共享状态的promise对象
promise<int> prom;
void printShareStateValue () {
future<int> fut = prom.get_future();
int x = fut.get();
cout << "share state value is " << x << endl;
}
int main ()
{
thread t1(printShareStateValue);
prom.set_value(10);
t1.join();
//promise()创建一个匿名空的promise对象,使用移动拷贝构造函数给prom
prom = promise<int>();
thread t2 (printShareStateValue);
prom.set_value (20);
t2.join();
system("pause");
return 0;
}
(2)其他成员函数
1)std::promise::get_future()
该函数返回一个与 promise 共享状态相关联的 future 。返回的 future 对象可以访问由 promise 对象设置在共享状态上的值或者某个异常对象。只能从 promise 共享状态获取一个 future 对象。在调用该函数之后,promise 对象通常会在某个时间点准备好(设置一个值或者一个异常对象),如果不设置值或者异常,promise 对象在析构时会自动地设置一个 future_error 异常(broken_promise)来设置其自身的准备状态
2)std::promise::set_value()
void set_value (const T& val);
void set_value (T&& val);
void promise
#include
#include
#include
#include
#include
using namespace std;
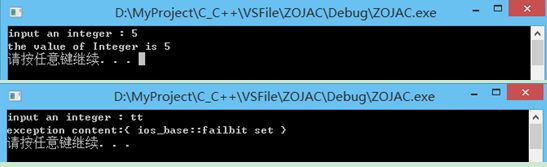
void getAnInteger(promise<int>& prom) {
int x;
cout << "input an integer : ";
//设置如试图从不能解析为整数的字符串里想要读一个整数等,顺便说下eof也会造成failbit被置位
//则产生异常
cin.exceptions (ios::failbit);
try {
cin >> x;
prom.set_value(x);
} catch (exception&) {
prom.set_exception(current_exception());
}
}
void printAnInteger(future<int>& fut) {
try {
int x = fut.get();
cout << "the value of Integer is " << x << endl;
} catch (exception& e) {
cout << "exception content:{ " << e.what() << " }" << endl;;
}
}
int main ()
{
promise<int> prom;
future<int> fut = prom.get_future();
thread t1(getAnInteger, ref(prom));
thread t2(printAnInteger, ref(fut));
t1.join();
t2.join();
system("pause");
return 0;
}
6. std::packaged_task
std::packaged_task 包装一个可调用的对象,并且允许异步获取该可调用对象产生的结果,从包装可调用对象意义上来讲,std::packaged_task 与 std::function 类似,只不过 std::packaged_task 将其包装的可调用对象的执行结果传递给一个 std::future 对象(该对象通常在另外一个线程中获取 std::packaged_task 任务的执行结果)。
std::packaged_task 对象内部包含了两个最基本元素,一、被包装的任务(stored task),任务(task)是一个可调用的对象,如函数指针、成员函数指针或者函数对象,二、共享状态(shared state),用于保存任务的返回值,可以通过 std::future 对象来达到异步访问共享状态的效果。
可以通过 std::packged_task::get_future 来获取与共享状态相关联的 std::future 对象。在调用该函数之后,两个对象共享相同的共享状态,具体解释如下:
std::packaged_task 对象是异步 Provider,它在某一时刻通过调用被包装的任务来设置共享状态的值。
std::future 对象是一个异步返回对象,通过它可以获得共享状态的值,当然在必要的时候需要等待共享状态标志变为 ready.
std::packaged_task 的共享状态的生命周期一直持续到最后一个与之相关联的对象被释放或者销毁为止
#include
#include
#include
using namespace std;
//
int my_task (int from, int to) {
for (int i = from; i != to; --i) {
cout << i << endl;
this_thread::sleep_for(chrono::seconds(1));
}
cout << "Finished!!" << endl;
return from - to;
}
int main ()
{
// 设置packaged_task,形式上类似于std::function
// 如std::function onKeyPressed;
packaged_task<int(int,int)> task(my_task);
// 获得与 packaged_task 共享状态相关联的 future 对象.
future<int> ret = task.get_future();
thread th(move(task), 10, 0); //创建一个新线程完成计数任务.
int value = ret.get(); // 等待任务完成并获取结果.
cout << "the result of the future state value is " << value << endl;
th.join();
system("pause");
return 0;
}
(1)std::packaged_task 构造函数
1)默认构造函数packaged_task() noexcept,初始化一个空的共享状态,并且该 packaged_task 对象无包装任务。
2)template explicit packaged_task (Fn&& fn),初始化一个共享状态,并且被包装任务由参数 fn 指定。
3)带自定义内存分配器的构造函数template
#include
#include
#include
#include
using namespace std;
int main ()
{
// 默认构造函数.
packaged_task<int(int)> foo;
// 使用 lambda 表达式初始化一个 packaged_task 对象.
packaged_task<int(int)> bar([](int x){return x * 3;});
foo = move(bar); // move-赋值操作,也是 C++11 中的新特性.
// 获取与 packaged_task 共享状态相关联的 future 对象.
future<int> ret = foo.get_future();
thread(move(foo), 30).detach(); // 产生线程,调用被包装的任务.
int value = ret.get(); // 等待任务完成并获取结果.
cout << "The final result is " << value << ".\n";
system("pause");
return 0;
}
(2)std::packaged_task::valid() 检查当前 packaged_task 是否和一个有效的共享状态相关联,对于由默认构造函数生成的 packaged_task 对象,该函数返回 false,除非中间进行了 move 赋值操作或者 swap 操作
#include
#include
#include
#include
using namespace std;
// 在新线程中启动一个 int(int) packaged_task.
future<int> launcher(packaged_task<int(int)>& tsk, int arg)
{
if (tsk.valid()) {
future<int> ret = tsk.get_future();
//创建匿名线程,线程运行结束后直接退出不需要和主线程会合
thread (move(tsk),arg).detach();
return ret;
}
else return future<int>();
}
int main ()
{
packaged_task<int(int)> tsk([](int x){return x*2;});
future<int> fut = launcher(tsk,25);
if(fut.get() == 50) {
cout << "task is valid refrence to a shared state" << endl;
} else {
cout << "do nothing" << endl;
}
system("pause");
return 0;
}
(3)std::packaged_task::get_future()
返回一个与 packaged_task 对象共享状态相关的 future 对象。返回的 future 对象可以获得由另外一个线程在该 packaged_task 对象的共享状态上设置的某个值或者异常
(4)std::packaged_task::operator()(Args… args)
调用该 packaged_task 对象所包装的对象(通常为函数指针,函数对象,lambda 表达式等),传入的参数为 args. 调用该函数一般会发生两种情况:
如果成功调用 packaged_task 所包装的对象,则返回值(如果被包装的对象有返回值的话)被保存在 packaged_task 的共享状态中。
如果调用 packaged_task 所包装的对象失败,并且抛出了异常,则异常也会被保存在 packaged_task 的共享状态中。
以上两种情况都使共享状态的标志变为 ready,因此其他等待该共享状态的线程可以获取共享状态的值或者异常并继续执行下去。
共享状态的值可以通过在 future 对象(由 get_future获得)上调用 get 来获得。
由于被包装的任务在 packaged_task 构造时指定,因此调用 operator() 的效果由 packaged_task 对象构造时所指定的可调用对象来决定:
如果被包装的任务是函数指针或者函数对象,调用 std::packaged_task::operator() 只是将参数传递给被包装的对象。
如果被包装的任务是指向类的非静态成员函数的指针,那么 std::packaged_task::operator() 的第一个参数应该指定为成员函数被调用的那个对象,剩余的参数作为该成员函数的参数。
如果被包装的任务是指向类的非静态成员变量,那么 std::packaged_task::operator() 只允许单个参数
(5)std::packaged_task::make_ready_at_thread_exit()
该函数会调用被包装的任务,并向任务传递参数,类似 std::packaged_task 的 operator() 成员函数。但是与 operator() 函数不同的是,make_ready_at_thread_exit 并不会立即设置共享状态的标志为 ready,而是在线程退出时设置共享状态的标志。
如果与该 packaged_task 共享状态相关联的 future 对象在 future::get 处等待,则当前的 future::get 调用会被阻塞,直到线程退出。而一旦线程退出,future::get 调用继续执行,或者抛出异常。
注意,该函数已经设置了 promise 共享状态的值,如果在线程结束之前有其他设置或者修改共享状态的值的操作,则会抛出 future_error( promise_already_satisfied )
(6)std::packaged_task::swap()
交换 packaged_task 的共享状态
(7)std::packaged_task::reset()
重置 packaged_task 的共享状态,但是保留之前的被包装的任务
#include
#include
#include
#include
using namespace std;
int tripleX (int x)
{
return x*3;
}
int main ()
{
packaged_task<int(int)> tsk (tripleX);
future<int> fut = tsk.get_future();
//thread t1(move(tsk), 100);
tsk(100);
cout << "The triple of 100 is " << fut.get() << endl;
//t1.join();
//重置tsk的共享状态
//this_thread::sleep_for(chrono::milliseconds(500));
tsk.reset();
fut = tsk.get_future();
thread(move(tsk), 200).detach();
cout << "Thre triple of 200 is " << fut.get() << endl;
system("pause");
return 0;
}
附:std::function使用实例
直接附代码
#include 附:C++11 lambda表达式使用实例
盗个图表示一下lambda表达式的语法

1 表示Lambda表达式的引入标志,在‘[]’里面可以填入‘=’或‘&’表示该lambda表达式“捕获”(lambda表达式在一定的scope可以访问的数据)的数据时以什么方式捕获的,‘&’表示一引用的方式;‘=’表明以值传递的方式捕获,除非专门指出。
2 表示Lambda表达式的参数列表
3 表示Mutable 标识
4 表示异常标识
5 表示返回值
6 表示“函数”体,也就是lambda表达式需要进行的实际操作
实例可参考上例中的:
auto lambda = [](int a)->int{ return a; };
7. std::future
std::future 可以用来获取异步任务的结果,因此可以把它当成一种简单的线程间同步的手段。std::future 通常由某个 Provider 创建,你可以把 Provider 想象成一个异步任务的提供者,Provider 在某个线程中设置共享状态的值,与该共享状态相关联的 std::future 对象调用 get(通常在另外一个线程中) 获取该值,如果共享状态的标志不为 ready,则调用 std::future::get 会阻塞当前的调用者,直到 Provider 设置了共享状态的值(此时共享状态的标志变为 ready),std::future::get 返回异步任务的值或异常(如果发生了异常)。
一个有效(valid)的 std::future 对象通常由以下三种 Provider 创建,并和某个共享状态相关联。Provider 可以是函数或者类,其实我们前面都已经提到了,他们分别是:
1)std::async() 函数,本文后面会介绍 std::async() 函数。
2)std::promise::get_future(),get_future 为 promise 类的成员函数
3)std::packaged_task::get_future(),此时 get_future为 packaged_task 的成员函数。
一个 std::future 对象只有在有效(valid)的情况下才有用(useful),由 std::future 默认构造函数创建的 future 对象不是有效的(除非当前非有效的 future 对象被 move 赋值另一个有效的 future 对象)。
在一个有效的 future 对象上调用 get 会阻塞当前的调用者,直到 Provider 设置了共享状态的值或异常(此时共享状态的标志变为 ready),std::future::get 将返回异步任务的值或异常(如果发生了异常)。
#include
#include
#include
using namespace std;
bool is_prime(int x)
{
for (int i = 2; i < x; ++i) {
if (x % i == 0) {
return false;
}
}
return true;
}
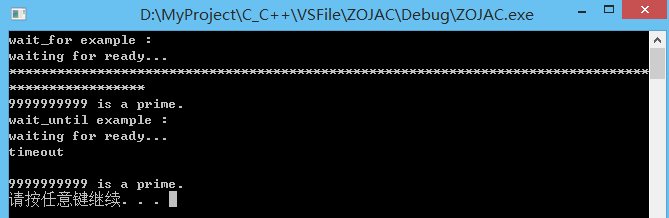
int main()
{
// 异步调用判断999999是不是质数
future < bool > fut = async(is_prime, 9999999999);
//由于上面代码中判断素数的方法对于比较大的数,将耗费较多时间
//开始判断共享状态是否变为了ready,等待
cout << "waiting for ready..." << endl;
chrono::milliseconds span(100);
//每100ms内阻塞等待,如果超时输出*,并继续等待,否则结束while
while (fut.wait_for(span) == future_status::timeout)
cout << '*';
bool ret = fut.get();
cout << endl;
cout << "9999999999 " << (ret ? "is" : "is not") << " a prime." << endl;
system("pause");
return 0;
}
(1)构造函数
1)默认构造函数future() noexcept
2)复制构造函数future (const future&) = delete,不可用
3)future (future&& x) noexcept,move构造函数
(2)赋值操作 普通赋值=已被重载为move操作
(3)std::future::share()
返回一个 std::shared_future 对象,调用该函数之后,该 std::future 对象本身已经不和任何共享状态相关联,因此该 std::future 的状态不再是 valid 的了。
#include
#include
using namespace std;
int do_get_value() {
return 10;
}
int main ()
{
future<int> fut = async(do_get_value);
shared_future<int> shared_fut = fut.share();
// 共享的 future 对象可以被多次访问, fut的状态到这里便不再是valid的了
cout << "value: " << shared_fut.get() << '\n';
cout << "its double: " << shared_fut.get()*2 << '\n';
system("pause");
return 0;
}

(4)std::future::get()
1)T get();
2)R& future
#include
#include
#include
#include
#include
using namespace std;
void getAnInteger(promise<int>& prom) {
int x;
cout << "input an integer : ";
//设置如试图从不能解析为整数的字符串里想要读一个整数等,顺便说下eof也会造成failbit被置位
//则产生异常
cin.exceptions (ios::failbit);
try {
cin >> x;
prom.set_value(x);
} catch (exception&) {
prom.set_exception(current_exception());
}
}
void printAnInteger(future<int>& fut) {
try {
int x = fut.get();
cout << "the value of Integer is " << x << endl;
} catch (exception& e) {
cout << "exception content:{ " << e.what() << " }" << endl;;
}
}
int main ()
{
promise<int> prom;
future<int> fut = prom.get_future();
thread t1(getAnInteger, ref(prom));
thread t2(printAnInteger, ref(fut));
t1.join();
t2.join();
system("pause");
return 0;
}(5)std::future::valid()
检查当前的 std::future 对象是否有效,即释放与某个共享状态相关联。一个有效的 std::future 对象只能通过 std::async(), std::future::get_future 或者 std::packaged_task::get_future 来初始化。另外由 std::future 默认构造函数创建的 std::future 对象是无效(invalid)的,当然通过 std::future 的 move 赋值后该 std::future 对象也可以变为 valid。
#include
#include
#include
using namespace std;
int simple_task()
{
cout << "do task" << endl;
return 0;
}
int main ()
{
// 由默认构造函数创建的 future 对象,
// 初始化时该 future 对象的共享状态处于为 invalid 状态.
future<int> foo, bar;
// move 赋值, foo 的共享状态变为 valid.
foo = async(simple_task);
// move 赋值, bar 的共享状态变为 valid, 而 move 赋值以后 foo 的共享状态变为 invalid.
bar = move(foo);
if (foo.valid())
cout << "foo's value: " << foo.get() << '\n';
else
cout << "foo is not valid\n";
if (bar.valid())
cout << "bar's value: " << bar.get() << '\n';
else
cout << "bar is not valid\n";
system("pause");
return 0;
}
(6)std::future::wait()
等待与当前std::future 对象相关联的共享状态的标志变为 ready.
如果共享状态的标志不是 ready(此时 Provider 没有在共享状态上设置值(或者异常)),调用该函数会被阻塞当前线程,直到共享状态的标志变为 ready。
一旦共享状态的标志变为 ready,wait() 函数返回,当前线程被解除阻塞,但是 wait() 并不读取共享状态的值或者异常
#include
#include
#include
using namespace std;
// 为了体现效果, 该函数故意没有优化.
bool do_task(int x)
{
for (int i = 2; i < x; ++i) {
int a = x / i;
a = x % i;
}
return x % 2;
}
int main()
{
// 异步调用do_task()
future < bool > fut = async(do_task, 99999999);
cout << "Waiting...\n";
fut.wait();
if (fut.get())
cout << "return true" << endl;
else
cout << "return false" << endl;
system("pause");
return 0;
}

(7)std::future::wait_for()和std::future::wait_until()
1)wait_for() 可以设置一个时间段 rel_time,如果共享状态的标志在该时间段结束之前没有被 Provider 设置为 ready,则调用 wait_for 的线程被阻塞,在等待了 rel_time 的时间长度后 wait_until() 返回.
原型:template
#include
#include
#include
#include abs(dur);
//截止到系统时间当前点+dur,如果依然共享状态不是ready,打出timeout
if (fut.wait_until(abs) == future_status::timeout) {
cout << "timeout" << endl;
}
//get会阻塞等待其他线程设置完共计状态
ret = fut.get();
cout << endl;
cout << "9999999999 " << (ret ? "is" : "is not") << " a prime." << endl;
system("pause");
return 0;
} 
8. std::shared_future
std::shared_future 与 std::future 类似,但是 std::shared_future 可以拷贝、多个 std::shared_future 可以共享某个共享状态的最终结果(即共享状态的某个值或者异常)。shared_future 可以通过某个 std::future 对象隐式转换(参见 std::shared_future 的构造函数),或者通过 std::future::share() 显示转换,无论哪种转换,被转换的那个 std::future 对象都会变为 not-valid.
(1)构造函数
1)默认构造函数shared_future() noexcept
2)复制构造函数shared_future (const shared_future& x),可用
3)move构造函数shared_future (shared_future&& x) noexcept
4)shared_future (future&& x) noexcep
其中,move from future(4) 即从一个有效的 std::future 对象构造一个 std::shared_future,构造之后 std::future 对象 x 变为无效(not-valid)
(2)其他成员函数
std::shared_future 的成员函数和 std::future 大部分相同
1)operator=
赋值操作符,与 std::future 的赋值操作不同,std::shared_future 除了支持 move 赋值操作外,还支持普通的赋值操作
2)std::shared_future ::get()
获取与该 std::shared_future 对象相关联的共享状态的值(或者异常)
3)std::shared_future ::valid()
有效性检查。
4)std::shared_future ::wait()
等待与该 std::shared_future 对象相关联的共享状态的标志变为 ready。
5)std::shared_future ::wait_for()
等待与该 std::shared_future 对象相关联的共享状态的标志变为 ready。(等待一段时间,超过该时间段wait_for 返回。)
6)std::shared_future ::wait_until()
等待与该 std::shared_future 对象相关联的共享状态的标志变为 ready。(在某一时刻前等待,超过该时刻 wait_until 返回。)
9. std::future_error
std::future_error 继承子 C++ 标准异常体系中的 logic_error,class future_error : public logic_error。
10. std::future(附)
(1)此部分主要用来说明与std::future相关的一些比较重要的函数std::async()
1)template
#include 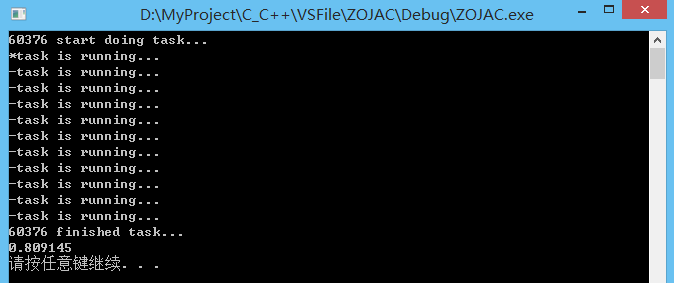
(2)其他与 std::future 相关的枚举类
1)enum class future_errc
std::future_errc 类型描述如下(参考):
类型取值描述
broken_promise 0 与该 std::future 共享状态相关联的 std::promise 对象在设置值或者异常之前一被销毁。
future_already_retrieved 1 与该 std::future 对象相关联的共享状态的值已经被当前 Provider 获取了,即调用了 std::future::get 函数。
promise_already_satisfied 2 std::promise 对象已经对共享状态设置了某一值或者异常。
no_state 3 无共享状态。
2)enum class future_status
std::future_status 类型主要用在 std::future(或std::shared_future)中的 wait_for 和 wait_until 两个函数中的。
类型取值描述
future_status::ready 0 wait_for(或wait_until) 因为共享状态的标志变为 ready 而返回。
future_status::timeout 1 超时,即 wait_for(或wait_until) 因为在指定的时间段(或时刻)内共享状态的标志依然没有变为 ready 而返回。
future_status::deferred 2 共享状态包含了 deferred 函数。
3)enum class launch
该枚举类型主要是在调用 std::async 设置异步任务的启动策略的。
类型描述
launch::async Asynchronous: 异步任务会在另外一个线程中调用,并通过共享状态返回异步任务的结果(一般是调用 std::future::get() 获取异步任务的结果)。
launch::deferred Deferred: 异步任务将会在共享状态被访问时调用,相当与按需调用(即延迟(deferred)调用)。
#include
#include
#include
#include
void my_task(char c, int ms)
{
for (int i = 0; i < 10; ++i) {
std::this_thread::sleep_for(std::chrono::milliseconds(ms));
std::cout << c;
}
}
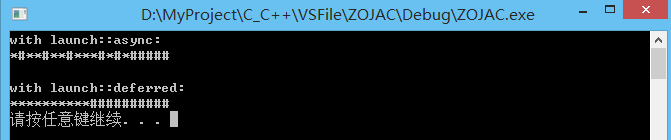
int main()
{
std::cout << "with launch::async:\n";
std::future < void >foo =
std::async(std::launch::async, my_task, '*', 100);
std::future < void >bar =
std::async(std::launch::async, my_task, '#', 200);
// async "get" (wait for foo and bar to be ready):
foo.get();
bar.get();
std::cout << "\n\n";
std::cout << "with launch::deferred:\n";
foo = std::async(std::launch::deferred, my_task, '*', 100);
bar = std::async(std::launch::deferred, my_task, '#', 200);
// deferred "get" (perform the actual calls):
foo.get();
bar.get();
std::cout << '\n';
system("pause");
return 0;
}
11. std::condition_variable
头文件主要包含了与条件变量相关的类和函数。相关的类包括 std::condition_variable 和 std::condition_variable_any,还有枚举类型std::cv_status。另外还包括函数 std::notify_all_at_thread_exit()
std::condition_variable 是条件变量。
当 std::condition_variable 对象的某个 wait 函数被调用的时候,它使用 std::unique_lock(通过 std::mutex) 来锁住当前线程。当前线程会一直被阻塞,直到另外一个线程在相同的 std::condition_variable 对象上调用了 notification 函数来唤醒当前线程。
std::condition_variable 对象通常使用 std::unique_lock 来等待,如果需要使用另外的 lockable 类型,可以使用 std::condition_variable_any 类
#include
#include
#include
#include
// 全局互斥锁.
std::mutex mtx;
// 全局条件变量.
std::condition_variable cv;
// 全局标志位.
bool ready = false;
void do_print_id(int id)
{
std::unique_lock <std::mutex> lck(mtx);
// 如果标志位不为 true, 则等待...
// 当前线程被阻塞, 当全局标志位变为 true 之后,
// 线程被唤醒, 继续往下执行打印线程编号id.
while (!ready)
cv.wait(lck);
std::cout << "thread " << id << std::endl;
}
void go()
{
std::unique_lock <std::mutex> lck(mtx);
// 设置全局标志位为 true.
ready = true;
// 唤醒所有线程.
cv.notify_all();
}
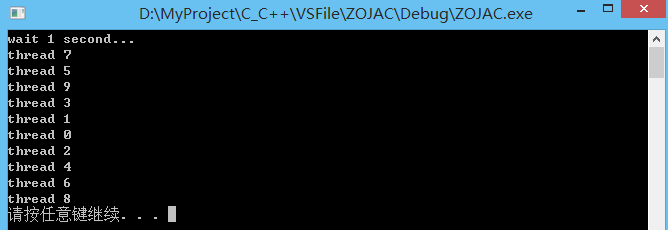
int main()
{
std::thread threads[10];
// 创建10个线程,由于全局标志ready为false,
// 所以所有线程创建完成后均会从运行态转为阻塞态
for (int i = 0; i < 10; ++i)
threads[i] = std::thread(do_print_id, i);
// 修改ready标志,并通知所有线程可以从阻塞态转为运行态
// 但显然10个线程也是在某一刻只能运行一个
std::cout << "wait 1 second..." << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1));
go();
for (auto & th:threads) {
th.join();
}
system("pause");
return 0;
}
(1)构造函数
std::condition_variable 的拷贝构造函数被禁用,只提供了默认构造函数
(2)std::condition_variable::wait()
1)void wait (unique_lock& lck);
2)template
void wait (unique_lock& lck, Predicate pred)
std::condition_variable 提供了两种 wait() 函数。当前线程调用 wait() 后将被阻塞(此时当前线程应该获得了锁(mutex),不妨设获得锁 lck),直到另外某个线程调用 notify_* 唤醒了当前线程。
在线程被阻塞时,该函数会自动调用 lck.unlock() 释放锁,使得其他被阻塞在锁竞争上的线程得以继续执行。另外,一旦当前线程获得通知(notified,通常是另外某个线程调用 notify_* 唤醒了当前线程),wait() 函数也是自动调用 lck.lock(),使得 lck 的状态和 wait 函数被调用时相同。
在第二种情况下(即设置了 Predicate),只有当 pred 条件为 false 时调用 wait() 才会阻塞当前线程,并且在收到其他线程的通知后只有当 pred 为 true 时才会被解除阻塞。因此第二种情况类似于while (!pred()) wait(lck);
#include
#include
#include
#include
std::mutex mtx;
std::condition_variable cv;
int cargo = 0;
bool shipment_available()
{
return cargo != 0;
}
// 消费者线程.
void consume(int n)
{
for (int i = 0; i < n; ++i) {
std::unique_lock <std::mutex> lck(mtx);
//只有当 shipment_available()返回为 false 时调用 wait() 才会阻塞当前线程,
//并且在收到其他线程的通知后只有当shipment_available()返回为 true 时才会被解除阻塞
cv.wait(lck, shipment_available);
std::cout << cargo << '\n';
cargo = 0;
}
}
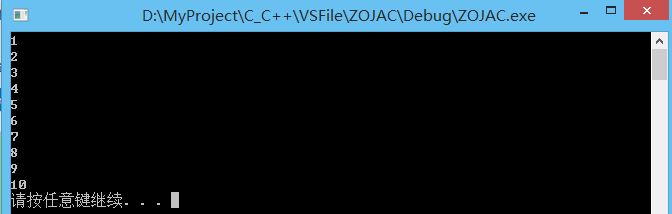
int main()
{
std::thread consumer_thread(consume, 10); // 消费者线程.
// 主线程为生产者线程, 生产 10 个物品.
for (int i = 0; i < 10; ++i) {
while (shipment_available()) {
//yield() 函数可以用来将调用者线程跳出运行状态,重新交给操作系统进行调度
std::this_thread::yield();
}
std::unique_lock <std::mutex> lck(mtx);
cargo = i + 1;
cv.notify_one();
}
consumer_thread.join();
system("pause");
return 0;
}
(3)std::condition_variable::wait_for()
1)template
#include
#include
#include
#include
#include
using namespace std;
condition_variable cv;
int value;
void my_task()
{
cin >> value;
cv.notify_one();
}
int main ()
{
//创建一个子线程执行my_task;
thread th(my_task);
mutex mtx;
unique_lock lck(mtx);
while (cv.wait_for(lck,chrono::seconds(1)) == cv_status::timeout) {
cout << '.';
cout.flush();
}
cout << "the entered integer is : " << value << endl;
th.join();
system("pause");
return 0;
} 
(4)std::condition_variable::wait_until()
1)template
#include
#include
#include
#include
using namespace std;
mutex mtx;
condition_variable cv;
int cargo = 0;
void consumer()
{
unique_lock < mutex > lck(mtx);
while (cargo == 0)
cv.wait(lck);
cout << cargo << '\n';
cargo = 0;
}
void producer(int id)
{
unique_lock < mutex > lck(mtx);
cargo = id;
cv.notify_one();
}
int main()
{
thread consumers[10], producers[10];
// create 10 consumers and 10 producers:
for (int i = 0; i < 10; ++i) {
consumers[i] = thread(consumer);
}
for (int i = 0; i < 10; ++i) {
producers[i] = thread(producer, i + 1);
}
for (int i = 0; i < 10; ++i) {
producers[i].join();
consumers[i].join();
}
system("pause");
return 0;
}
(6)std::condition_variable::notify_all()
唤醒所有的等待(wait)线程。如果当前没有等待线程,则该函数什么也不做,使用实例可参考本节开头的第一个实例。
12. std::condition_variable_any和其他相关内容
(1)std::condition_variable_any
与 std::condition_variable 类似,只不过 std::condition_variable_any 的 wait 函数可以接受任何 lockable 参数,而 std::condition_variable 只能接受 std::unique_lock 类型的参数,除此以外,和 std::condition_variable 几乎完全一样。
(2)其他相关内容
1)std::cv_status 枚举
cv_status::no_timeout wait_for 或者 wait_until 没有超时,即在规定的时间段内线程收到了通知。
cv_status::timeout wait_for 或者 wait_until 超时。
2)std::notify_all_at_thread_exit()
原型:void notify_all_at_thread_exit (condition_variable& cond, unique_lock lck);
#include lck(mtx);
while (!ready) cv.wait(lck);
cout << "thread " << id << '\n';
}
void go() {
unique_lock lck(mtx);
notify_all_at_thread_exit(cv,move(lck));
ready = true;
}
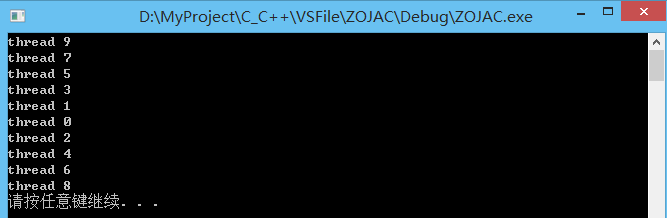
int main ()
{
thread threads[10];
for (int i=0; i<10; ++i) {
threads[i] = thread(my_task,i);
}
// 创建子线程执行go(),并运行完之后自己退出
thread(go).detach();
for (auto& th : threads) {
th.join();
}
system("pause");
return 0;
} 
13. std::atomic_flag
atomic_flag。atomic_flag 一种简单的原子布尔类型,只支持两种操作,test-and-set 和 clear.
std::atomic_flag 只有默认构造函数,拷贝构造函数已被禁用,因此不能从其他的 std::atomic_flag 对象构造一个新的 std::atomic_flag 对象。
如果在初始化时没有明确使用 ATOMIC_FLAG_INIT初始化,那么新创建的 std::atomic_flag 对象的状态是未指定的(unspecified)(既没有被 set 也没有被 clear。)另外,atomic_flag不能被拷贝,也不能 move 赋值。
ATOMIC_FLAG_INIT: 如果某个 std::atomic_flag 对象使用该宏初始化,那么可以保证该 std::atomic_flag 对象在创建时处于 clear 状态。
#include 
(1)std::atomic_flag::test_and_set()
std::atomic_flag 的 test_and_set 函数原型如下:
bool test_and_set (memory_order sync = memory_order_seq_cst) volatile noexcept;
bool test_and_set (memory_order sync = memory_order_seq_cst) noexcept;
test_and_set() 函数检查 std::atomic_flag 标志,如果 std::atomic_flag 之前没有被设置过,则设置 std::atomic_flag 的标志,并返回先前该 std::atomic_flag 对象是否被设置过,如果之前 std::atomic_flag 对象已被设置,则返回 true,否则返回 false。
test-and-set 操作是原子的(因此 test-and-set 是原子 read-modify-write (RMW)操作)。
test_and_set 可以指定 Memory Order,取值如下:
1)memory_order_relaxed,类型为Relaxed
2)memory_order_consume,类型为Consume
3)memory_order_acquire,类型为Acquire
4)memory_order_release,类型为Release
5)memory_order_acq_rel,类型为Acquire/Release
6)memory_order_seq_cst,类型为Sequentially consistent
#include 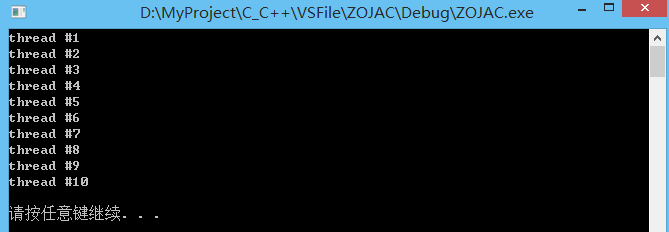
(2)std::atomic_flag::clear()
清除 std::atomic_flag 对象的标志位,即设置 atomic_flag 的值为 false。clear 函数原型如下:
void clear (memory_order sync = memory_order_seq_cst) volatile noexcept;
void clear (memory_order sync = memory_order_seq_cst) noexcept;
清除 std::atomic_flag 标志使得下一次调用 std::atomic_flag::test_and_set 返回 false。
std::atomic_flag::clear() 可以指定 Memory Order,取值同test_and_set()中所述
#include 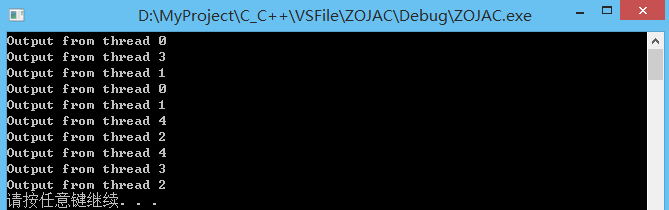
在上面的程序中,std::atomic_flag 对象 lock 的上锁操作可以理解为 lock.test_and_set(std::memory_order_acquire)解锁操作相当与 lock.clear(std::memory_order_release)。
在上锁的时候,如果 lock.test_and_set 返回 false,则表示上锁成功(此时 while 不会进入自旋状态),因为此前 lock 的标志位为 false(即没有线程对 lock 进行上锁操作),但调用 test_and_set 后 lock 的标志位为 true,说明某一线程已经成功获得了 lock 锁。
如果在该线程解锁(即调用 lock.clear(std::memory_order_release)) 之前,另外一个线程也调用 lock.test_and_set(std::memory_order_acquire) 试图获得锁,则 test_and_set(std::memory_order_acquire) 返回 true,则 while 进入自旋状态。如果获得锁的线程解锁(即调用了 lock.clear(std::memory_order_release))之后,某个线程试图调用 lock.test_and_set(std::memory_order_acquire) 并且返回 false,则 while 不会进入自旋,此时表明该线程成功地获得了锁。
按照上面的分析,我们知道在某种情况下 std::atomic_flag 对象可以当作一个简单的自旋锁使用。
14. std::atomic
std::atomic 是模板类,一个模板类型为 T 的原子对象中封装了一个类型为 T 的值。
template struct atomic;
原子类型对象的主要特点就是从不同线程访问不会导致数据竞争(data race)。因此从不同线程访问某个原子对象是良性 (well-defined) 行为,而通常对于非原子类型而言,并发访问某个对象(如果不做任何同步操作)会导致未定义 (undifined) 行为发生。
另外,C++11 标准库 std::atomic 提供了针对整形(integral)和指针类型的特化实现,分别定义如下:
针对整形(integal)的特化,其中 integal 代表了如下类型char, signed char, unsigned char, short, unsigned short, int, unsigned int, long, unsigned long, long long, unsigned long long, char16_t, char32_t, wchar_t
(1)构造函数
1)默认构造函数atomic() noexcept = default,由默认构造函数创建的 std::atomic 对象处于未初始化(uninitialized)状态,对处于未初始化(uninitialized)状态 std::atomic对象可以由 atomic_init 函数进行初始化。
2)初始化构造函数constexpr atomic (T val) noexcept,由类型 T初始化一个 std::atomic对象。
3)拷贝构造函数被禁用。
#include 类型的原子变量
std::atomic<bool> ready(false);
std::atomic_flag winner = ATOMIC_FLAG_INIT;
void my_task(int id)
{
// 等待 ready 变为 true.
while (!ready) {
std::this_thread::yield();
}
for (volatile int i=0; i<1000000; ++i) {} // 计数
if (!winner.test_and_set()) {
std::cout << "thread " << id << " finished firstly!\n";
}
}
int main ()
{
std::vector<std::thread> threads;
for (int i=1; i<=10; ++i) {
threads.push_back(std::thread(my_task,i));
}
//由于ready是原子的,所以做赋值操作是线程安全的
ready = true;
for (auto& th : threads) {
th.join();
}
system("pause");
return 0;
}
(2)std::atomic::operator=()
1)set value T operator= (T val) noexcept;
T operator= (T val) volatile noexcept;
2)copy [deleted] atomic& operator= (const atomic&) = delete;
atomic& operator= (const atomic&) volatile = delete
可以看出,普通的赋值拷贝操作已经被禁用。但是一个类型为 T 的变量可以赋值给相应的原子类型变量(相当与隐式转换),该操作是原子的,内存序(Memory Order) 默认为顺序一致性(std::memory_order_seq_cst),如果需要指定其他的内存序,需使用 std::atomic::store()。
#include 
(3)is_lock_free()、store()、load()和operator T
1)is_lock_free()判断该 std::atomic 对象是否具备 lock-free 的特性。如果某个对象满足 lock-free 特性,在多个线程访问该对象时不会导致线程阻塞。(可能使用某种事务内存transactional memory 方法实现 lock-free 的特性)
2)store()修改被封装的值,std::atomic::store 函数将类型为 T 的参数 val 复制给原子对象所封装的值。T 是 std::atomic 类模板参数。另外参数 sync 指定内存序(Memory Order)。
3)load()读取被封装的值,参数 sync 设置内存序(Memory Order)
4)与 load 功能类似,也是读取被封装的值,operator T() 是类型转换(type-cast)操作,默认的内存序是 std::memory_order_seq_cst,如果需要指定其他的内存序,你应该使用 load() 函数。
#include 
(4)exchange() T exchange (T val, memory_order sync = memory_order_seq_cst)
读取并修改被封装的值,exchange 会将 val 指定的值替换掉之前该原子对象封装的值,并返回之前该原子对象封装的值,整个过程是原子的(因此exchange 操作也称为 read-modify-write 操作)。sync参数指定内存序(Memory Order)
#include 
(5)compare_exchange_weak()
1)bool compare_exchange_weak (T& expected, T val,
memory_order sync = memory_order_seq_cst) volatile noexcept;
bool compare_exchange_weak (T& expected, T val,
memory_order sync = memory_order_seq_cst) noexcept;
2)bool compare_exchange_weak (T& expected, T val,
memory_order success, memory_order failure) volatile noexcept;
bool compare_exchange_weak (T& expected, T val,
memory_order success, memory_order failure) noexcept;
比较并交换被封装的值(weak)与参数 expected 所指定的值是否相等,如果:
相等,则用 val 替换原子对象的旧值。
不相等,则用原子对象的旧值替换 expected ,因此调用该函数之后,如果被该原子对象封装的值与参数 expected 所指定的值不相等,expected 中的内容就是原子对象的旧值。
该函数通常会读取原子对象封装的值,如果比较为 true(即原子对象的值等于 expected),则替换原子对象的旧值,但整个操作是原子的,在某个线程读取和修改该原子对象时,另外的线程不能对读取和修改该原子对象。
在第(2)种情况下,内存序(Memory Order)的选择取决于比较操作结果,如果比较结果为 true(即原子对象的值等于 expected),则选择参数 success 指定的内存序,否则选择参数 failure 所指定的内存序。
注意,该函数直接比较原子对象所封装的值与参数 expected 的物理内容,所以某些情况下,对象的比较操作在使用 operator==() 判断时相等,但 compare_exchange_weak 判断时却可能失败,因为对象底层的物理内容中可能存在位对齐或其他逻辑表示相同但是物理表示不同的值(比如 true 和 2 或 3,它们在逻辑上都表示”真”,但在物理上两者的表示并不相同)。
与compare_exchange_strong 不同, weak 版本的 compare-and-exchange 操作允许(spuriously 地)返回 false(即原子对象所封装的值与参数 expected 的物理内容相同,但却仍然返回 false),不过在某些需要循环操作的算法下这是可以接受的,并且在一些平台下 compare_exchange_weak 的性能更好 。如果 compare_exchange_weak 的判断确实发生了伪失败(spurious failures)——即使原子对象所封装的值与参数 expected 的物理内容相同,但判断操作的结果却为 false,compare_exchange_weak函数返回 false,并且参数 expected 的值不会改变。
对于某些不需要采用循环操作的算法而言, 通常采用compare_exchange_strong 更好。另外,该函数的内存序由sync 参数指定
#include list_head (nullptr);
void append (int val) {
//头插法插入新结点
Node* oldHead = list_head;
//Node node = {val,oldHead};
//Node *newNode = &node;
Node *newNode = new Node(val, oldHead);
// what follows is equivalent to: list_head = newNode, but in a thread-safe way:
while (!list_head.compare_exchange_weak(oldHead,newNode))
newNode->next = oldHead;
}
int main ()
{
std::vector<std::thread> threads;
for (int i = 0; i < 10; ++i) {
threads.push_back(std::thread(append, i));
}
for (auto& th : threads) {
th.join();
}
// print contents:
for (Node* it = list_head; it!=nullptr; it=it->next)
std::cout << ' ' << it->value;
std::cout << '\n';
// cleanup:
Node* it; while (it=list_head) {list_head=it->next; delete it;}
system("pause");
return 0;
} 
(6)compare_exchange_strong()
1)bool compare_exchange_strong (T& expected, T val,
memory_order sync = memory_order_seq_cst) volatile noexcept;
bool compare_exchange_strong (T& expected, T val,
memory_order sync = memory_order_seq_cst) noexcept;
2)bool compare_exchange_strong (T& expected, T val,
memory_order success, memory_order failure) volatile noexcept;
bool compare_exchange_strong (T& expected, T val,
memory_order success, memory_order failure) noexcept;
比较并交换被封装的值(strong)与参数 expected 所指定的值是否相等,如果:
相等,则用 val 替换原子对象的旧值。
不相等,则用原子对象的旧值替换 expected ,因此调用该函数之后,如果被该原子对象封装的值与参数 expected 所指定的值不相等,expected 中的内容就是原子对象的旧值。
该函数通常会读取原子对象封装的值,如果比较为 true(即原子对象的值等于 expected),则替换原子对象的旧值,但整个操作是原子的,在某个线程读取和修改该原子对象时,另外的线程不能对读取和修改该原子对象。
在第(2)种情况下,内存序(Memory Order)的选择取决于比较操作结果,如果比较结果为 true(即原子对象的值等于 expected),则选择参数 success 指定的内存序,否则选择参数 failure 所指定的内存序。
注意,该函数直接比较原子对象所封装的值与参数 expected 的物理内容,所以某些情况下,对象的比较操作在使用 operator==() 判断时相等,但 compare_exchange_weak 判断时却可能失败,因为对象底层的物理内容中可能存在位对齐或其他逻辑表示相同但是物理表示不同的值(比如 true 和 2 或 3,它们在逻辑上都表示”真”,但在物理上两者的表示并不相同)。
与compare_exchange_weak 不同, strong版本的 compare-and-exchange 操作不允许(spuriously 地)返回 false,即原子对象所封装的值与参数 expected 的物理内容相同,比较操作一定会为 true。不过在某些平台下,如果算法本身需要循环操作来做检查, compare_exchange_weak 的性能会更好。
因此对于某些不需要采用循环操作的算法而言, 通常采用compare_exchange_strong 更好。另外,该函数的内存序由 sync 参数指定。
示例代码和compare_exchange_weak()类似,除了append()函数体中的while循环应为:
while (!(list_head.compare_exchange_strong(newNode->next, newNode)));
15. C++11内存模型
原子类型的大多数 API 都需要程序员提供一个 std::memory_order(可译为内存序,访存顺序) 的枚举类型值作为参数,比如:atomic_store,atomic_load,atomic_exchange,atomic_compare_exchange 等 API 的最后一个形参为 std::memory_order order,默认值是 std::memory_order_seq_cst(顺序一致性)。
顺序一致性不仅在共享存储系统上适用,在多处理器和多线程环境下也同样适用。而在多处理器和多线程环境下理解顺序一致性包括两个方面,(1). 从多个线程平行角度来看,程序最终的执行结果相当于多个线程某种交织执行的结果,(2)从单个线程内部执行顺序来看,该线程中的指令是按照程序事先已规定的顺序执行的(即不考虑运行时 CPU 乱序执行和 Memory Reorder)。
顺序一致性代价太大,不利于程序的优化,现在的编译器在编译程序时通常将指令重新排序(当然前提是保证程序的执行结果是正确的)。
C++11 中规定了 6 中访存次序(Memory Order):
enum memory_order {
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
};
std::memory_order 规定了普通访存操作和相邻的原子访存操作之间的次序是如何安排的,在多核系统中,当多个线程同时读写多个变量时,其中的某个线程所看到的变量值的改变顺序可能和其他线程写入变量值的次序不相同。同时,不同的线程所观察到的某变量被修改次序也可能不相同。然而,如果保证所有对原子变量的操作都是顺序的话,可能对程序的性能影响很大,因此,我们可以通过 std::memory_order 来指定编译器对访存次序所做的限制。因此,在原子类型的 API 中,我们可以通过额外的参数指定该原子操作的访存次序(内存序),默认的内存序是 std::memory_order_seq_cst。
我们可以把上述 6 中访存次序(内存序)分为 3 类,顺序一致性模型(std::memory_order_seq_cst),Acquire-Release 模型(std::memory_order_consume, std::memory_order_acquire, std::memory_order_release, std::memory_order_acq_rel,) 和 Relax 模型(std::memory_order_relaxed)。三种不同的内存模型在不同类型的 CPU上(如 X86,ARM,PowerPC等)所带来的代价也不一样。例如,在 X86 或者 X86-64平台下,Acquire-Release 类型的访存序不需要额外的指令来保证原子性,即使顺序一致性类型操作也只需要在写操作(Store)时施加少量的限制,而在读操作(Load)则不需要花费额外的代价来保证原子性。
处理器一致性(Processor Consistency)模型:处理器一致性(Processor Consistency)模型比顺序一致性模型弱,因此对于某些在顺序一致性模型下能够正确执行的程序在处理器一致性条件下执行时可能会导致错误的结果,处理器一致性模型对访存事件发生次序施加的限制是:(1). 在任意读操作(Load)被允许执行之前,所有在同一处理器中先于这一 Load 的读操作都已完成;(2). 在任意写操作(Store)被允许执行之前,所有在同一处理器中先于这一 Store 的访存操作(包括 Load 和 Store操作)都已完成。上述条件允许 Store 之后的 Load 越过 Store 操作而有限执行。
弱一致性(Weak Consistency)模型:弱一致性(Weak Consistency)模型的主要思想是将同步操作和普通的访存操作区分开来,程序员必须用硬件可识别的同步操作把对可写共享单元的访存保护起来,以保证多个处理器对可写单元的访问是互斥的。弱一致性对访存事件发生次序的限制如下:(1). 同步操作的执行满足顺序一致性条件; (2). 在任一普通访存操作被允许执行之前,所有在同一处理器中先于这一访存操作的同步操作都已完成; (3). 在任一同步操作被允许执行之前,所有在同一处理器中先于这一同步操作的普通操作都已完成。上述条件允许在同步操作之间的普通访存操作执行时不用考虑进程之间的相关,虽然弱一致性增加了程序员的负担,但是它能有效地提高系统的性能。
释放一致性(Release Consistency)模型:释放一致性(Release Consistency)模型是对弱一致性(Weak Consistency)模型的改进,它把同步操作进一步分成了获取操作(Acquire)和释放操作(Release)。Acquire 用于获取对某些共享变量的独占访问权,而 Release 则用于释放这种访问权,释放一致性(Release Consistency)模型访存事件发生次序的限制如下:(1). 同步操作的执行满足顺序一致性条件; (2). 在任一普通访存操作被允许执行之前,所有在同一处理器中先于这一访存操作的 Acquire 操作都已完成; (3). 在任一 Release 操作被允许执行之前,所有在同一处理器中先于这一 Release 操作的普通操作都已完成。
在硬件实现的释放一致性模型中,对共享单元的访存是及时进行的,并在执行获取操作(Acquire)和释放操作(Release)时对齐。在共享虚拟存储系统或者在由软件维护的数据一致性的共享存储系统中,由于通信和数据交换的开销很大,有必要减少通信和数据交换的次数。为此,人们在释放一致性(Release Consistency)模型的基础上提出了急切更新释放一致性模型(Eager Release Consistency)和懒惰更新释放一致性模型(Lazy Release Consistency)。在急切更新释放一致性模型中,在临界区内的多个存数操作对共享内存的更新不是及时进行的,而是在执行 Release 操作之前(即退出临界区之前)集中进行,把多个存数操作合并在一起统一执行,从而减少了通信次数。而在懒惰更新释放一致性模型中,由一个处理器对某单元的存数操作并不是由此处理器主动传播到所有共享该单元的其他处理器,而是在其他处理器要用到此处理器所写的数据时(即其他处理器执行 Acquire 操作时)再向此处理器索取该单元的最新备份,这样可以进一步减少通信量。
16. 应用实例
本文将就四种情况分析并介绍生产者和消费者问题,它们分别是:单生产者-单消费者模型,单生产者-多消费者模型,多生产者-单消费者模型,多生产者-多消费者模型。
(1)单生产者-单消费者模型
单生产者-单消费者模型中只有一个生产者和一个消费者,生产者不停地往产品库中放入产品,消费者则从产品库中取走产品,产品库容积有限制,只能容纳一定数目的产品,如果生产者生产产品的速度过快,则需要等待消费者取走产品之后,产品库不为空才能继续往产品库中放置新的产品,相反,如果消费者取走产品的速度过快,则可能面临产品库中没有产品可使用的情况,此时需要等待生产者放入一个产品后,消费者才能继续工作。
#include 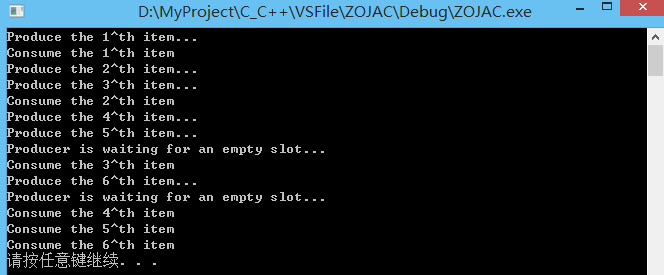
(2)单生产者-多消费者模型
与单生产者和单消费者模型不同的是,单生产者-多消费者模型中可以允许多个消费者同时从产品库中取走产品。所以除了保护产品库在多个读写线程下互斥之外,还需要维护消费者取走产品的计数器.
#include 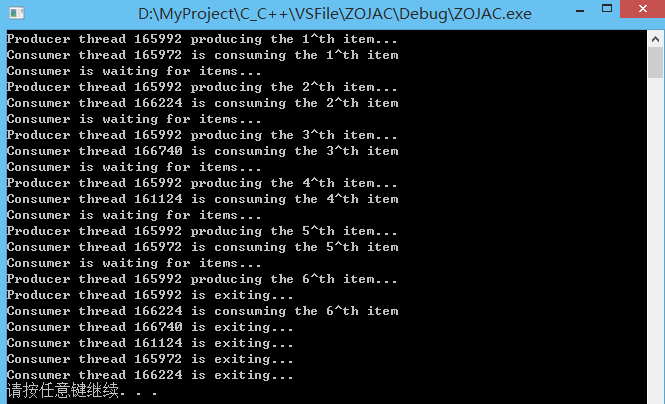
(3)多生产者-单消费者模型
与单生产者和单消费者模型不同的是,多生产者-单消费者模型中可以允许多个生产者同时向产品库中放入产品。所以除了保护产品库在多个读写线程下互斥之外,还需要维护生产者放入产品的计数器。
#include 
(4)多生产者-多消费者模型
该模型可以说是前面两种模型的综合,程序需要维护两个计数器,分别是生产者已生产产品的数目和消费者已取走产品的数目。另外也需要保护产品库在多个生产者和多个消费者互斥地访问.
#include 
参考资料
http://www.cnblogs.com/haippy/p/3284540.html
http://www.cplusplus.com/reference/multithreading/