hive学习笔记第一篇
Hive学习篇
安装
安装hadoo,本实例中hadoop在/usr/local/hadoop下
Hive安装在/home/Hadoop/app/hive下
参考文档:http://blog.csdn.net/xiaoshunzi111/article/details/51889486
测试练习以及遇到的问题:
开启hadoop
cd /usr/local/hadoop/sbin
./start-all.sh
1. 开启hive:
1)Hive
报错Exception in thread "main" java.lang.NoClassDefFoundError:org/apache/hadoop/hive/ql/CommandNeedRetryException
解决方法:
修改hadoop/conf/ hadoop-env.sh;将HADOOP_CLASSPATH原来的值改为如下,重启hadoop集群,然后启动hive,启动成功。
exportHADOOP_CLASSPATH=.:$CLASSPATH:$HADOOP_CLASSPATH:$HADOOP_HOME/bin
2)依然报错:[ERROR]Terminal initialization failed; falling back to unsupported
解决方法:命令行输入
export HADOOP_USER_CLASSPATH_FIRST=true
3)hive启动异常Causedby: java.lang.IllegalArgumentException: java.net.URISyntaxException: Relativepath in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D
解决方法:
1.查看hive-site.xml配置,会看到配置值含有"system:java.io.tmpdir"的配置项
2.新建文件夹在hive目录下新建一个tmp目录
3.将含有"system:java.io.tmpdir"的配置项的值修改为如上地址
把${system:java.io.tmpdir}改成:/home/hadoop/hive/tmp 有2个地方
4)登录到hive数据仓库后,输入一些命令,例如(show databases ,show tables),会报出如下错误:
Failed with exception Java.io.IOException:java.lang.IllegalArgumentException: java.NET.URISyntaxException: Relative path inabsolute URI: ${system:user.name}
解决方法:
打开hive-site.xml找到如下属性
修改成:
/home/hadoop/hive/tmp${user.name}
2. Hive 创建数据库,
Hive>create table testtb(id INT,name STRING) ROW FORMATDELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' STORED AS TEXTFILE;
3. 将本地文件导入数据库:
Hive>load data local inpath ‘/home/Hadoop/app/hive/sz.data’overwrite into table testtb;
4. 中文乱码
解决:
5. 查看hdfs目录下的文件
hadoop dfs -ls/user/Hadoop/
6. 查看数据库的目录
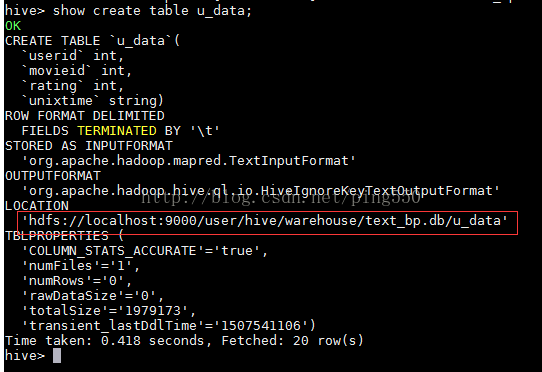
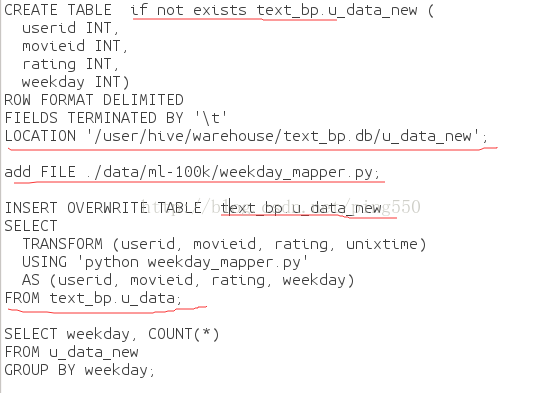
7. 通过脚本创建表hive-mapper.q文件内容如下:
(第一行text_bp指定在某个数据库下面创建表;最后一行location指定该表在hdfs上存放的位置)
CREATETABLE text_bp.u_data_new (
userid INT,
movieid INT,
rating INT,
weekday INT)
ROWFORMAT DELIMITED
FIELDSTERMINATED BY '\t'
LOCATION'/user/hive/warehouse/text_bp.db/u_data_new';
Weekday_mapper.py脚本的内容如下:
importsys
importdatetime
for linein sys.stdin:
line = line.strip()
userid, movieid, rating, unixtime =line.split('\t')
weekday =datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
print'\t'.join([userid, movieid, rating, str(weekday)])
大数据处理步骤
1. 导入大数据到hive
导入方式:从本地文件系统中导入数据到Hive表;
1. Hive> create table testtb(idINT,name STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATEDBY '\n' STORED AS TEXTFILE;
2. 将本地文件导入数据库:
Hive>load data local inpath ‘/home/Hadoop/app/hive/sz.data’overwrite into table testtb;
导入方式二:通过mysql同步到hive
前提:安装mysql;安装hadoop以及hive
导入mysql的test数据库的所有表到hive:
./sqoop import --connect jdbc:mysql://localhost:3306/test--username hadoop_test --password 123456 --table mytest--hive-import