爬虫实战
码云地址:https://gitee.com/XiangWenTian001/spider
上篇博文介绍了mybatis_plus的基本使用,这一部分打算弄个项目实践它。刚好最近在学爬虫和es,恰好可以整合在一起。打算使用springboot+mybatis_plus搭建工程,使用爬虫框架webMagic爬取52Job上的招聘数据,使用es进行大数据量的搜索。
项目前准备:爬虫的本质是模拟浏览器向网站后台发送请求获取相应的数据再进行解析,可以学习HTTPClient相关知识了解下。
WebMagic是一个简单灵活的Java爬虫框架。基于WebMagic,你可以快速开发出一个高效、易维护的爬虫。webMagic的架构设计参照了python的Scrapy,目标是尽量的模块化,并体现爬虫的功能特点。WebMagic文档地址:http://webmagic.io/docs/zh/
需求分析:如图,
1.如何定时爬取?爬虫需要定时执行,设计一个定时任务,将爬虫爬取任务类注入
2.具体如何爬取数据?我们先爬取列表页面的职位列表=====》获取职位详情页URL====>再通过详情页URL爬取职位详情页====》获取职位详情页的具体目标信息===》存入数据库
webMagic执行步骤:通过链接下载页面,解析html,获取其中得元素,再获取元素下得具体职位信息等,具体请去学习webMagic,此处不赘述。
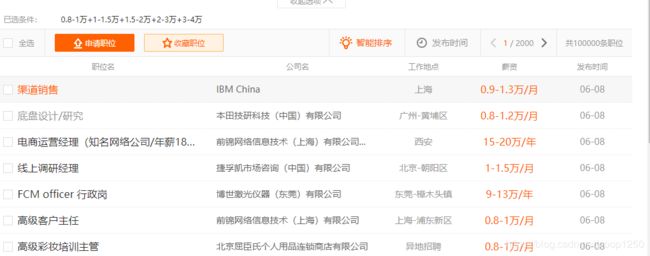

3.有了爬虫爬取的数据,我们将爬取得数据存入数据库
红色框内是我们的要获取的目标信息,建立相应的POJO
JobInfo.class
@Data
public class JobInfo {
private Long Id;
private String jobName;//职位名称
private Integer salaryMin;//工资最小
private Integer salaryMax;//工资最大
private String corpName;//公司名称
private String address;//工作地点
private String time;//发布时间
private String jobInfo;//职位信息
private String link;//联系方式
private String corpInfo;//公司信息
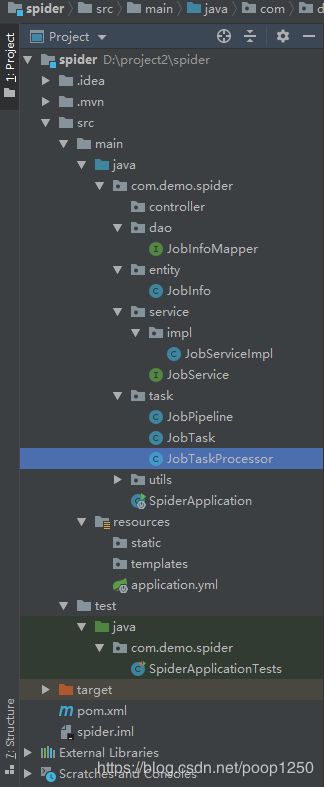
}项目结构:
代码实现:
工程启动会执行JobTask中的定时任务,定时任务中启动了爬虫。爬虫传入的几个参数:
1.Processor
是负责解析爬虫爬取过来的页面
2.Pipeline
爬虫爬取的数据存储的目的地,可以选择控制台,或者文件目录,也可以自己实现。我要存储到数据库,自己写了一个JobPipeline实现存储到数据库
3.Scheduler
对待抓取的URL队列进行管理。
对已抓取的URL进行去重。
4.url
从哪个链接的页面开始抓取,我们从主页面开始抓取,获取列表中每个职位的详情页,再获取翻页按钮进行翻页
5.thread
开启几个线程抓取
@Component
public class JobTask {
@Autowired
private JobPipeline jobPipeline;
@Scheduled(initialDelay = 1000, fixedDelay = 1000 * 100)
private void jobTaskRun() {
Spider.create(new JobTaskProcessor())
.addPipeline(jobPipeline)//保存到数据库
.setScheduler(new QueueScheduler().setDuplicateRemover(new BloomFilterDuplicateRemover(10000000)))//设置去重过滤器
.addUrl("https://search.51job.com/list/020000%252C040000%252C010000%252C080200%252C180200,000000,0000,00,9,99,%2520,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=")
.thread(5)
.run();
}
}
JobPipeline.class
@Component
public class JobPipeline implements Pipeline {
@Autowired
private JobService jobService;
@Override
public void process(ResultItems resultItems, Task task) {
JobInfo jobInfo = resultItems.get("jobInfo");
if(null!=jobInfo){
if(jobInfo.getSalaryMin()>=10000){
jobService.save(jobInfo);
}
}
}
}package com.demo.spider.task;
import com.demo.spider.entity.JobInfo;
import com.demo.spider.service.JobService;
import com.demo.spider.utils.MathSalary;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
import us.codecraft.webmagic.selector.Selectable;
import java.util.List;
//JobTaskProcessor
@Component
public class JobTaskProcessor implements PageProcessor {
private Logger logger = LoggerFactory.getLogger(this.getClass());
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(10000);
@Override
public void process(Page page) {
List nodes = page.getHtml().xpath("//div[@id='resultList']/div[@class='el']").nodes();
if (null == nodes || nodes.size() == 0) {
//详情页
JobInfo jobInfo = saveJobInfo(page.getHtml(), page.getUrl().toString());
page.putField("jobInfo", jobInfo);
} else {
//列表页
for (Selectable node : nodes) {
String detailLink = node.xpath("//p/span/a/@href").get();
logger.info("抓取的详情页链接===》" + detailLink);
if (StringUtils.isNotBlank(detailLink)) {
//将详情页加入到待抓取的爬虫队列中
page.addTargetRequest(detailLink);
}
//将分页链接加入到任务队列中
List pageList = page.getHtml().xpath("//div[@class='dw_page']/div[@class='p_box']/div[@class='p_wp']/div/ul/li").links().all();
page.addTargetRequests(pageList);
}
}
}
//从详情页面抽取信息成pojo
private JobInfo saveJobInfo(Html html, String url) {
JobInfo jobInfo = new JobInfo();
jobInfo.setLink(url);
String jobName = html.xpath("//div[@class='tHeader tHjob']/div[@class='in']/div/h1/text()").get();
jobInfo.setJobName(jobName);
String sclaryStr = html.xpath("//div[@class='tHeader tHjob']/div[@class='in']/div/strong/text()").get();
Integer[] salary = MathSalary.getSalary(sclaryStr);
jobInfo.setSalaryMin(salary[0] / 10);
jobInfo.setSalaryMax(salary[1] / 10);
String corpName = html.xpath("//div[@class='tHeader tHjob']/div[@class='in']/div/p[@class='cname']/a/@title").get();
jobInfo.setCorpName(corpName);
//职位发布时间
String timeStr = html.xpath("//p[@class='msg ltype']/@title").get();
String time = timeStr.substring(timeStr.length() - 7, timeStr.length() - 2);
jobInfo.setTime(time);
List all = html.xpath("//div[@class='bmsg job_msg inbox']/p/text()").all();
String jobInfoStr = "";
for (String s : all) {
jobInfoStr += s;
}
jobInfo.setJobInfo(jobInfoStr);
String address = html.xpath("//div[@class='bmsg inbox']/p/text()").get();
jobInfo.setAddress(address);
String corpInfo = html.xpath("//div[@class='tmsg inbox']/text()").get();
jobInfo.setCorpInfo(corpInfo);
return jobInfo;
}
@Override
public Site getSite() {
return site;
}
}
package com.demo.spider.service.impl;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.demo.spider.dao.JobInfoMapper;
import com.demo.spider.entity.JobInfo;
import com.demo.spider.service.JobService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
@Service
@Transactional
public class JobServiceImpl implements JobService {
@Autowired
private JobInfoMapper jobInfoMapper;
@Override
public void save(JobInfo jobInfo) {
JobInfo wrapper=new JobInfo();
wrapper.setTime(jobInfo.getTime());
wrapper.setLink(jobInfo.getLink());
List jobInfos = jobInfoMapper.selectList(new QueryWrapper<>(wrapper));
if(null==jobInfos||jobInfos.size()==0){
jobInfoMapper.insert(jobInfo);
}
}
}
数据库建表:
CREATE TABLE `job_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`job_name` varchar(150) DEFAULT NULL,
`salary_min` int(8) DEFAULT NULL,
`salary_max` int(8) DEFAULT NULL,
`corp_name` varchar(255) DEFAULT NULL,
`address` varchar(255) DEFAULT NULL,
`time` varchar(50) DEFAULT NULL,
`job_info` text,
`link` varchar(255) DEFAULT NULL,
`corp_info` text,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10656 DEFAULT CHARSET=utf8;
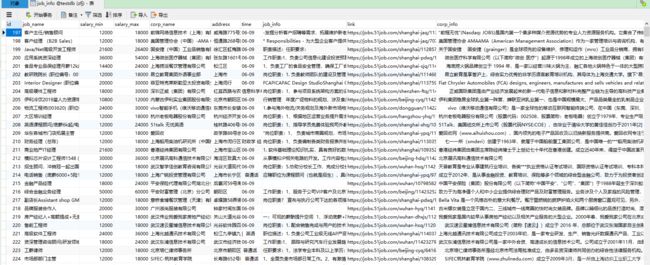
运行项目,数据库爬取数据成功
整合es
application.yml中:
server:
port: 8080
spring:
datasource:
username: root
password: xxxxxxxxxxxxx
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://xxxxxxxxx:3306/testdb?characterEncoding=utf-8
data:
elasticsearch:
cluster-nodes: localhost:9300
mybatis-plus:
mapper-locations: classpath:/mapper/*Mapper.xml
typeAliasesPackage: com.mybatisplus.mybatis_plus.entity
configuration:
#配置返回数据库(column下划线命名&&返回java实体是驼峰命名),自动匹配无需as(没开启这个,SQL需要写as: select user_id as userId)
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
#主键类型 0:"数据库ID自增", 1:"用户输入ID",2:"全局唯一ID (数字类型唯一ID)", 3:"全局唯一ID UUID";
id-type: NONE
启动es后测试
package com.demo.spider;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.demo.spider.dao.JobInfoMapper;
import com.demo.spider.entity.JobInfo;
import esPojo.EsJobInfo;
import com.demo.spider.repository.JobRepository;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.List;
import java.util.Optional;
@RunWith(SpringRunner.class)
@SpringBootTest
public class EsTest {
@Autowired
private JobInfoMapper jobInfoMapper;
@Autowired
private JobRepository jobRepository;
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@Test
public void testCreateIndex() {
elasticsearchTemplate.createIndex(EsJobInfo.class);
}
@Test
public void testPutMapping() {
elasticsearchTemplate.putMapping(EsJobInfo.class);
}
@Test
public void testadd() {
List list = jobInfoMapper.selectPage(new Page<>(1, 50), null).getRecords();
for (JobInfo jobInfo : list) {
EsJobInfo job = new EsJobInfo();
BeanUtils.copyProperties(jobInfo, job);
jobRepository.save(job);
}
}
@Test
public void testUpdate() {
EsJobInfo esJobInfo = new EsJobInfo();
esJobInfo.setId(254L);
esJobInfo.setAddress("测试数据001");
jobRepository.save(esJobInfo);
}
@Test
public void testGet() {
Optional optional = jobRepository.findById(254L);
System.out.println(optional.get());
}
@Test
public void testGetAll() {
Iterable all = jobRepository.findAll();
for (EsJobInfo esJobInfo : all) {
System.out.println(esJobInfo);
}
}
@Test
public void testPage() {
Iterable all = jobRepository.findAll(PageRequest.of(1,10));
System.out.println();
}
@Test
public void findBySalaryMinAndTime() {
List list=jobRepository.findBySalaryMinAndTime(18000,"06-09");
list.stream().forEach(esJobInfo -> System.out.println(esJobInfo));
}
@Test
public void query() {
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("jobName", "java");
Iterable search = jobRepository.search(matchQueryBuilder);
search.forEach(esJobInfo -> System.out.println(esJobInfo));
}
}