搜索引擎算法之Query Similarity (query relevance、查询的相似性或相关性)
目录
介绍:
一、计算相似性的方法很多,最简单是是根据字面的编辑距离来计算相似性。例如:
二、更近一步,很自然想到搜索点击的结果来计算两个Query的相似性。
三、当然我们也可以借助协同过滤的方法,把query和点击item作为一个评分矩阵,按照协同过滤的方法来计算相关性。
四、由于点击数据受到搜索结果的影响,由于排序质量的问题,点击的位置bias,有很多办法来纠正;以及部分Query的点击比较稀疏,商品的点击比较稀疏。
五、第二种方法是用商品向量来表示Query,也有一些方法借鉴了simrank和向量的思想,用词向量来表示Query和Title。
六、如今深度学习大行其道,Query相关性也可以用深度语义网络DSSM (cikm 2013) https://www.cnblogs.com/baiting/p/7195998.html 。
七、我们在推荐算法中看到,一个用户在一个session中点击的商品序列可以用来做embedding ,得到商品id到embedding vector。
八、目前图计算有很多方法。
目录
介绍:
一、计算相似性的方法很多,最简单是是根据字面的编辑距离来计算相似性。例如:
二、更近一步,很自然想到搜索点击的结果来计算两个Query的相似性。
三、当然我们也可以借助协同过滤的方法,把query和点击item作为一个评分矩阵,按照协同过滤的方法来计算相关性。
四、由于点击数据受到搜索结果的影响,由于排序质量的问题,点击的位置bias,有很多办法来纠正;以及部分Query的点击比较稀疏,商品的点击比较稀疏。
五、第二种方法是用商品向量来表示Query,也有一些方法借鉴了simrank和向量的思想,用词向量来表示Query和Title。
六、如今深度学习大行其道,Query相关性也可以用深度语义网络DSSM (cikm 2013) https://www.cnblogs.com/baiting/p/7195998.html 。
7、我们在推荐算法中看到,一个用户在一个session中点击的商品序列可以用来做embedding ,得到商品id到embedding vector。
8、目前图计算有很多方法。
介绍:
关键词是用户使用搜索引擎的常见输入条件,但是用户在搜索的时候不仅仅是用关键词。当你在淘宝上面搜索的时候,可能通过男装、女装类目去搜索。话说当年yahoo 起家的时候就是通过类目导航,但是yahoo小看了关键词搜索,错过了成为第一大搜索引擎的机会。接着说用户在淘宝用关键词搜索之后,还可以点击各种属性、价格区间来搜索。一个完整的Query包括几个部分:关键词、类目、属性(可以有多个)、价格区间、地域限制等。如果要推荐相关Query,我们应该对整个Query去找相关Query。

一、计算相似性的方法很多,最简单是是根据字面的编辑距离来计算相似性。例如:
sim(QA,QB) = 编辑距离(QA->QB) / length(AB) ,显然这种计算相似性的方法误差很大。所以我们可以考虑同义词、单复数、词形还原考虑一部分同义词。但是对于精确的计算两个Query的相似性就无能为力了。
二、更近一步,很自然想到搜索点击的结果来计算两个Query的相似性。
例如QA有一个点击的商品集合,QB有两个点击的商品集合,用点击数量或者点击率作为商品的权重来设计一个向量,这样两个Query就可以通过cosin(vector(QA),vector(QB)) 来计算相关性。还有比较简单的方法是计算两个Query(x和y)在session 中的互信息,PMI(x,y)=p(x,y)/(p(x)*p(y))
三、当然我们也可以借助协同过滤的方法,把query和点击item作为一个评分矩阵,按照协同过滤的方法来计算相关性。
由于协同过滤没有考虑点击的次数信息,因此推荐词的点击次数和原始词的搜索次数、长度可能不够匹配,还需要很多方法来纠正。
四、由于点击数据受到搜索结果的影响,由于排序质量的问题,点击的位置bias,有很多办法来纠正;以及部分Query的点击比较稀疏,商品的点击比较稀疏。
例如simrank,simrank++(http://www.vldb.org/pvldb/1/1453903.pdf)等算法。
前阿里妈妈的yangxudong 文章里面有mapreduce 的实现:https://blog.csdn.net/yangxudong/article/details/24788137 。主要是基于分块矩阵的计算。实现中利用二次排序,做了不少优化。
另外git hub 上面有两个代码:
(1)https://github.com/thunderain-project/examples 其部分代码无法通过编译。
(2)https://blog.csdn.net/dengxing1234/article/details/78933187 编译通过,少量数据可以通过编译,大量数据还无法跑得结果。

五、第二种方法是用商品向量来表示Query,也有一些方法借鉴了simrank和向量的思想,用词向量来表示Query和Title。
例如yahoo研究院的这篇论文《Learning Query and Document Relevance from a Web-scale Click Graph》。

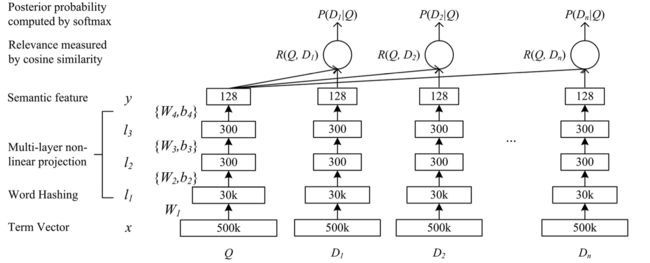
六、如今深度学习大行其道,Query相关性也可以用深度语义网络DSSM (cikm 2013) https://www.cnblogs.com/baiting/p/7195998.html 。
把Query 先和Title 先分别用word hash 到一个3万维的空间,然后一层层embedding 到一个128维的向量, 最后可以简单的用cosin来计算相似性。
七、我们在推荐算法中看到,一个用户在一个session中点击的商品序列可以用来做embedding ,得到商品id到embedding vector。
同时我们可以可以考虑把用户在一个session中输入的Query当成序列来做embedding 。按照这个思路找了一下论文,果然2018年有人用这个想法写了论文。《Querying Word Embeddings for Similarity and Relatedness》http://aclweb.org/anthology/N18-1062
We tested vector spaces with varying dimensionalities (dim=100/200/300) and number of context words (win=3/6/10), as well as minimum occurrence cutoff (min=1/5), negative samples (neg=1/5) and iterations (iter=1/5). These variations were tested to ensure the observed patterns reported in the experiments, but we report numerical results only for best performing models. In particular, higher dimensional vectors with dim=300 produced consistently better alignment with human scoring data. We also found min=1, neg=5 and iter=5 to be the optimal parameter settings across all experiments.
八、目前图计算有很多方法。
我们尝试了用node2vec的方法来计算Query的相似性,也取得了非常好的效果。即把query和item 的二部图上面做node2vec。
另外准备尝试用阿里妈妈的euler平台里面的图embedding方法来计算节点之间相关性。