前言
公司需要对数据进行运营分析,为了满足运营大数据分析的需求,决定采用hadoop进行数据分析查询
经过研究打算采用如下架构
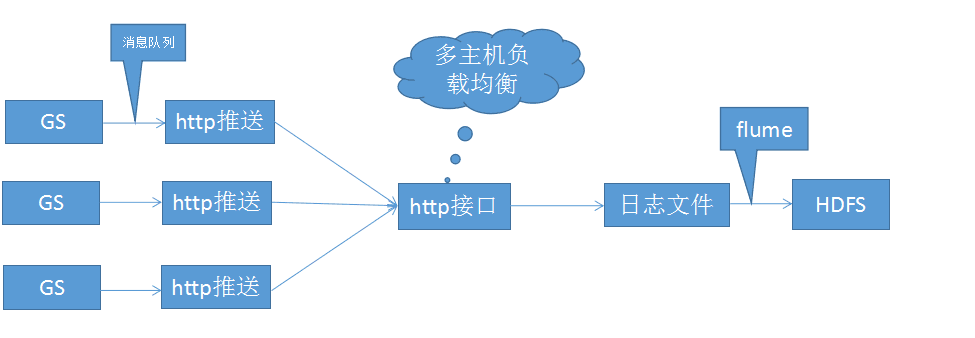
游戏服通过http方式把日志消息写入到BI服务器,BI服务器通过log4j记录日志信息。然后把日志文件导入HDFS中,通过Spark进行数据的统计查询。
这里把日志文件导入HDFS中有两种方法:
1、flume
定时把日志文件拷贝到flume监控的目录下,然后flume就会自动把日志文件导入到HDFS中。
这种方式的优点就是可以配置HDFS文件的大小,不至于生成很多小文件。缺点就是导入速度比较慢,而且如果有大文件移动到flume的监控目录下,会报异常(网上有解决方案),导致flume停止执行。
flume还有其他优点,比如说分布式收集等等;缺点就是遇到异常就会停止执行,大文件拷贝问题,经过测试,拷贝一个400多M的文件到flume监控目录中,如果flume channel采用内存方式,导入到HDFS中需要将近10分钟(单机),如果flume channel采用文件方式,则会超时。但是内存方式又不能保证消息的一致性。
2、shell
可以通过shell脚本直接把日志文件直接通过hadoop fs -put方式直接导入到HDFS中。这种方式的优点就是速度快,简单;缺点就是单机非分布式,日志文件的大小需要自己去控制。日志文件导入成功需要自己去标记。可能还需要对HDFS做小文件合并处理。
本次安装用到的软件版本分别是
hadoop2.6
spark-1.6.1-bin-hadoop2.6
flume1.6
一、Hadoop安装配置
这里讲解的是单机伪分布式配置,具体的配置网上很多,这边就不详细介绍,只讲解一些要点
1、解压hadoop
2、安装JDK7
3、vim /etc/profile ,配置java_home和hadoop_home环境(文章最后有详细配置信息)
4、ssh免密码登陆设置
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
5、修改hadoop配置文件(/hadoop/hadoop-2.6.0/etc/hadoop)
5.1 vim hadoop-env.sh
增加export JAVA_HOME=${JAVA_HOME}
5.2 vim core-site.xml
hadoop.tmp.dir file:/usr/local/hadoop/hadoop-2.6.0/tmp fs.defaultFS hdfs://10.10.31.35:9000 fs.hdfs.impl org.apache.hadoop.hdfs.DistributedFileSystem The FileSystem for hdfs: uris.
5.3 vim hdfs-site.xml
5.4 vim mapred-site.xmldfs.replication 1 dfs.permissions false dfs.namenode.name.dir file:/usr/local/hadoop/hadoop-2.6.0/tmp/dfs/name dfs.datannode.data.dir file:/usr/local/hadoop/hadoop-2.6.0/tmp/dfs/data
5.5 vim yarn-site.xmlmapred.job.tracker 10.10.31.35:9001
mapreduce.framework.name yarn yarn.nodemanager.aux-services mapreduce_shuffle
6、执行NameNode 格式化
./bin/hdfs namenode -format
7、启动hadoop进程
./sbin/start-dfs.sh
到这里hadoop的配置就已经完成了,详细可以参考http://www.powerxing.com/install-hadoop/