Hadoop2.X分布式集群部署
本博文集群搭建没有实现Hadoop HA,详细文档在后续给出,本次只是先给出大概逻辑思路。
(一)hadoop2.x版本下载及安装
Hadoop 版本选择目前主要基于三个厂商(国外)如下所示:
基于Apache厂商的最原始的hadoop版本, 所有发行版均基于这个版本进行改进。
基于HortonWorks厂商的开源免费的hdp版本。
基于Cloudera厂商的cdh版本,Cloudera有免费版和企业版, 企业版只有试用期。不过cdh大部分功能都是免费的。
(二)hadoop2.x分布式集群配置
1.集群资源规划设计

2.hadoop2.x分布式集群配置
1)Hadoop安装配置
先上传资源,并解压。

[kfk@bigdata-pro01 softwares]$ tar -zxf hadoop-2.6.0.tar.gz -C /opt/momdules/
[kfk@bigdata-pro01 softwares]$ cd ../momdules/
[kfk@bigdata-pro01 momdules]$ ll
total 8
drwxr-xr-x 9 kfk kfk 4096 Nov 14 2014 hadoop-2.6.0
drwxr-xr-x 8 kfk kfk 4096 Aug 5 2015 jdk1.8.0_60
[kfk@bigdata-pro01 momdules]$ cd hadoop-2.6.0/
[kfk@bigdata-pro01 hadoop-2.6.0]$ ls
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
接下来对hadoop进行一个瘦身(删除不必要的文件,减小其大小)
[kfk@bigdata-pro01 hadoop-2.6.0]$ cd share/
[kfk@bigdata-pro01 share]$ ls
doc hadoop
[kfk@bigdata-pro01 share]$ rm -rf ./doc/
[kfk@bigdata-pro01 share]$ ls
hadoop
[kfk@bigdata-pro01 share]$ cd ..
[kfk@bigdata-pro01 hadoop-2.6.0]$ ls
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
[kfk@bigdata-pro01 hadoop-2.6.0]$ cd etc/hadoop/
[kfk@bigdata-pro01 hadoop]$ ls
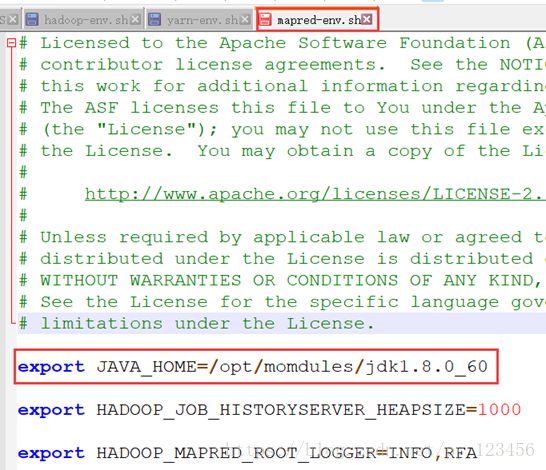
capacity-scheduler.xml hadoop-env.sh httpfs-env.sh kms-env.sh mapred-env.sh ssl-server.xml.example
configuration.xsl hadoop-metrics2.properties httpfs-log4j.properties kms-log4j.properties mapred-queues.xml.template yarn-env.cmd
container-executor.cfg hadoop-metrics.properties httpfs-signature.secret kms-site.xml mapred-site.xml.template yarn-env.sh
core-site.xml hadoop-policy.xml httpfs-site.xml log4j.properties slaves yarn-site.xml
hadoop-env.cmd hdfs-site.xml kms-acls.xml mapred-env.cmd ssl-client.xml.example
[kfk@bigdata-pro01 hadoop]$ rm -rf ./*.cmd //.cmd为Windows下的命令,所以不需要,可以删掉。
2)hadoop2.x分布式集群配置-HDFS
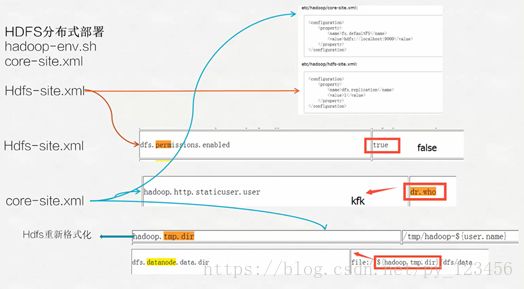
安装hdfs需要修改4个配置文件:hadoop-env.sh、core-site.xml、hdfs-site.xml和slaves
注意:为了方便和正确性的保证,以后Linux中的配置都使用外部工具Notepad++进行(连接之前请保证Windows下的Hosts文件已经添加了网络映射),连接方式如下:




注:如果出现的目录和我的不同,请双击根目录(/)。
在配置的时候再教大家一个小技巧:能够复制粘贴的尽量复制粘贴,这样能尽量避免拼写错误。比如配置hadoop-env.sh文件时可以如下操作:

然后Ctrl+Ins组合键可以实现Linux下的复制操作,粘贴操作用Shift+Ins组合键。

该文件只需配置JAVA_HOME目录即可。

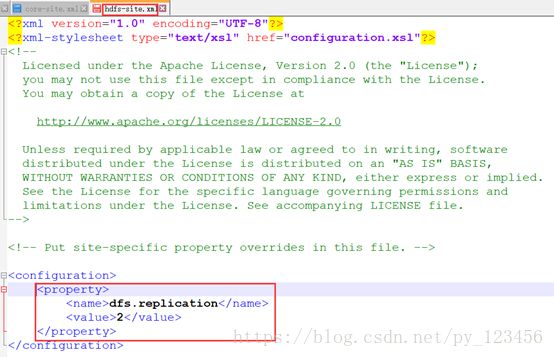
dfs.replication
2
配置Namenode

fs.default.name
hdfs://bigdata-pro01.kfk.com:9000
The name of the default file system, using 9000 port.
配置Datanode

格式化Namenode
[kfk@bigdata-pro01 hadoop]$ cd ..
[kfk@bigdata-pro01 etc]$ cd ..
[kfk@bigdata-pro01 hadoop-2.6.0]$ bin/hdfs namenode –format
启动Namenode和Datanode
[kfk@bigdata-pro01 hadoop-2.6.0]$ sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /opt/momdules/hadoop-2.6.0/logs/hadoop-kfk-namenode-bigdata-pro01.kfk.com.out
[kfk@bigdata-pro01 hadoop-2.6.0]$ sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/momdules/hadoop-2.6.0/logs/hadoop-kfk-datanode-bigdata-pro01.kfk.com.out
[kfk@bigdata-pro01 hadoop-2.6.0]$ jps
21778 NameNode
21927 Jps
21855 DataNode
进入网址:http://bigdata-pro01.kfk.com:50070/dfshealth.html#tab-overview

以上结果表明配置是成功的,然后发送到其他节点。
[kfk@bigdata-pro01 momdules]$ scp -r hadoop-2.6.0/ bigdata-pro02.kfk.com:/opt/momdules/
The authenticity of host 'bigdata-pro02.kfk.com (192.168.86.152)' can't be established.
RSA key fingerprint is b5:48:fe:c4:80:24:0c:aa:5c:f5:6f:82:49:c5:f8:8e.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'bigdata-pro02.kfk.com,192.168.86.152' (RSA) to the list of known hosts.
[email protected]'s password:
[kfk@bigdata-pro01 momdules]$ scp -r hadoop-2.6.0/ bigdata-pro03.kfk.com:/opt/momdules/
然后启动两个子节点的DataNode并刷新网页看看有什么变化。
[kfk@bigdata-pro02 hadoop-2.6.0]$ sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/momdules/hadoop-2.6.0/logs/hadoop-kfk-datanode-bigdata-pro02.kfk.com.out
[kfk@bigdata-pro02 hadoop-2.6.0]$ jps
21655 DataNode
21723 Jps
[kfk@bigdata-pro03 ~]$ cd /opt/momdules/hadoop-2.6.0/
[kfk@bigdata-pro03 hadoop-2.6.0]$ sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/momdules/hadoop-2.6.0/logs/hadoop-kfk-datanode-bigdata-pro03.kfk.com.out
[kfk@bigdata-pro03 hadoop-2.6.0]$ jps
21654 DataNode
21722 Jps

接下来,我们在dfs上创建一个目录并上传一个文件:
[kfk@bigdata-pro01 hadoop-2.6.0]$ bin/hdfs dfs -mkdir -p /user/kfk/data/
18/10/16 09:21:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[kfk@bigdata-pro01 hadoop-2.6.0]$ bin/hdfs dfs -put /opt/momdules/hadoop-2.6.0/etc/hadoop/core-site.xml /user/kfk/data
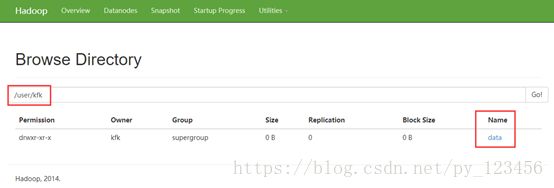

创建和上传都成功!
[kfk@bigdata-pro01 hadoop-2.6.0]$ bin/hdfs dfs -text /user/kfk/data/core-site.xml
18/10/16 13:43:23 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
fs.default.name
hdfs://bigdata-pro01.kfk.com:9000
The name of the default file system, using 9000 port.
文件内容也是完全一致的!
3)hadoop2.x分布式集群配置-YARN
安装yarn需要修改4个配置文件:yarn-env.sh、mapred-env.sh、yarn-site.xml和mapred-site.xml


mapreduce.framework.name
yarn
mapreduce.jobhistory.address
bigdata-pro01.kfk.com:10020
mapreduce.jobhistory.webapp.address
bigdata-pro01.kfk.com:19888

yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
bigdata-pro01.kfk.com
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
10000
(三)分发到其他各个机器节点
hadoop相关配置在第一个节点配置好之后,可以通过脚本命令分发给另外两个节点即可,具体操作如下所示。
#将安装包分发给第二个节点
[kfk@bigdata-pro01 hadoop]$ scp -r ./* [email protected]:/opt/momdules/hadoop-2.6.0/etc/hadoop/
#将安装包分发给第三个节点
[kfk@bigdata-pro01 hadoop]$ scp -r ./* [email protected]:/opt/momdules/hadoop-2.6.0/etc/hadoop/
(四)HDFS启动集群运行测试
[kfk@bigdata-pro01 hadoop]$ cd ..
[kfk@bigdata-pro01 etc]$ cd ..
[kfk@bigdata-pro01 hadoop-2.6.0]$ cd ..
[kfk@bigdata-pro01 momdules]$ cd ..
[kfk@bigdata-pro01 opt]$ cd datas/
[kfk@bigdata-pro01 datas]$ touch wc.input
[kfk@bigdata-pro01 datas]$ vi wc.input
hadoop hive
hive spark
hbase java
[kfk@bigdata-pro01 datas]$ cd ../momdules/hadoop-2.6.0/
[kfk@bigdata-pro01 hadoop-2.6.0]$ bin/hdfs dfs -put /opt/datas/wc.input /user/kfk/data
18/10/16 14:11:57 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable

hdfs相关配置好之后,可以启动resourcemanager和nodemanager。
[kfk@bigdata-pro01 hadoop-2.6.0]$ sbin/yarn-daemon.sh start resourcemanager
Usage: yarn-daemon.sh [--config ] [--hosts hostlistfile] (start|stop)
[kfk@bigdata-pro01 hadoop-2.6.0]$ sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /opt/momdules/hadoop-2.6.0/logs/yarn-kfk-resourcemanager-bigdata-pro01.kfk.com.out
[kfk@bigdata-pro01 hadoop-2.6.0]$ sbin/yarn-daemon.sh start nodemanager
starting nodemanager, logging to /opt/momdules/hadoop-2.6.0/logs/yarn-kfk-nodemanager-bigdata-pro01.kfk.com.out
[kfk@bigdata-pro01 hadoop-2.6.0]$ sbin/mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /opt/momdules/hadoop-2.6.0/logs/mapred-kfk-historyserver-bigdata-pro01.kfk.com.out
[kfk@bigdata-pro01 hadoop-2.6.0]$ jps
21778 NameNode
23668 NodeManager
23701 Jps
23431 ResourceManager
21855 DataNode
23835 JobHistoryServer
[kfk@bigdata-pro02 hadoop-2.6.0]$ sbin/yarn-daemon.sh start nodemanager
starting nodemanager, logging to /opt/momdules/hadoop-2.6.0/logs/yarn-kfk-nodemanager-bigdata-pro02.kfk.com.out
[kfk@bigdata-pro02 hadoop-2.6.0]$ jps
22592 NodeManager
21655 DataNode
22622 Jps
[kfk@bigdata-pro03 hadoop-2.6.0]$ sbin/yarn-daemon.sh start nodemanager
starting nodemanager, logging to /opt/momdules/hadoop-2.6.0/logs/yarn-kfk-nodemanager-bigdata-pro03.kfk.com.out
[kfk@bigdata-pro03 hadoop-2.6.0]$ jps
22566 Jps
21654 DataNode
22536 NodeManager
进入网址:http://bigdata-pro01.kfk.com:8088/cluster/nodes

接下来配置一下DataNode的日志目录。

dfs.permissions.enable
false

hadoop.http.staticuser.user
kfk
hadoop.tmp.dir
/opt/momdules/hadoop-2.6.0/data/tmp
创建目录:
[kfk@bigdata-pro01 hadoop-2.6.0]$ mkdir -p data/tmp
[kfk@bigdata-pro01 hadoop-2.6.0]$ cd data/tmp/
[kfk@bigdata-pro01 tmp]$ pwd
/opt/momdules/hadoop-2.6.0/data/tmp
然后分发配置到其他节点:
由于修改东西并且新建了路径,为了安全起见,先删掉两个节点的hadoop文件夹,全部重发一次吧。
[kfk@bigdata-pro02 momdules]$ rm -rf hadoop-2.6.0/ //注意删除的是02和03节点,别删错了。
然后分发:
scp -r ./hadoop-2.6.0/ [email protected]:/opt/momdules/
scp -r ./hadoop-2.6.0/ [email protected]:/opt/momdules/
格式化NameNode
格式化之前要先停掉所有服务:
[kfk@bigdata-pro01 hadoop-2.6.0]$ sbin/yarn-daemon.sh stop resourcemanager
stopping resourcemanager
[kfk@bigdata-pro01 hadoop-2.6.0]$ sbin/yarn-daemon.sh stop nodemanager
stopping nodemanager
[kfk@bigdata-pro01 hadoop-2.6.0]$ sbin/mr-jobhistory-daemon.sh stop historyserver
stopping historyserver
[kfk@bigdata-pro01 hadoop-2.6.0]$ sbin/hadoop-daemon.sh stop namenode
stopping namenode
[kfk@bigdata-pro01 hadoop-2.6.0]$ sbin/hadoop-daemon.sh stop datanode
stopping datanode
[kfk@bigdata-pro01 hadoop-2.6.0]$ jps
24207 Jps
格式化:
[kfk@bigdata-pro01 hadoop-2.6.0]$ bin/hdfs namenode -format
启动各个节点机器服务
1)启动NameNode命令:
sbin/hadoop-daemon.sh start namenode(01节点)
- 启动DataNode命令:
sbin/hadoop-daemon.sh start datanode(01/02/03节点)

格式化Namenode之后之前建立的路径也就没有了,所有我们要重新创建。
[kfk@bigdata-pro01 hadoop-2.6.0]$ bin/hdfs dfs -mkdir -p /user/kfk/data
3)启动ResourceManager命令:
sbin/yarn-daemon.sh start resourcemanager(01节点)
4)启动NodeManager命令:
sbin/yarn-daemon.sh start nodemanager(01/02/03节点)
5)启动log日志命令:
sbin/mr-jobhistory-daemon.sh start historyserver(01节点)
(五)YARN集群运行MapReduce程序测试
前面hdfs和yarn都启动起来之后,可以通过运行WordCount程序检测一下集群是否能run起来。
重新上传测试文件:
[kfk@bigdata-pro01 hadoop-2.6.0]$ bin/hdfs dfs -put /opt/datas/wc.input /user/kfk/data/
然后创建一个输出目录:
[kfk@bigdata-pro01 hadoop-2.6.0]$ bin/hdfs dfs -mkdir -p /user/kfk/data/output/
使用集群自带的WordCount程序执行命令:
[kfk@bigdata-pro01 hadoop-2.6.0]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /user/kfk/data/wc.input /user/kfk/data/output
18/10/16 15:19:40 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/10/16 15:19:41 INFO client.RMProxy: Connecting to ResourceManager at bigdata-pro01.kfk.com/192.168.86.151:8032
org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://bigdata-pro01.kfk.com:9000/user/kfk/data/output already exists
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:146)
at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:562)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:432)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1296)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1293)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1293)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1314)
at org.apache.hadoop.examples.WordCount.main(WordCount.java:87)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71)
at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144)
at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
运行报错。原因是输出目录已经存在,而MapReduce执行时会检测输出目录是否存在,不存在则自动创建并正常执行;否则报错。所以我们重新运行,在输出目录后再追加一个目录即可。
[kfk@bigdata-pro01 hadoop-2.6.0]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /user/kfk/data/wc.input /user/kfk/data/output/1

点击History可以查看日志


这样就能很方便地查看日志,而不用在命令行进hadoop的logs/目录下去查看了。我们查看一下运行结果:
[kfk@bigdata-pro01 hadoop-2.6.0]$ bin/hdfs dfs -text /user/kfk/data/output/1/par*
18/10/16 16:00:37 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
hadoop 1
hbase 1
hive 2
java 1
spark 1

很明显结果是正确的(上图中黄色为行号,而非文件内容)!
(六)ssh无秘钥登录
在集群搭建的过程中,需要不同节点分发文件,那么节点间分发文件每次都需要输入密码,比较麻烦。另外在hadoop 集群启动过程中,也需要使用批量脚本统一启动各个节点服务,此时也需要节点之间实现无秘钥登录。具体操作步骤如下所示:
1.主节点上创建 .ssh 目录,然后生成公钥文件id_rsa.pub和私钥文件
[kfk@bigdata-pro01 datas]$ cd
[kfk@bigdata-pro01 ~]$ cd .ssh
[kfk@bigdata-pro01 .ssh]$ ls
known_hosts
[kfk@bigdata-pro01 .ssh]$ cat known_hosts
bigdata-pro02.kfk.com,192.168.86.152 ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAsHpzF1vSSqZPIbTKrhsxKGqofgngHbm5MdXItaSEJ8JemIuWrMo5++0g3QG/m/DRW8KqjXhnBO819tNIqmVNeT+0cH7it9Nosz1NWfwvXyNy+lbxdjfqSs+DvMh0w5/ZoiXVdqWmPAh2u+CP4BKbHS4VKRNoZk42B+1+gzXxN6Gt1kxNemLsLw6251IzmsX+dVr8iH493mXRwE9dv069uKoA0HVwn6FL51D8c1H1v1smD/EzUsL72TUknz8DV43iawIBDMSw4GQJFoZtm2ogpCuIhBfLwTfl+5yyzjY8QdwH5sDiKFlPX476M+A1s+mneyQtaaRwORIiOvs7TgtSTw==
bigdata-pro03.kfk.com,192.168.86.153 ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAsHpzF1vSSqZPIbTKrhsxKGqofgngHbm5MdXItaSEJ8JemIuWrMo5++0g3QG/m/DRW8KqjXhnBO819tNIqmVNeT+0cH7it9Nosz1NWfwvXyNy+lbxdjfqSs+DvMh0w5/ZoiXVdqWmPAh2u+CP4BKbHS4VKRNoZk42B+1+gzXxN6Gt1kxNemLsLw6251IzmsX+dVr8iH493mXRwE9dv069uKoA0HVwn6FL51D8c1H1v1smD/EzUsL72TUknz8DV43iawIBDMSw4GQJFoZtm2ogpCuIhBfLwTfl+5yyzjY8QdwH5sDiKFlPX476M+A1s+mneyQtaaRwORIiOvs7TgtSTw==
[kfk@bigdata-pro01 .ssh]$ rm -f known_hosts //保证.ssh目录是干净的
[kfk@bigdata-pro01 .ssh]$ ls
[kfk@bigdata-pro01 .ssh]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/kfk/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/kfk/.ssh/id_rsa.
Your public key has been saved in /home/kfk/.ssh/id_rsa.pub.
The key fingerprint is:
6f:a2:83:da:9d:77:71:e5:29:71:a1:27:0c:7a:8d:b8 [email protected]
The key's randomart image is:
+--[ RSA 2048]----+
| |
| . . |
| o = . . |
| o o * + |
| So B . |
| E.. o o |
| . . oo . |
| ....o.o. |
| ... +o . |
+-----------------+
2.拷贝公钥到各个机器
ssh-copy-id bigdata-pro1.kfk.com
ssh-copy-id bigdata-pro2.kfk.com
ssh-copy-id bigdata-pro3.kfk.com
3.测试ssh连接
ssh bigdata-pro1.kfk.com
ssh bigdata-pro2.kfk.com
ssh bigdata-pro3.kfk.com
[kfk@bigdata-pro01 .ssh]$ ssh bigdata-pro02.kfk.com
Last login: Tue Oct 16 13:17:38 2018 from 192.168.86.1
4.测试hdfs
ssh无秘钥登录做好之后,可以在主节点通过一键启动/停止命令,启动/停止hdfs各个节点的服务,具体操作如下所示:
[kfk@bigdata-pro01 hadoop-2.6.0]$ sbin/stop-dfs.sh
18/10/16 15:52:53 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Stopping namenodes on [bigdata-pro01.kfk.com]
bigdata-pro01.kfk.com: stopping namenode
bigdata-pro03.kfk.com: stopping datanode
bigdata-pro01.kfk.com: stopping datanode
bigdata-pro02.kfk.com: stopping datanode
Stopping secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
RSA key fingerprint is b5:48:fe:c4:80:24:0c:aa:5c:f5:6f:82:49:c5:f8:8e.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (RSA) to the list of known hosts.
0.0.0.0: no secondarynamenode to stop
18/10/16 15:53:17 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[kfk@bigdata-pro01 hadoop-2.6.0]$ sbin/stop-yarn.sh
stopping yarn daemons
stopping resourcemanager
bigdata-pro03.kfk.com: stopping nodemanager
bigdata-pro02.kfk.com: stopping nodemanager
bigdata-pro01.kfk.com: stopping nodemanager
no proxyserver to stop
如果yarn和hdfs主节点共用,配置一个节点即可。否则,yarn也需要单独配置ssh无秘钥登录。
(七)配置集群内机器时间同步(使用Linux ntp进行)
参考博文:https://www.cnblogs.com/zimo-jing/p/8892697.html
注:在三个节点上都要进行操作,还有最后一个命令使用sudo。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!同时也欢迎转载,但必须在博文明显位置标注原文地址,解释权归博主所有!