Ubuntu 17.04 安装Hadoop 3.0.0-beta1
前言
最近要准备一些大数据的赛事,所以需要搭建Hadoop环境.踩了无数坑.终于给弄好了.
jdk的配置
jdk不能安装Ubuntu默认的default-jdk的环境,要从官网上下载,然后搭建JAVA环境,不然jps命令是找不到的.
官网下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
选择版本下载,然后开始搭建环境
jdk-1 解压安装包
- 首先建立一个所有用户都能访问到的目录 sudo mkdir /usr/local/java
- 然后把压缩包移动到刚刚建立的目录中 cp dk-8u151-linux-x64.tar.gz /usr/local/java
- 进入目录 cd /usr/local/java
- 解压压缩包 sudo tar -zxvf dk-8u151-linux-x64.tar.gz
- 删除压缩包 sudo rm -r dk-8u151-linux-x64.tar.gz
jdk-2 配置jdk环境变量
- sudo vim ~/.bashrc
- 在末尾添加如下
export JAVA_HOME=/usr/local/java/jdk1.8.0_151
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH- 需要注意的是,等号两侧不能加入空格,不然会出现”不是有效的标识符”,因为source /etc/profile 不能识别多余的空格,会理解为路径一部分
- 保存,然后source ~/.bashrc
jdk-3 检验是否安装成功
java -verison

配置ssh
这一步是必须要的,不然后期启动时,会出现permission denied publickey password 的错误.
sudo apt-get install openssh-server然后进行下面几个步骤:
- mkdir ~/.ssh
- ssh-keygen -t rsa (四个回车)#生成ssh免登陆密钥
- 执行完这个命令后,在~/.ssh目录下会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
- cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys #将公钥拷贝到要免密登陆的目标机器上
- ssh 主机名(不知道主机名可在控制台输入hostname) #检验无密码登陆是否成功
关于ssh我遇到的一个问题
就是上面说的那个permission denied publickey password 这个错误,后来翻资料是因为.ssh文件夹权限的问题.解决方案
chmod go-w ~/
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys安装Hadoop3.0.0
我选择的是二进制版本在Ubuntu中下载,这样速度快点.
http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.0.0-beta1/hadoop-3.0.0-beta1.tar.gz
wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-3.0.0-beta1/hadoop-3.0.0-beta1.tar.gzHadoop 基本操作
- 解压 tar -zxvf hadoop-3.0.0-beta1.tar.gz -C /opt/
- cd /opt/
- sudo mv hadoop-3.0.0-beta1/ hadoop
- 设置环境变量
sudo vim /etc/profile- 末尾添加
#Hadoop3.0
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin- source /etc/profile
修改配置文件
需要修改的配置文件都在/hadoop/etc/hadoop
1) hadoop-env.sh

注意: /usr/java/jdk1.8为jdk安装路径
2)core-site.xml
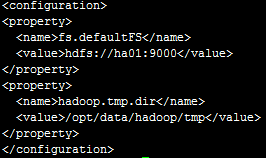
注意:hdfs://ha01:9000 中ha01是主机名
3)hdfs-site.xml

4)yarn-site.xml

注意:ha01是主机名
5)mapred-site.xml
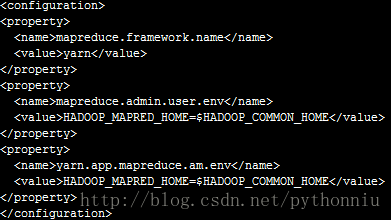
注意:如果不配置mapreduce.admin.user.env 和 yarn.app.mapreduce.am.env这两个参数mapreduce运行时有可能报错。
运行
pythonniu@ubuntu:/opt/hadoop$ ./bin/hdfs namenode -format
pythonniu@ubuntu:/opt/hadoop$ ./sbin/start-dfs.sh
输入地址:
主机名:9870
主机名:8088
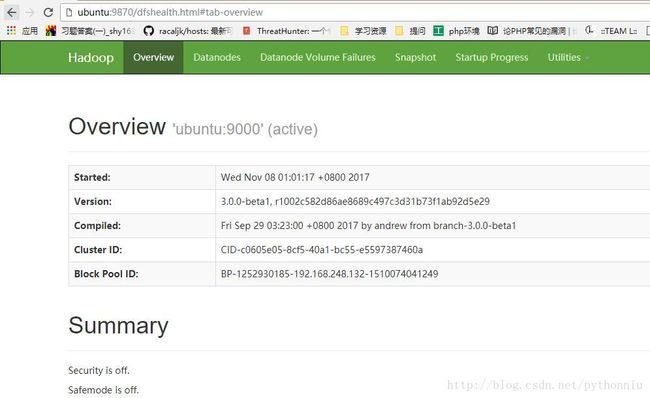
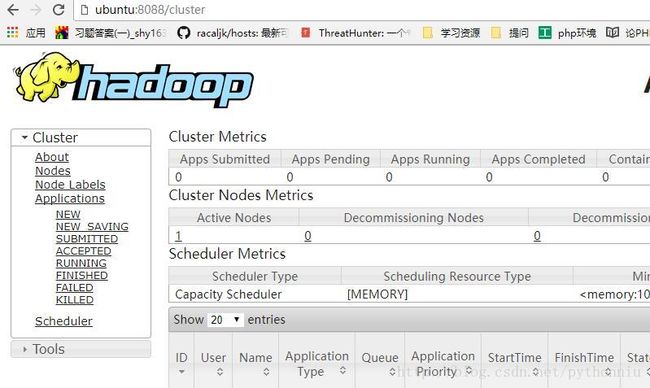
判断是否运行成功
输入命令jps
pythonniu@ubuntu:/opt/hadoop$ jps
6739 ResourceManager
8067 NameNode
8468 SecondaryNameNode
9769 Jps
6876 NodeManager
由此,搭建成功#
WARNING: HADOOP_PREFIX has been replaced by HADOOP_HOME. Using value of HADOOP_PREFIX.
如果出现了这个,直接在/etc/profile 将HADOOP_HOME改为HADOOP_PREFIX就OK了.不用改也可以,毕竟是个警告