drools规则引擎了解
-
什么是规则引擎
规则引擎由推理引擎发展而来,是一种嵌入在应用程序中的组件,实现了将业务决策从应用程序代码中分离出来,并使用预定义的语义模块编写业务决策。接受数据输入,解释业务规则,并根据业务规则做出业务决策。
优点:
l声明式编程
l逻辑和数据分离
l速度和可扩展性
知识集中化
缺点:
l复杂性提高
l需要学习新的规则脚本语法
l引入新组件的风险
-
规则引擎实现
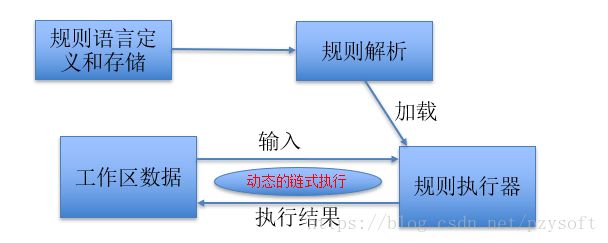
•效率:规则条件的匹配决定了引擎的性能。
•算法:Charles L. Forgy发明了一种叫Rete的算法,解决了这个问题。
•常见的规则引擎产品:
开源的drools、JLisa、QlExpress,商业的Ilog、旗正等。
表达式引擎Aviator。
-
drools规则引擎
Drools是一款基于java语言的开源规则引擎,基于RETE算法实现。
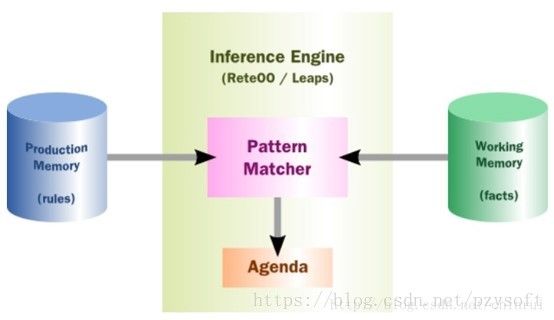
由工作区数据及规则库在推理引擎中进行模式匹配,进而生成agenda,包含了中间结果数据。
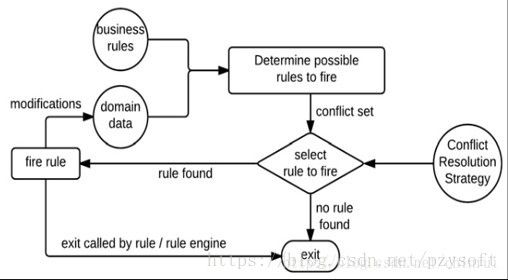
它是一个动态的链式执行过程,中间结果数据继续匹配规则,进而产生结果,直到最终退出返回结果。
-
drools规则文件 一般是drl文件
package package-name(必须)
imports (需要导入的类名)
globals (全局变量)
functions (函数)
queries (查询)
rule “name”
attributes ---->属性:定义当前规则执行的一些属性等
when
LHS ---->条件
then
RHS ---->结果
end
简单介绍一个例子:
rule "rule1"
when
$customer:Customer(age>20,gender=="male")
Order(customer==$customer,price>1000)
then
end
语法说明:
ØCondition中多个pattern默认是and的约束。
Ø对象内部的多个约束连接 “&&”(and),“||”(or)和“,”(and)来实现。
Ø12个类型比较操作符 >|<,>=|<=,==|!=,contains|not contains,memberOf|not memberOf,matches|not matches
还可以根据业务的需要继承BaseEvaluator实现自定义的操作符。
Øattribute说明(常用)
salience优先级 :值越大 ,优先级越高
no-loop防止死循环
lock-on-active规则执行一次
Dialect方言
Enabled是否可用
agenda-group议程分组 auto-focus焦点分组
ØDrools函数
内置函数: insert, update, retract
自定义函数 function
还可以调用外部的java类的静态方法(类需要import进来)。
ØDrools类型声明
declare Address
number:int
streetName:String
city:String
end
规则解析:
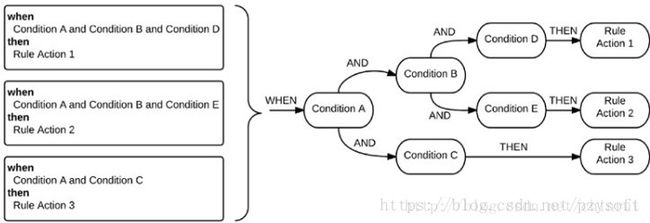
优缺点:
Ø优点
策略规则和执行逻辑的解耦
语法简单,功能强大,可扩展
Ø缺点
语法语言偏向开发人员,具体业务分析人员不容易介入
规模大了也不好维护
另外针对规则文件语法一般需要开发人员编写,drools也提供了决策表及自然语言的机制:
决策表:
决策表就是一个excel文件,可以是xls(xlsx暂不支持)或者csv是个表格,看上去也很直观,即便是不懂代码的人看了也能看懂,不像drl文件那么多语法。关键的一点是:decisiontable也是最终转成drl文件来让drools规则引擎来解析执行的。
自然语言:
ØDslr文件:业务人员编写的规则文件,通过文字描述业务规则。
ØDsl文件:解析业务人员编写的业务规则。
-
drools开发
drools配置文件:
kmodule.xml文件
Ø位于META-INF目录下,用来描述drl文件
Ø示例:
xml version="1.0" encoding="UTF-8"?>
<kmodule xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.drools.org/xsd/kmodule">
<kbase name="HelloKB" packages="drools.rules.helloworld">
<ksession name="HelloWorldKS"/>
kbase>
kmodule>
主要的依赖包:
Økie-api.jar:提供给外部使用的API,接口和工厂。
Økie-internal-api.jar:内部接口和工厂方法。
Ødrools-core.jar:核心引擎,运行时组件
Ødrools-compiler.jar:包含编译器/构建器组件,以获取规则源并构建可执行的规则库
Økie-spring.jar:方便使用spring进行管理而提供一些注解、bean管理的方法
Ø Drools允许我们以不用的方式创建规则引擎的实例,每一个规则引擎都是一个密封的上下文,定义的规则在特定的实例中运行,另一方面来说drools也允许生成轻量级的实例,通常不同的规则和数据由不同的规则引擎实例执行。
ØKieServices:
通过服务注册表,提供整体的入口,可以创建Container等。
ØKieContainer:
KieContainer就是一个KieBase的容器,可以根据kmodule.xml 里描述的KieBase信息来获取具体的KieSession。
KieContainer可以承载多个KieModule,也就是装载不同的规则集。
ØKieModule: 是一个包含了多个kiebase定义的容器。一般用kmodule.xml来表示。
ØKieBase: 是一个知识仓库,包含了若干的规则、流程、方法等
ØKieSession: 直接跟规则引擎打交道的会话,轻量级的组件,执行完销毁。
Ø
1. 有状态KieSession
KieSession会在多次与规则引擎进行交互中,维护会话状态,type属性值是stateful,最后需要清理KieSession维护的状态,调用dispose()方法。
2.无状态StatelessKieSession
StatelessKieSession隔离了每次与规则引擎的交互,不会维护会话状态,无副作用,type属性值是stateless;应用场景:数据校验,运算,数据过滤,任何能被描述成函数或公式的规则。
drools动态规则处理:
Ø规则生成
velocity等模板引擎或者自定义一些页面上处理规则,动态生成
drl规则数据。
Ø规则存储
可以把规则文件内容存储在数据库中或者分布式缓存。
Ø规则引擎
最主要是性能的考虑,针对一组规则缓存对应的容器对象。
drools遇到的坑:
u内存溢出
最主要的是drools形成鉴别网络的时候,保留中间结果,所以在处理大数据量的时候,记得对无效数据进行清理。
另外动态生成的类对象也会影响永久代或者元数据区内存。
u跟其它组件冲突
跟spring-boot-devtools冲突
总结:
drools它是一个针对复制规则业务的规则引擎,相对比较重量级的开源组件,如果只是简单的表达式匹配处理,可以用aviator等表达式引擎。