HashMap详解( JDK8 之前与之后对比)
HashMap简介
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。
此外,HashMap中的映射不是有序的。
HashMap 的实例有两个参数影响其性能:“初始容量” 和 “加载因子”。容量 是哈希表中桶的数量,初始容量 只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
关于hashcode和HashMap的hash算法参考博客:
https://blog.csdn.net/q5706503/article/details/85114159
HashMap的构造函数
// 默认构造函数。
HashMap()
// 指定“容量大小”的构造函数
HashMap(int capacity)
// 指定“容量大小”和“加载因子”的构造函数
HashMap(int capacity, float loadFactor)
// 包含“子Map”的构造函数
HashMap(Map map)HashMap的API ( JDK8 )
| 修饰符和类型 | 方法和描述 |
|---|---|
void |
clear() 从此映射中删除所有映射。 |
Object |
clone() 返回此HashMap实例的浅克隆:未克隆键和值本身。 |
V |
compute(K key, BiFunction remappingFunction) 尝试计算指定键及其当前映射值的映射(或者 |
V |
computeIfAbsent(K key, Function mappingFunction) 如果指定的键尚未与值关联(或映射到 |
V |
computeIfPresent(K key, BiFunction remappingFunction) 如果指定键的值存在且为非null,则尝试在给定键及其当前映射值的情况下计算新映射。 |
boolean |
containsKey(Object key) 如果此映射包含指定键的映射,则返回true。 |
boolean |
containsValue(Object value) 如果此映射将一个或多个键映射到指定值,则返回true。 |
Set |
entrySet() 返回 |
void |
forEach(BiConsumer action) 对此映射中的每个条目执行给定操作,直到处理完所有条目或操作引发异常。 |
V |
get(Object key) 返回指定键映射到的值,或者 |
V |
getOrDefault(Object key, V defaultValue) 返回指定键映射到的值,或者 |
boolean |
isEmpty() 如果此映射不包含键 - 值映射,则返回true。 |
Set |
keySet() 返回 |
V |
merge(K key, V value, BiFunction remappingFunction) 如果指定的键尚未与值关联或与null关联,则将其与给定的非空值关联。 |
V |
put(K key, V value) 将指定的值与此映射中的指定键相关联。 |
void |
putAll(Map m) 将指定映射中的所有映射复制到此映射。 |
V |
putIfAbsent(K key, V value) 如果指定的键尚未与值关联(或映射到 |
V |
remove(Object key) 从此映射中删除指定键的映射(如果存在)。 |
boolean |
remove(Object key, Object value) 仅当指定键当前映射到指定值时才删除该条目的条目。 |
V |
replace(K key, V value) 仅当指定键当前映射到某个值时,才替换该条目的条目。 |
boolean |
replace(K key, V oldValue, V newValue) 仅当前映射到指定值时,才替换指定键的条目。 |
void |
replaceAll(BiFunction function) 将每个条目的值替换为在该条目上调用给定函数的结果,直到所有条目都已处理或函数抛出异常。 |
int |
size() 返回此映射中键 - 值映射的数量。 |
Collection |
values() 返回 |
关于entry, entrySet()的说明和map的遍历可以参考我的另一篇博客:
https://blog.csdn.net/q5706503/article/details/85122343
JDK8中Entry的名字变成了Node( Node类是HashMap的一个静态内部类,实现了 Map.Entry
HashMap的继承关系
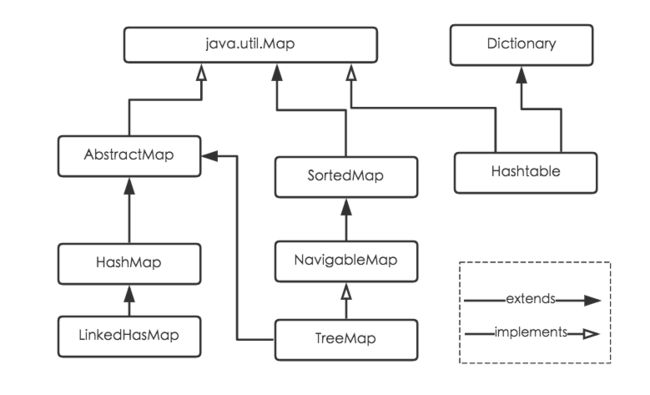
说明:
HashMap继承于AbstractMap类,实现了Map接口。
Map是"key-value键值对"接口,AbstractMap实现了"键值对"的通用函数接口。
影响HashMap性能的有两个参数:初始容量(initialCapacity) 和加载因子(loadFactor)。容量 是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
关于版本说明:
HashMap就是一个散列表, 在JAVA8之前它是通过“拉链法”解决哈希冲突的。
Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由 数组+链表+红黑树 组成。
Java7 HashMap 查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为 O(n) 。
为了降低这部分的开销,在 Java8 中,当链表中的元素超过了 8 个以后,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。
JDK8中,当同一个hash值的节点数不小于8时,将不再以单链表的形式存储了,会被调整成一颗红黑树(上图中null节点没画)。这就是JDK7与JDK8中HashMap实现的最大区别。
JDK8中Entry的名字变成了Node( Node类是HashMap的一个静态内部类,实现了 Map.Entry
HashMap使用示例:
以下示例基于jdk1.7, 取自文尾引用的博客
import java.util.Map;
import java.util.Random;
import java.util.Iterator;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map.Entry;
import java.util.Collection;
/*
* @desc HashMap测试程序
*
* @author skywang
*/
public class HashMapTest {
public static void main(String[] args) {
testHashMapAPIs();
}
private static void testHashMapAPIs() {
// 初始化随机种子
Random r = new Random();
// 新建HashMap
HashMap map = new HashMap();
// 添加操作
map.put("one", r.nextInt(10));
map.put("two", r.nextInt(10));
map.put("three", r.nextInt(10));
// 打印出map
System.out.println("map:"+map );
// 通过Iterator遍历key-value
Iterator iter = map.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
System.out.println("next : "+ entry.getKey() +" - "+entry.getValue());
}
// HashMap的键值对个数
System.out.println("size:"+map.size());
// containsKey(Object key) :是否包含键key
System.out.println("contains key two : "+map.containsKey("two"));
System.out.println("contains key five : "+map.containsKey("five"));
// containsValue(Object value) :是否包含值value
System.out.println("contains value 0 : "+map.containsValue(new Integer(0)));
// remove(Object key) : 删除键key对应的键值对
map.remove("three");
System.out.println("map:"+map );
// clear() : 清空HashMap
map.clear();
// isEmpty() : HashMap是否为空
System.out.println((map.isEmpty()?"map is empty":"map is not empty") );
}
}(某一次)运行结果:
map:{two=7, one=9, three=6}
next : two - 7
next : one - 9
next : three - 6
size:3
contains key two : true
contains key five : false
contains value 0 : false
map:{two=7, one=9}
map is empty我们来看下JDK8中HashMap的源码实现
Entry的名字变成了Node,原因是和红黑树的实现TreeNode相关联。
transient Node[] table; 当冲突节点数不小于8-1时,转换成红黑树。
static final int TREEIFY_THRESHOLD = 8;以put方法在JDK8中有了很大的改变
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab;
Node p;
int n, i;
//如果当前map中无数据,执行resize方法。并且返回n
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果要插入的键值对要存放的这个位置刚好没有元素,那么把他封装成Node对象,放在这个位置上就完事了
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//否则的话,说明这上面有元素
else {
Node e; K k;
//如果这个元素的key与要插入的一样,那么就替换一下,也完事。
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//1.如果当前节点是TreeNode类型的数据,执行putTreeVal方法
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
//还是遍历这条链子上的数据,跟jdk7没什么区别
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//2.完成了操作后多做了一件事情,判断,并且可能执行treeifyBin方法
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null) //true || --
e.value = value;
//3.
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//判断阈值,决定是否扩容
if (++size > threshold)
resize();
//4.
afterNodeInsertion(evict);
return null;
} 其中treeifyBin()就是将链表转换成红黑树。
之前的indefFor()方法消失 了,直接用(tab.length-1)&hash,所以看到这个,代表的就是数组的下角标。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}觉得不够详细可以看看以下大佬的:
http://www.importnew.com/20386.html
https://www.cnblogs.com/yangming1996/p/7997468.html
下面的有JDK8的部分HashMap源码分析
https://blog.csdn.net/fighterandknight/article/details/61624150
https://blog.csdn.net/zxt0601/article/details/77413921
参考以下博客:
http://www.cnblogs.com/skywang12345/p/3310835.html
http://www.importnew.com/23164.html