hadoop(十四)kafaka消息队列
kafka笔记
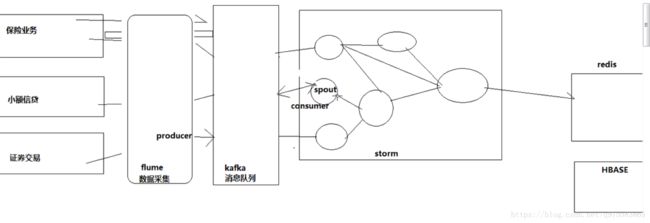
1/kafka是一个分布式的消息缓存系统
2/kafka集群中的服务器都叫做broker
3/kafka有两类客户端,一类叫producer(消息生产者),一类叫做consumer(消息消费者),客户端和broker服务器之间采用tcp协议连接
4/kafka中不同业务系统的消息可以通过topic进行区分,而且每一个消息topic都会被分区,以分担消息读写的负载
5/每一个分区都可以有多个副本,以防止数据的丢失
6/某一个分区中的数据如果需要更新,都必须通过该分区所有副本中的leader来更新
7/消费者可以分组,比如有两个消费者组A和B,共同消费一个topic:order_info,A和B所消费的消息不会重复
比如 order_info 中有100个消息,每个消息有一个id,编号从0-99,那么,如果A组消费0-49号,B组就消费50-99号
8/消费者在具体消费某个topic中的消息时,可以指定起始偏移量
集群安装
1、解压
2、修改server.properties
broker.id=1
zookeeper.connect=weekend05:2181,weekend06:2181,weekend07:2181
3、将zookeeper集群启动
4、在每一台节点上启动broker
bin/kafka-server-start.sh config/server.properties
5、在kafka集群中创建一个topic
bin/kafka-topics.sh --create --zookeeper weekend05:2181 --replication-factor 3 --partitions 1 --topic order
6、用一个producer向某一个topic中写入消息
bin/kafka-console-producer.sh --broker-list weekend:9092 --topic order
7、用一个comsumer从某一个topic中读取信息
bin/kafka-console-consumer.sh --zookeeper weekend05:2181 --from-beginning --topic order
8、查看一个topic的分区及副本状态信息
bin/kafka-topics.sh --describe --zookeeper weekend05:2181 --topic order
java客户端编程
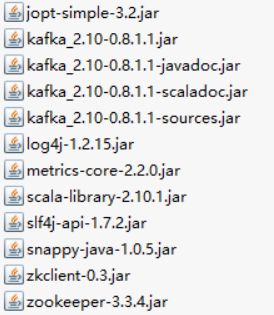
依赖jar
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class ProducerDemo {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put("zk.connect", "weekend01:2181,weekend02:2181,weekend03:2181");
props.put("metadata.broker.list","weekend01:9092,weekend02:9092,weekend03:9092");
props.put("serializer.class", "kafka.serializer.StringEncoder");
ProducerConfig config = new ProducerConfig(props);
Producer producer = new Producer(config);
// 发送业务消息
// 读取文件 读取内存数据库 读socket端口
for (int i = 1; i <= 100; i++) {
Thread.sleep(500);
producer.send(new KeyedMessage("wordcount",
"i said i love you baby for" + i + "times,will you have a nice day with me tomorrow"));
}
}
} import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.message.MessageAndMetadata;
public class ConsumerDemo {
private static final String topic = "mysons";
private static final Integer threads = 1;
public static void main(String[] args) {
Properties props = new Properties();
props.put("zookeeper.connect", "weekend01:2181,weekend02:2181,weekend03:2181");
props.put("group.id", "1111");
props.put("auto.offset.reset", "smallest");
ConsumerConfig config = new ConsumerConfig(props);
ConsumerConnector consumer =Consumer.createJavaConsumerConnector(config);
Map topicCountMap = new HashMap();
topicCountMap.put(topic, 1);
topicCountMap.put("mygirls", 1);
topicCountMap.put("myboys", 1);
Map>> consumerMap = consumer.createMessageStreams(topicCountMap);
List> streams = consumerMap.get("mygirls");
for(final KafkaStream kafkaStream : streams){
new Thread(new Runnable() {
@Override
public void run() {
for(MessageAndMetadata mm : kafkaStream){
String msg = new String(mm.message());
System.out.println(msg);
}
}
}).start();
}
}
} 整合storm
一般是kafaka将消息传递给storm的spout组件
依赖jar: storm-kafka-0.9.2-incubating.jar 等等。。。。
config.properties
zkConnect=master:2181
zkSessionTimeoutMs=30000
zkConnectionTimeoutMs=30000
zkSyncTimeMs=5000
scheme=date,id,content
separator=,
target=date
bolt
import org.apache.commons.lang.StringUtils;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class WordSpliter extends BaseBasicBolt {
private static final long serialVersionUID = -5653803832498574866L;
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String line = input.getString(0);
String[] words = line.split(" ");
for (String word : words) {
word = word.trim();
if (StringUtils.isNotBlank(word)) {
word = word.toLowerCase();
collector.emit(new Values(word));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}import java.io.FileWriter;
import java.io.IOException;
import java.util.Map;
import java.util.UUID;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple;
/**
* 将数据写入文件
* @author [email protected]
*
*/
public class WriterBolt extends BaseBasicBolt {
private static final long serialVersionUID = -6586283337287975719L;
private FileWriter writer = null;
@Override
public void prepare(Map stormConf, TopologyContext context) {
try {
writer = new FileWriter("c:\\storm-kafka\\" + "wordcount"+UUID.randomUUID().toString());
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String s = input.getString(0);
try {
writer.write(s);
writer.write("\n");
writer.flush();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}spout
import java.io.UnsupportedEncodingException;
import java.util.List;
import backtype.storm.spout.Scheme;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
public class MessageScheme implements Scheme {
private static final long serialVersionUID = 8423372426211017613L;
@Override
public Listtopology
import storm.kafka.BrokerHosts;
import storm.kafka.KafkaSpout;
import storm.kafka.SpoutConfig;
import storm.kafka.ZkHosts;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.spout.SchemeAsMultiScheme;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
import cn.itcast.storm.bolt.WordSpliter;
import cn.itcast.storm.bolt.WriterBolt;
import cn.itcast.storm.spout.MessageScheme;
public class KafkaTopo {
public static void main(String[] args) throws Exception {
String topic = "wordcount";
String zkRoot = "/kafka-storm";
String spoutId = "KafkaSpout";
BrokerHosts brokerHosts = new ZkHosts("weekend01:2181,weekend02:2181,weekend03:2181");
SpoutConfig spoutConfig = new SpoutConfig(brokerHosts, "wordcount", zkRoot, spoutId);
spoutConfig.forceFromStart = true;
spoutConfig.scheme = new SchemeAsMultiScheme(new MessageScheme());
TopologyBuilder builder = new TopologyBuilder();
//设置一个spout用来从kaflka消息队列中读取数据并发送给下一级的bolt组件,此处用的spout组件并非自定义的,而是storm中已经开发好的KafkaSpout
builder.setSpout("KafkaSpout", new KafkaSpout(spoutConfig));
builder.setBolt("word-spilter", new WordSpliter()).shuffleGrouping(spoutId);
builder.setBolt("writer", new WriterBolt(), 4).fieldsGrouping("word-spilter", new Fields("word"));
Config conf = new Config();
conf.setNumWorkers(4);
conf.setNumAckers(0);
conf.setDebug(false);
//LocalCluster用来将topology提交到本地模拟器运行,方便开发调试
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("WordCount", conf, builder.createTopology());
//提交topology到storm集群中运行
// StormSubmitter.submitTopology("sufei-topo", conf, builder.createTopology());
}
}utils
import java.io.InputStream;
import java.util.Properties;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
/**
* 属性配置读取工具
*/
public class PropertyUtil {
private static final Log log = LogFactory.getLog(PropertyUtil.class);
private static Properties pros = new Properties();
// 加载属性文件
static {
try {
InputStream in = PropertyUtil.class.getClassLoader().getResourceAsStream("config.properties");
pros.load(in);
} catch (Exception e) {
log.error("load configuration error", e);
}
}
/**
* 读取配置文中的属性值
* @param key
* @return
*/
public static String getProperty(String key) {
return pros.getProperty(key);
}
}