WSWP(用python写网络爬虫)笔记 一:实现简单爬虫
wswp中的代码是通过python2的语法来写的,在学习的过程中个人比较喜欢python3,因此准备将wswp的示例代码用python3重写一遍,以加深映像。
开始尝试构建爬虫
识别网站所用技术和网站所有者
构建网站所使用的技术类型的识别和寻找网站所有者很有用处,比如web安全渗透测试中信息收集的环节对这些信息的收集将对后续的渗透步骤有很重要的作用。对于爬虫来说,识别网站所使用的技术和网站所有者虽然不是很重要,但也能从中获取到很多信息。
检查构建网站的技术类型可通过一个很有用的模块builtwith中的函数来实现。
pip install builtwith需要注意的是,python3中安装好builtwith以后需对builtwith的__init__.py文件进行纠错处理,写一个测试代码根据代码运行报错进行修改就行了。修改完成后,便能使用其中的函数进行解析处理了。
import builtwith
print(builtwith.parse('http://example.webscraping.com')结果如下:
![]()
寻找网站所有者可通过python-whois模块中的函数进行解析。
pip install python-whois测试代码如下:
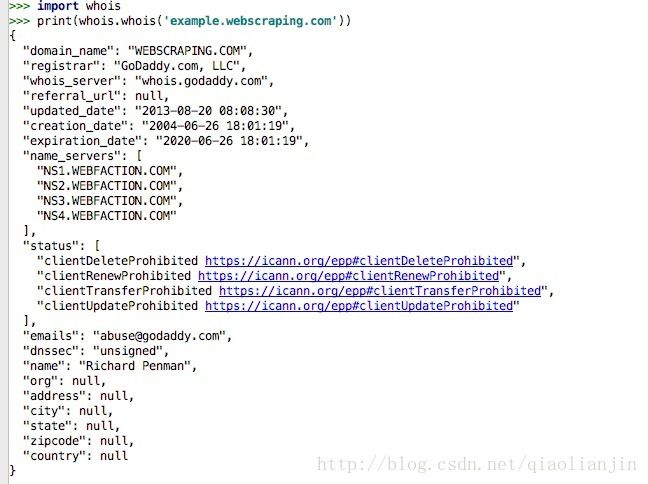
import whois
print(whois.whois('example.webscraping.com')结果如下:
第一个爬虫
python3中将urllib2模块的函数集成到了urllib模块中,通过不同的分类进行更细化的管理。
下载网页
爬虫进行网页数据爬取的第一个步骤便是先将网页下载下来。
# download_v1
import urllib.request
def download(url):
return urllib.request.urlopen(url).read()当传入需要下载的url时,上述函数可将对应的网页下载并返回其html。但是上述函数并没有对可能遇到的异常情况进行处理,比如页面不存在,为了避免这些异常,改进版如下:
# downloader.py
# download_v2
import urllib.request
import urllib.error
def download(url):
print("正在下载:", url)
try:
html = urllib.request.urlopen(url).read()
except urllib.error.URLError as e:
print("下载错误:", e.reason)
html = None
return html将上述代码写进一个文件,将此文件当做模板使用即可进行测试。
通过mian文件引入上述函数,对一个不存在的网页进行访问:
# main.py
from downloader import download
if __name__ == '__main__':
url = 'http://www.freebuf.com/articles/rookie/151327.html'
html = download(url)
print(html)结果如下:

重试下载
爬虫在爬取数据时遇到某些错误是临时性的,比如 503 Service Unavailable错误。对于临时错误可通过尝试重新下载。
添加重试下载功能的下载函数如下:
# downloader.py
# download_v3
import urllib.request
import urllib.error
def download(url, num_retries=3):
print("正在下载:", url)
try:
html = urllib.request.urlopen(url).read()
except urllib.error.URLError as e:
print("下载错误:", e.reason)
html = None
if num_retries > 0:
if hasattr(e, 'code') and 500<=e.code<600:
# 只对5xx错误进行重新下载尝试
return download(url, num_retries - 1)
return html测试url: http://httpsytat.us/500 ,结果如下:

设置用户代理
一些网站会对python使用的默认代理进行禁封,因此需要控制用户代理的控制。
# downloader.py
# download_with_useragent
import urllib.request
import urlllib.error
def download(url, user_agent='wswp', num_retries=2):
print('正在下载:', url)
headers = {'User-agent':user-agent}
request = urllib.request.Request(url, headers=headers)
try:
html = urllib.request.urlopen(request).read()
except urllib.error.URLError as e:
print('下载错误:', e.reason)
html = None
if num_retries > 0:
if hasattr(e, 'code') and 500<=e.code<600:
# 针对5xx错误进行重新下载
return download(url, user_agent, num_retries - 1)
return html链接爬虫
通过跟踪所有链接的方式,可以很容易的下载整个网页的页面,通过正则表达式确定哪些页面需要下载。
# linkCrawler.py
import re
from downloader import download
def get_links(html):
"""
返回html中所有的链接
"""
webpage_regex = re.compile(', re.IGNORECASE)
# Python3中默认返回的数据为bytes,需要转换为str
return webpage_regex.findall(str(html))
def linkCrawler(seed_url, link_regex):
"""
seed_url: 需要爬取的第一个url
link_regex: 链接匹配的正则表达式
"""
crawl_queue = [seed_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
for link in get_links(html):
if re.match(link_regex, link):
crawl_queue.append(link) 测试结果如下:
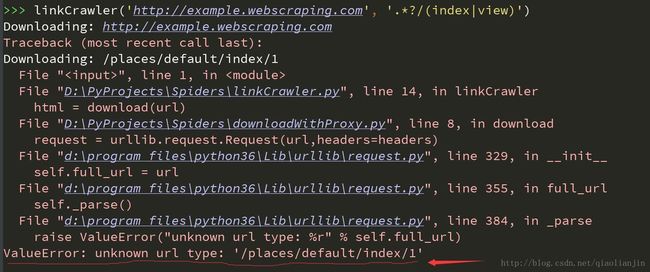
可以看出当下载 ‘/places/default/index/1’这个链接的时候出错了,因为这只是链接的路径部分,没有协议和服务器部分,也就是说这是一个相对连接。如果需正确的爬取,则需要将此链接转换为绝对链接的形式。
#linkCrawlwer.py
# linkCrawler_v2
# 在上一步的函数中修改如下内容
# 添加
import urllib.parse
def linkCrawler(seed_url, link_regex):
crawl_queue = [seed_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
# filter for links matching our regular expression
for link in get_links(html):
if re.match(link_regex, link):
mLink = urllib.parse.urljoin(seed_url, link)
crawl_queue.append(mLink)测试结果如下:
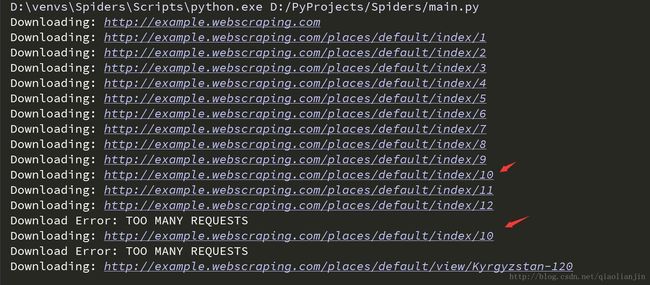
由结果可以看出,出现了重复的爬取。为什么呢?因为在这些链接中相互之间存在链接。为了避免重复爬取相同发的链接,需要去重处理。修改后的linkCrawler函数如下:
def linkCrawler(seed_url, link_regex):
crawl_queue = [seed_url]
# 通过set类型进行去重处理
seen = set(crawl_queue)
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
for link in get_links(html):
if re.match(link_regex, link):
link = urllib.parse.urljoin(seed_url, link)
if link not in seen:
seen.add(link)
crawl_queue.add(link)到此为止,第一个简单的爬虫已经实现了,虽然功能还有点简陋,只是爬取网页的链接,在后面通过添加功能便能使这个爬虫的功能更加强大。
高级功能
解析robots.txt
通过解析robots.txt文件,避免下载禁止爬取的URL,通过python自带的robotparser模块就能轻松完成这项工作。
import urllib.robotparser
rp = urllib.robotparser.RobotFileParser()
rp.set_url('http://example.webscraping.com/robotx.txt')
print(rp.reader())
# 可通过can_fentch()函数确定制定的用户代理是否允许访问网页
url = 'http://example.webscraping.com'
user_agent = 'BadCrawler'
print(rp.can_fetch(user_agent, url))如果希望爬虫只爬取robots.txt中规定可访问的页面,则可以在linkCrawler中获取link的时候进行判断。
支持代理
有时候访问的网站需要通过代理才能访问。添加代理参数的download函数如下:
# downloader.py
import urllib.request
import urllib.error
import urllib.parse
def download(url, user_agent='wswp', proxy=None, num_retries=2):
print("Downloading:", url)
headers = {'User-agent': user_agent}
request = urllib.request.Request(url,headers=headers)
opener = urllib.request.build_opener()
if proxy:
proxy_params = { urllib.parse.urlparse(url).scheme: proxy}
opener.add_handler(urllib.request.ProxyHandler(proxy_params))
try:
#html = urlopen(request).read()
html = opener.open(request).read()
except urllib.error.URLError as e:
print("Download Error:", e.reason)
html = None
if num_retries > 0:
if hasattr(e, 'code') and 500 <= e.code < 600:
download(url,user_agent, proxy, num_retries - 1)
return html下载限速
如果爬取网站的速度过快,可能会面临被禁止访问或者是服务器过载的情况。为了降低这些风险,可在两次下载之间添加延时。
# Throttle.py
import urllib.parse
import datetime
import time
class Throttle:
"""
对一个域名访问时在前后两次访问之间添加一个延时。
"""
def __init__(self, delay):
self.delay = delay
# 同一个域名的上一次访问时间
self.domains = {}
def wait(self, url):
domain = urllib.parse.urlparse(url).netloc
last_accessed = self.domains.get(domain)
if self.delay > 0 and last_accessed is not None:
sleep_secs = self.delay - (datetime.datetime.now() - last_accessed).seconds
if sleep_secs > 0:
# 域名刚被访问过,需要延时
time.sleep(sleep_secs)
# 更新上次访问时间
self.domains[domain] = datetime.datetime.now()避免爬虫死循环
通过添加一个参数记录当前网页经历过了多少个链接 – 深度。当达到最大深度时,爬虫就不再向链接队列中添加网页中的链接了。修改linkCrawler中的seen变量,修改为一个字典类型,增加页面深度的记录。
def linkCrawler(seed_url, link_regex=None, max_depth= 2, ...):
crawl_queue = set([seed_url])
# 通过set类型进行去重处理
seen = {seed_url:0}
...
while crawl_queue:
url = crawl_queue.pop()
# 检查url是否可以被采集
if rp.can_fetch(user_agent, url):
throttle.wait(url)
html = ...
depth = seen[url]
if depth != max_depth:
if link_regex:
links.extend(link for link in get_links(html) if re.match(link_regex, link))
for link in links:
link = normalize(seed_url, link)
if link not in seen:
seen[link] = depth + 1
crawl_queue.append(link)
综合以上功能的爬虫
根据以上内容的学习,已经可以大体构建出一个linkCrawler爬虫的架构,大体可分为下载器模块和链接获取模块两个大模块。整合完成的终极版本代码如下:
"""
downloader.py
"""
import urllib.request
import urllib.parse
import urllib.error
def download(url, headers, proxy, numRetries, data=None):
print("正在下载:", url)
request = urllib.request.Request(url, data, headers)
opener = urllib.request.build_opener()
if proxy:
proxyParams = { urllib.parse.urlparse(url).scheme: proxy }
opener.add_handler(urllib.request.ProxyHandler(proxyParams))
try:
response = opener.open(request)
html = response.read()
code = response.code
except urllib.error.URLError as e:
print('下载错误:', e.reason)
html = ''
if hasattr(e, 'code'):
code = e.code
if numRetries > 0 and 500<=code<600:
return download(url, headers, proxy, numRetries - 1, data)
else:
code = None
return html
链接获取模块linkCrawler.py:
import re
import urllib.parse
import urllib.robotparser
from collections import deque
from .Throttle import Throttle
from .downloader import download
def getRobots(url):
"""
Initial robots parser for this domain
:param url:
:return:
"""
rp = urllib.robotparser.RobotFileParser()
rp.set_url(urllib.parse.urljoin(url, '/robots.txt'))
rp.read()
return rp
def normalize(seedUrl, link):
"""
Normalize this URL by removing hash and adding domain
:param seedUrl:
:param link:
:return:
"""
link, _ = urllib.parse.urldefrag(link) # remove hash to avoid duplicates
return urllib.parse.urljoin(seedUrl, link)
def sameDomain(url1, url2):
"""
Return True if both URL's belong to same domain
:param url1:
:param url2:
:return:
"""
return urllib.parse.urlparse(url1).netloc == urllib.parse.urlparse(url2).netloc
def getLinks(html):
"""
Return a list of links from html
:param html:
:return:
"""
webpageRegex = re.compile(',re.IGNORECASE)
return webpageRegex.findall(str(html))
def linkCrawler(seedUrl, linkRegx=None, delay=5, maxDepth=-1, maxUrls=-1, headers=None, userAgent='wswp', proxy=None, numRetries=1):
"""
Crawl from the given seed URL following links matched by linkRegex
:param seedUrl: 起始url
:param linkRegx: 链接匹配的正则表达式
:param delay: 延迟时间
:param maxDepth: 最深的层次
:param maxUrls: 最多的url数量
:param headers: http请求头
:param userAgent: http头中的userAgent选项
:param proxy: 代理地址
:param numRetries: 重新下载次数
:return:
"""
crawlQueue = deque([seedUrl])
seen = { seedUrl:0}
numUrls = 0
rp = getRobots(seedUrl)
throttle = Throttle(delay)
headers = headers or {}
if userAgent:
headers['User-agent'] = userAgent
while crawlQueue:
url = crawlQueue.pop()
if rp.can_fetch(userAgent, url):
throttle.wait(url)
html = download(url, headers, proxy=proxy, numRetries=numRetries)
links = []
depth = seen[url]
if depth != maxDepth:
if linkRegx:
links.extend(link for link in getLinks(html) if re.match(linkRegx, link))
for link in links:
link = normalize(seedUrl, link)
if link not in seen:
seen[link] = depth + 1
if sameDomain(seedUrl, link):
crawlQueue.append(link)
numUrls += 1
if numUrls == maxUrls:
break
else:
print('Blocked by robots.txt') 延时模块Throttle.py:
import time
import datetime
import urllib.parse
class Throttle:
"""
Throttle downloading by sleeping between requests to same domain
"""
def __init__(self, delay):
# Amount of delay between downloads for each domain
self.delay = delay
# timestamp of when a domain was last accessed
self.domain = {}
def wait(self, url):
domain = urllib.parse.urlparse(url).netloc
lastAccessed = self.domain.get(domain)
if self.delay > 0 and lastAccessed is not None:
sleepSec = self.delay - (datetime.datetime.now() - lastAccessed).seconds
if sleepSec > 0:
time.sleep(sleepSec)
self.domain[domain] = datetime.datetime.now()测试代码main.py:
from .linkCrawler import linkCrawler
if __name__ == "__main__":
linkCrawler('http://example.webscraping.com', '.*?/(index/view)', delay=3,numRetries=3,userAgent='BadCrawler')
linkCrawler('http://example.webscraping.com', '.*?/(index/view)', delay=3, numRetries=3, maxDepth=1,userAgent='GoodCrawler')