动手学深度学习笔记|3.2线性回归的从零开始实现(附课后习题答案)
动手学深度学习笔记|3.2线性回归的从零开始实现(附课后习题答案)
- 线性回归的从零开始实现
-
- 生成数据集
- 读取数据集
- 初始化模型参数
- 定义模型
-
- 定义损失函数
- 定义优化算法
- 训练
- 练习
-
- 1. 如果我们将权重初始化为零,会发生什么。算法仍然有效吗?
- 2. 计算二阶导数时可能会遇到什么问题?这些问题可以如何解决?
- 3.为什么在`squared_loss`函数中需要使用`reshape`函数?
- 4.尝试使用不同的学习率,观察损失函数值下降的快慢。
- 5.如果样本个数不能被批量大小整除,`data_iter`函数的行为会有什么变化?
来源: myluster的github笔记,求个star说是
线性回归的从零开始实现
import random
import torch
import matplotlib.pyplot as plt
import numpy as np
生成数据集
def synthetic_data(w,b,num_examples):#@save
#有@save标记的函数是以后课程也需要的函数
#num_examples是需要生成的数据量
X=torch.normal(0,1,(num_examples,len(w)))#随机生成X值
y=torch.matmul(X,w)+b#点乘
y+=torch.normal(0,0.01,y.shape)#加入噪声
return X,y.reshape(-1,1)#y原本为1D向量,需要配合X转换为2D向量
- X 的形状是 (num_examples, len(w))。
- w 的形状是 (len(w),)。
- torch.matmul(X, w) 的结果是一个 1D 张量(向量),形状为 (num_examples,)。
- 加上标量 b 后,y 的形状仍然是 (num_examples,)
true_w=torch.tensor([2,-3.4])
true_b=4.2
features,labels=synthetic_data(true_w,true_b,1000)
print('features:', features[0],'\nlabel:', labels[0])
features: tensor([-1.6631, 0.7055])
label: tensor([-1.5150])
- 生成features与labels的散点图可以直观的观察到两者之间的线性关系
for i in range(features.shape[1]):
plt.figure(figsize=(4, 6))
plt.scatter(features[:,i].detach().numpy(),labels.detach().numpy(),1)
plt.show()

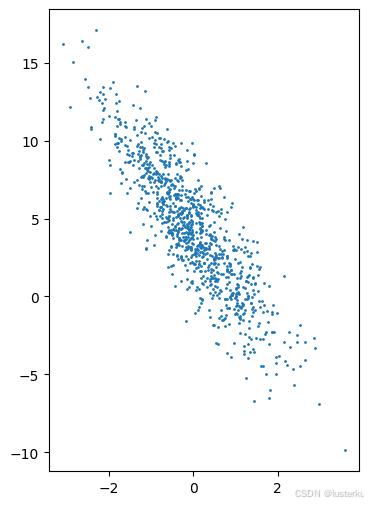
- 注意最后使用的detach()方法,用于将张量从计算图中分离,对这个张量执行的任何操作都不会影响梯度计算,可以节省内存和计算资源
读取数据集
def data_iter(batch_size,features,labels):
num_examples=len(features)
indices=list(range(num_examples))#建立索引表
random.shuffle(indices)#随机打乱索引表
for i in range(0,num_examples,batch_size):
batch_indices=torch.tensor(indices[i:min(i+batch_size,num_examples)])
yield features[batch_indices],labels[batch_indices]#用yield返回生成器对象
#使用yield 语句,这个函数并不会一次性返回所有数据,而是每次迭代时返回一个批次,直到遍历完所有的数据。
- 这样我们生成了多个相同大小的小批量
就可以利用用GPU并行运算的优势,处理合理大小的“小批量”。每个样本都可以并行地进行模型计算,且每个样本损失函数的梯度也可以被并行计算。GPU可以在处理几百个样本时,所花费的时间不比处理一个样本时多太多。 - 下面读取第一个小批量数据感受一下
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
break
tensor([[ 0.5498, -0.6602],
[ 1.3274, 1.1237],
[-0.8969, 1.4953],
[-0.8194, -1.4068],
[-1.8279, 0.2056],
[ 0.2234, 0.7288],
[ 0.2975, 1.2387],
[ 2.7754, -0.0386],
[-0.8039, 0.2879],
[-0.3941, -1.8162]])
tensor([[ 7.5530],
[ 3.0335],
[-2.6649],
[ 7.3398],
[-0.1459],
[ 2.1679],
[ 0.5731],
[ 9.8660],
[ 1.6141],
[ 9.5823]])
初始化模型参数
#随机选择
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)##requires_grad=True代表开启了对该张量的梯度计算
b = torch.zeros(1, requires_grad=True)
- 在初始化参数之后,我们的任务是更新这些参数,直到这些参数足够拟合我们的数据。
-每次更新都需要计算损失函数关于模型参数的梯度。
-有了这个梯度,我们就可以向减小损失的方向更新每个参数。
定义模型
def linreg(X, w, b): #@save
"""线性回归模型"""
return torch.matmul(X, w) + b
定义损失函数
def squared_loss(y_hat, y): #@save
"""均方损失"""
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
定义优化算法
def sgd(params, lr, batch_size): #@save
"""小批量随机梯度下降"""
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
训练
#超参数
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X和y的小批量损失
# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,
# 并以此计算关于[w,b]的梯度
l.sum().backward()##计算梯度
sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
print(f'w的估计误差: {true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差: {true_b - b}')
epoch 1, loss 0.030949
epoch 2, loss 0.000105
epoch 3, loss 0.000050
w的估计误差: tensor([ 4.3511e-05, -7.3910e-05], grad_fn=)
b的估计误差: tensor([0.0004], grad_fn=)
练习
1. 如果我们将权重初始化为零,会发生什么。算法仍然有效吗?
-无事发生,算法仍然有效
2. 计算二阶导数时可能会遇到什么问题?这些问题可以如何解决?
-可能遇到的问题:
- 【1】二阶导数涉及到梯度的梯度(即 Hessian 矩阵),计算复杂度高,尤其是在高维情况下,计算量会平方增长
- 【2】内存占用大:存储 Hessian 矩阵需要大量内存,对于大型模型可能难以承受。
- 【3】数值不稳定性:二阶导数计算可能会引入数值误差,导致不稳定的梯度更新
- 解决办法:
- 使用各种优化方法
3.为什么在squared_loss函数中需要使用reshape函数?
- 确保兼容的形状(Shape):
- 在计算损失时,需要确保预测值和真实值的形状一致,才能进行元素级的减法和平方运算。
有时,预测值和真实值可能因为维度或形状的原因,无法直接进行计算。
- 在计算损失时,需要确保预测值和真实值的形状一致,才能进行元素级的减法和平方运算。
- 避免广播(Broadcasting)错误:
- 如果两个张量的形状不匹配,可能会触发广播机制,导致计算结果与预期不符。
4.尝试使用不同的学习率,观察损失函数值下降的快慢。
- 学习率较大时:
- 初始下降可能较快,但可能会在最小值附近来回震荡,无法很好地收敛。
- 有时可能会导致损失函数发散,训练失败。
- 学习率适中时:
- 损失函数平稳下降,逐步收敛到较小的值。
- 这是理想的学习率选择。
- 学习率较小时:
- 损失函数下降缓慢,训练时间较长。
- 可能需要更多的训练轮数才能达到同样的效果
5.如果样本个数不能被批量大小整除,data_iter函数的行为会有什么变化?
- 由于batch_indices=torch.tensor(indices[i:min(i+batch_size,num_examples)])
所以会在最后一个批次返回一个小于批量大小的批次,包含剩余的所有样本
如果有用求个star说是:myluster的github笔记